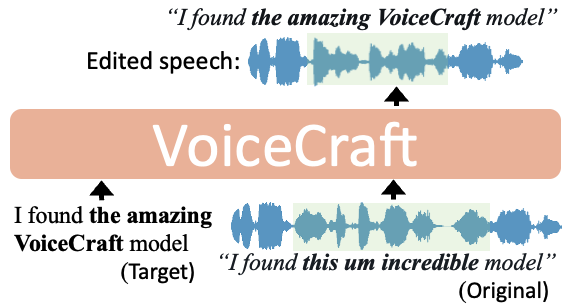
cjwbw/voicecraft
Zero-Shot Speech Editing and Text-to-Speech in the Wild

cjwbw/parler-tts
lightweight text-to-speech (TTS) model, trained on 10.5K hours of audio data

cjwbw/pixart-sigma
Weak-to-Strong Training of Diffusion Transformer for 4K Text-to-Image Generation

cjwbw/aniportrait-audio2vid
Audio-Driven Synthesis of Photorealistic Portrait Animations

cjwbw/animagine-xl-3.1
Anime-themed text-to-image stable diffusion model

cjwbw/starcoder2-15b
Language Models for Code

cjwbw/tcs-sdxl-lora
Trajectory Consistency Distillation
cjwbw/melotts
High-quality multilingual text-to-speech library
cjwbw/opencodeinterpreter-ds-6.7b
OpenCodeInterpreter: Integrating Code Generation with Execution and Refinement

cjwbw/supir-v0f
Practicing Model Scaling for Photo-Realistic Image Restoration In the Wild. This is the SUPIR-v0F model and does NOT use LLaVA-13b.

cjwbw/supir-v0q
Practicing Model Scaling for Photo-Realistic Image Restoration In the Wild. This is the SUPIR-v0Q model and does NOT use LLaVA-13b.

cjwbw/supir
Practicing Model Scaling for Photo-Realistic Image Restoration In the Wild. This version uses LLaVA-13b for captioning.

cjwbw/uform-gen2-qwen-500m
Pocket-Sized Multimodal AI For Content Understanding and Generation
cjwbw/canary-1b
Nvidia Automatic speech-to-text recognition (ASR) in 4 languages (English, German, French, Spanish)

cjwbw/lambda-eclipse
λ-ECLIPSE: Multi-Concept Personalized Text-to-Image Diffusion Models by Leveraging CLIP Latent Space

cjwbw/blipdiffusion
Pre-trained Subject Representation for Controllable Text-to-Image Generation and Editing

cjwbw/blipdiffusion-controlnet
Pre-trained Subject Representation for Controllable Text-to-Image Generation and Editing with ControlNet

cjwbw/rmgb
Background removal model developed by BRIA.AI, trained on a carefully selected dataset and is available as an open-source model for non-commercial use.
cjwbw/cogagent-chat
A Visual Language Model for GUI Agents

cjwbw/videocrafter
VideoCrafter2: Text-to-Video and Image-to-Video Generation and Editing

cjwbw/depth-anything
Highly practical solution for robust monocular depth estimation by training on a combination of 1.5M labeled images and 62M+ unlabeled images

cjwbw/tokenflow
Consistent Diffusion Features for Consistent Video Editing

cjwbw/video-retalking
Audio-based Lip Synchronization for Talking Head Video

cjwbw/diffmorpher
Diffusion Models for Image Morphing
cjwbw/dreamtalk
RESEARCH/NON-COMMERCIAL USE ONLY: diffusion-based audio-driven expressive talking head generation
cjwbw/openvoice
NON-COMMERCIAL USE ONLY: Versatile Instant Voice Cloning

cjwbw/faster-diffusion
Rethinking the Role of UNet Encoder in Diffusion Models
cjwbw/magicoder
LLMs with open-source code snippets for generating low-bias and high-quality instruction data for code.

cjwbw/segmind-vega
Open-source Distilled Stable Diffusion 100% speedup

cjwbw/segmind-vegart
Fast Segmind-Vega with 2-8 inference steps.

cjwbw/cogvlm
powerful open-source visual language model
cjwbw/kandinskyvideo
text-to-video generation model

cjwbw/lavie
High-Quality Video Generation with Cascaded Latent Diffusion Models
cjwbw/gorilla
Gorilla: Large Language Model Connected with Massive APIs
cjwbw/distil-whisper
Distilled version of Whisper

cjwbw/cutie
Video Object Segmentation, combined with SAM and ProPainter
cjwbw/audiosep
Separate Anything You Describe

cjwbw/scalecrafter
Tuning-free Higher-Resolution Visual Generation with Diffusion Models

cjwbw/show-1
Marrying Pixel and Latent Diffusion Models for Text-to-Video Generation

cjwbw/daclip-uir
Controlling Vision-Language Models for Universal Image Restoration

cjwbw/instructcv
Instruction tuned text-to-image diffusion models as vision generalists
.png)
cjwbw/internlm-xcomposer
Advanced text-image comprehension and composition based on InternLM

cjwbw/wuerstchen
Efficient Pretraining of Text-to-Image Models
cjwbw/seamless_communication
SeamlessM4T—Massively Multilingual & Multimodal Machine Translation

cjwbw/unival
Unified Model for Image, Video, Audio and Language Tasks
cjwbw/lorahub
Efficient Cross-Task Generalization via Dynamic LoRA Composition

cjwbw/resshift
Efficient Diffusion Model for Image Super-resolution by Residual Shifting

cjwbw/ledits
Real Image Editing with DDPM Inversion and Semantic Guidance

cjwbw/kandinsky-2-2-controlnet-depth
Kandinsky Image Generation with ControlNet Conditioning

cjwbw/demucs
Demucs Music Source Separation

cjwbw/diffedit-stable-diffusion
Diffusion-based semantic image editing with mask guidance

cjwbw/textdiffuser
Diffusion Models as Text Painters

cjwbw/prompt-free-diffusion
Prompt-free Diffusion
cjwbw/controlvideo
Training-free Controllable Text-to-Video Generation

cjwbw/shap-e
Generating Conditional 3D Implicit Functions

cjwbw/fastcomposer
Tuning-Free Multi-Subject Image Generation with Localized Attention
cjwbw/sadtalker
Stylized Audio-Driven Single Image Talking Face Animation

cjwbw/semantic-segment-anything
Adding semantic labels for segment anything
cjwbw/text2video-zero
Text-to-Image Diffusion Models are Zero-Shot Video Generators
cjwbw/pix2struct
Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding
cjwbw/dolly
Fine-tuned GPT-J 6B model on the Alpaca dataset

cjwbw/stable-diffusion-2-1-unclip
Stable Diffusion v2-1-unclip Model
cjwbw/damo-text-to-video
Multi-stage text-to-video generation

cjwbw/unidiffuser
One Transformer Fits All Distributions in Multi-Modal Diffusion at Scale

cjwbw/dreamshaper
Dream Shaper stable diffusion

cjwbw/zoedepth
ZoeDepth: Combining relative and metric depth

cjwbw/hasdx
mixed stable diffusion model

cjwbw/supermarionation
Finetuned Stable-diffusion from Gerry Anderson Supermarionation

cjwbw/pastel-mix
high-quality highly detailed anime stylized latent diffusion model

cjwbw/real-esrgan
Real-ESRGAN: Real-World Blind Super-Resolution

cjwbw/t2i-adapter
Learning Adapters towards Controllable for Text-to-Image Diffusion Models

cjwbw/midas
Robust Monocular Depth Estimation

cjwbw/hard-prompts-made-easy
Gradient-Based Discrete Optimization for Prompt Tuning and Discovery

cjwbw/pix2pix-zero
Zero-shot Image-to-Image Translation

cjwbw/dreambooth-avatar
Dreambooth finetuning of Stable Diffusion (v1.5.1) on Avatar art style by Lambda Labs

cjwbw/gta5_artwork_diffusion
GTA5 Artwork Diffusion via Dreambooth

cjwbw/magifactory-t-shirt-diffusion
Generate t-shirt logos with stable-dfffusion
cjwbw/distilgpt2-stable-diffusion-v2
Descriptive stable diffusion prompts generation using GPT2

cjwbw/portraitplus
Portraits with stable-diffusion

cjwbw/anything-v4.0
high-quality, highly detailed anime-style Stable Diffusion models

cjwbw/point-e
Point-E: A System for Generating 3D Point Clouds from Complex Prompts

cjwbw/anything-v3-better-vae
high-quality, highly detailed anime style stable-diffusion with better VAE

cjwbw/future-diffusion
Finte-tuned Stable Diffusion on high quality 3D images with a futuristic Sci-Fi theme

cjwbw/karlo
Text-conditional image generation model based on OpenAI's unCLIP

cjwbw/analog-diffusion
a dreambooth model trained on a diverse set of analog photographs

cjwbw/taiyi-stable-diffusion-1b-chinese-v0.1
Chinese Stable diffusion model

cjwbw/eimis_anime_diffusion
stable-diffusion models for high quality and detailed anime images

cjwbw/anything-v3.0
high-quality, highly detailed anime style stable-diffusion
cjwbw/whisper
with large-v2 checkpoint

cjwbw/stable-diffusion-img2img-v2.1

cjwbw/wavyfusion
dreambooth trained on a very diverse dataset ranging from photographs to paintings

cjwbw/altdiffusion-m9
Multilingual Stable Diffusion

cjwbw/stable-diffusion-v2
sd-v2 with diffusers, test version!

cjwbw/stable-diffusion-v2-inpainting
stable-diffusion-v2-inpainting

cjwbw/rembg
Remove images background

cjwbw/app_icons_generator
App Icons Generator V1 (DreamBooth Model)

cjwbw/aesthetic-predictor
A linear estimator on top of clip to predict the aesthetic quality of pictures

cjwbw/backgroundmatting
Real-Time High-Resolution Background Matting

cjwbw/sd_pixelart_spritesheet_generator
generate pixel art sprite sheets from four different angles with Stable-diffusion

cjwbw/disco-diffusion-style
Disco Diffusion style on Stable Diffusion via Dreambooth

cjwbw/dreambooth-pikachu
Pikachu on Stable Diffusion via Dreambooth

cjwbw/herge-style
herge_style on Stable Diffusion via Dreambooth

cjwbw/van-gogh-diffusion
Van Gough on Stable Diffusion via Dreambooth

cjwbw/elden-ring-diffusion
fine-tuned Stable Diffusion model trained on the game art from Elden Ring

cjwbw/prompt-to-prompt
Prompt-to-prompt image editing with cross-attention control

cjwbw/stable-diffusion-v1-5
stable-diffusion with v1-5 checkpoint

cjwbw/stable-diffusion-aesthetic-gradients
Stable Diffusion with Aesthetic Gradients

cjwbw/waifu-diffusion
Stable Diffusion on Danbooru images

cjwbw/stable-diffusion
stable-diffusion with negative prompts, more scheduler
cjwbw/whisper-downloadable-subtitles
Added downloadable subtitles for openai/whisper

cjwbw/rudalle-sr
Real-ESRGAN super-resolution model from ruDALL-E

cjwbw/stable-diffusion-high-resolution
Detailed, higher-resolution images from Stable Diffusion

cjwbw/clip-vit-large-patch14
openai/clip-vit-large-patch14 with Transformers

cjwbw/sd-textual-inversion-ugly-sonic
stable-diffusion-textual-inversion fine-tuned with ugly sonic

cjwbw/sd-textual-inversion-spyro-dragon
stable-diffusion-textual-inversion fine-tuned with spyro of the dragon STYLE

cjwbw/sd-textual-inversion
Stable Diffusion Textual Inversion

cjwbw/docentr
End-to-End Document Image Enhancement Transformer

cjwbw/style-your-hair
Pose-Invariant Hairstyle Transfer

cjwbw/repaint
Inpainting using Denoising Diffusion Probabilistic Models

cjwbw/night-enhancement
Unsupervised Night Image Enhancement

cjwbw/latent-diffusion-text2img
text-to-image with latent diffusion

cjwbw/openpsg
Panoptic Scene Graph Generation

cjwbw/mindall-e
text-to-image generation

cjwbw/vq-diffusion
VQ-Diffusion for Text-to-Image Synthesis

cjwbw/compositional-vsual-generation-with-composable-diffusion-models-pytorch
Composable Diffusion

cjwbw/micromotion-stylegan
Decoding Micromotion in Low-dimensional Latent Spaces from StyleGAN

cjwbw/clip-gen
Language-Free Training of a Text-to-Image Generator with CLIP

cjwbw/bigcolor
Colorization using a Generative Color Prior for Natural Images
cjwbw/global_tracking_transformers
Global Tracking Transformers

cjwbw/vqfr
Blind Face Restoration with Vector-Quantized Dictionary and Parallel Decoder

cjwbw/diffae
Image Manipulatinon with Diffusion Autoencoders

cjwbw/face-align-cog
face alignment using stylegan-encoding

cjwbw/clip-guided-diffusion
Clip-Guided Diffusion Model for Image Generation

cjwbw/clip-guided-diffusion-pokemon
Generates pokemon sprites from prompt
cjwbw/pix2seq
Turning RGB pixels into semantically meaningful sequences
cjwbw/videocrafter2
cjwbw/chronos

cjwbw/c4ai-command-r-v01
CohereForAI c4ai-command-r-v01, Quantized model through bitsandbytes, 8-bit precision
cjwbw/minigpt-5
cjwbw/starcoder2

cjwbw/tron-legacy-diffusion
Tron Legacy Diffusion on Stable Diffusion via Dreambooth
cjwbw/multilingual-stable-diffusion

cjwbw/sd-x2-latent-upscaler
Stable Diffusion x2 latent upscaler
cjwbw/oneformer
One Transformer to Rule Universal Image Segmentation
cjwbw/ddnm
Zero Shot Image Restoration Using Denoising Diffusion Null-Space Model
cjwbw/chatglm-6b
bilingual language model based on General Language Model (GLM) framework
.png)
cjwbw/idefics
Open-access reproduction of large visual language model Flamingo
cjwbw/transfer-anything
cjwbw/pixart-dmd
cjwbw/maskgit
Masked Generative Image Transformer
cjwbw/rpg-diffusionmaster

cjwbw/styledrop
Text-to-Image Generation in Any Style