Readme
Model description
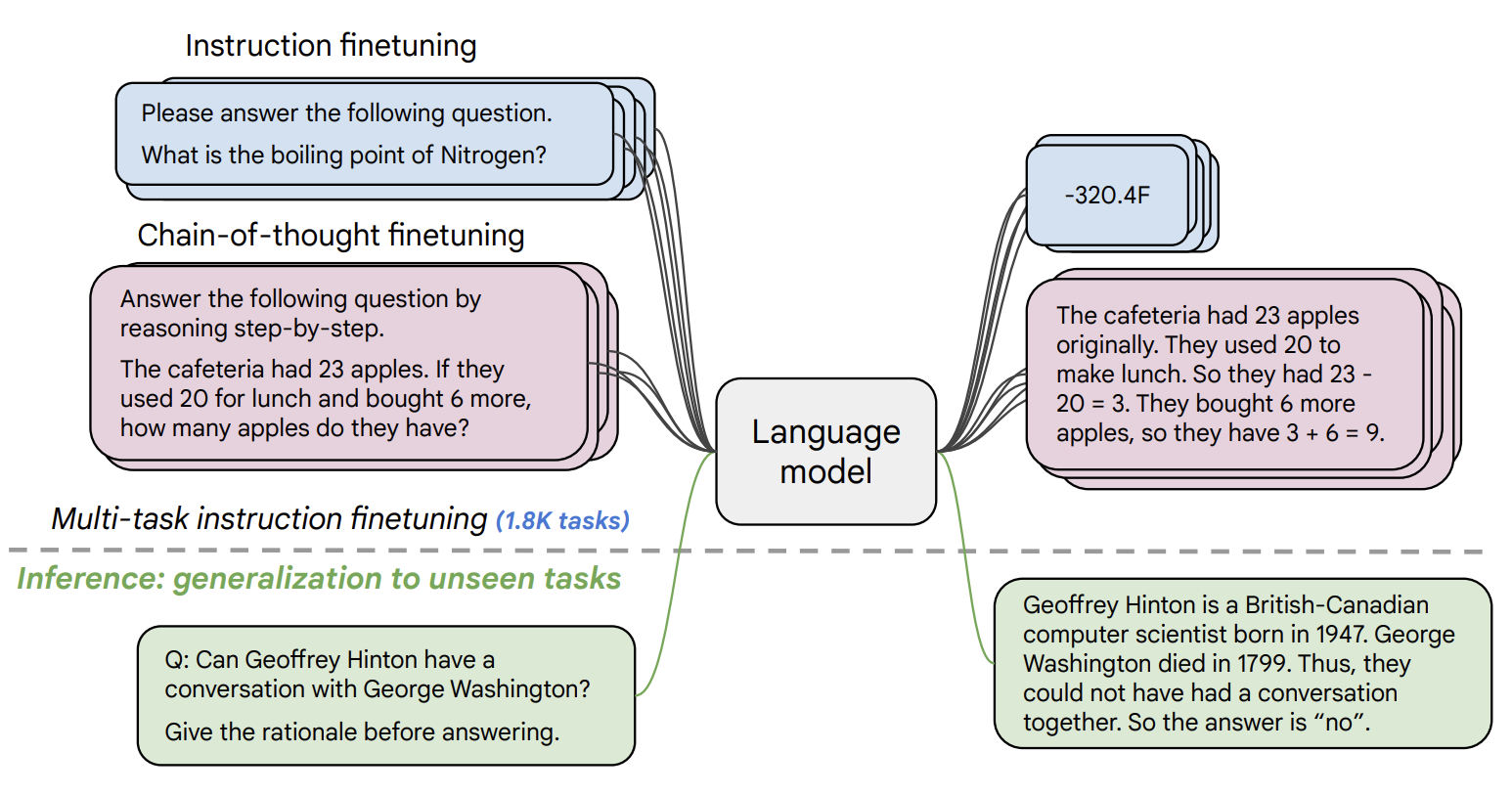
FLAN-T5 is a family of large language models trained at Google, finetuned on a collection of datasets phrased as instructions. It has strong zero-shot, few-shot, and chain of thought abilities. Because of these abilities, FLAN-T5 is useful for a wide array of natural language tasks. This model is FLAN-T5-Small, the 80M parameter version of FLAN-T5. To learn more about FLAN-T5, read the FLAN paper here.
Usage
FLAN-T5 is capable of various natural language tasks. Some of these include question answering, classification, summarization and translation, among others. Here are some examples of this, summarized here and linked for information about the parameters used.
Prompt: Answer the following yes/no question by reasoning step by step. Can a dog drive a car?
Output: Dogs do not have a drivers license nor can they operate a car. Therefore, the final answer is no.
Sentiment Analysis/Classification:
Prompt:
Here are some phrases and sentiments.
I love this spaghetti: Positive
The air outside is great: Positive
You hated the cat in the hat: Negative
They are in a foul mood: Negative
The dinner was horrible:
Output: Negative
Caveats and Limitations
The information below is copied from the model’s official model card:
Language models, including Flan-T5, can potentially be used for language generation in a harmful way, according to Rae et al. (2021). Flan-T5 should not be used directly in any application, without a prior assessment of safety and fairness concerns specific to the application.
Flan-T5 is fine-tuned on a large corpus of text data that was not filtered for explicit content or assessed for existing biases. As a result the model itself is potentially vulnerable to generating equivalently inappropriate content or replicating inherent biases in the underlying data.
Citation
@misc{https://doi.org/10.48550/arxiv.2210.11416,
doi = {10.48550/ARXIV.2210.11416},
url = {https://arxiv.org/abs/2210.11416},
author = {Chung, Hyung Won and Hou, Le and Longpre, Shayne and Zoph, Barret and Tay, Yi and Fedus, William and Li, Yunxuan and Wang, Xuezhi and Dehghani, Mostafa and Brahma, Siddhartha and Webson, Albert and Gu, Shixiang Shane and Dai, Zhuyun and Suzgun, Mirac and Chen, Xinyun and Chowdhery, Aakanksha and Castro-Ros, Alex and Pellat, Marie and Robinson, Kevin and Valter, Dasha and Narang, Sharan and Mishra, Gaurav and Yu, Adams and Zhao, Vincent and Huang, Yanping and Dai, Andrew and Yu, Hongkun and Petrov, Slav and Chi, Ed H. and Dean, Jeff and Devlin, Jacob and Roberts, Adam and Zhou, Denny and Le, Quoc V. and Wei, Jason},
keywords = {Machine Learning (cs.LG), Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Scaling Instruction-Finetuned Language Models},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}