
StoryDALL-E: Adapting Pretrained Text-to-Image Transformers for Story Continuation
Adyasha Maharana, Darryl Hannan and Mohit Bansal (UNC Chapel Hill)
Published at ECCV 2022
StoryDALL-E [1] is a model trained for the task of Story Visualization [2].
The model receives a sequence of captions as input and generates a corresponding sequence of images which form a visual story depicting the narrative in the captions. We modify this task to enable the model to receive an initial scene as input, which can be used as a cue for the setting of the story and also for generating unseen or low-resource visual elements. We refer to this task as Story Continuation [1]. StoryDALL-E is based on the dalle model.
This model has been developed for academic purposes only.
[Paper] [Code] [Model Card]
Dataset
This model has been trained using the Pororo story visualization dataset [1]. The data was adapted from the popular cartoon series Pororo the Little Penguin and originally released by [2].
The Pororo dataset contains 9 recurring characters, as shown below, in the decreasing order of their frequency in the training data.

The training dataset contains nearly 10,000 samples in the training set. Most of the scenes occur in a snowy village, surrounded by hills, trees and houses. A few episodes are located in gardens or water bodies. All the captions are in the English language and predominantly contain verbs in the present tense. Additionally, the training of this model starts from the pretrained checkpoint of mega-dalle, which is trained on the Conceptual Captions dataset.
Intended Use
This model is intended for generating visual stories containing the 9 characters in the Pororo dataset. This version of the StoryDALL-E model is reasonable at the following scenarios: * Frames containing a single character. * Overtly visual actions such as making cookies, walking, reading a book, sitting. * Scenes taking place in snowy settings, indoors and gardens. * Visual stories contaning 1-3 characters across all frames. * Scene transitions e.g. from day to night. * Moderately capable of generating semantic concepts that do not appear in the story continuation dataset, such as doughnut and lion.
Here are some examples of generated visual stories for the above-mentioned settings.
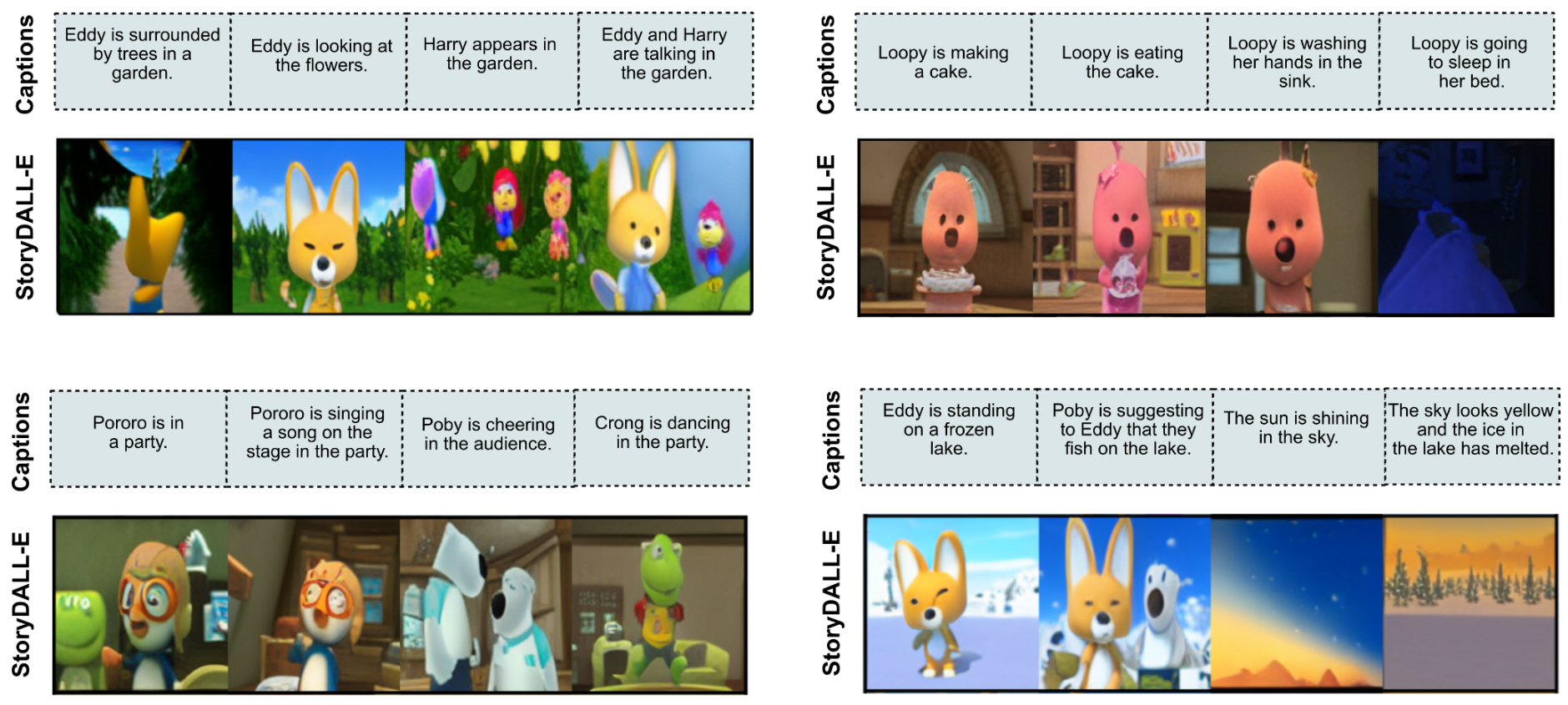
Due to the small training dataset size for story visualization, the model has poor generalization to some unseen settings. The model struggles to generate coherent images in the following scenarios. * Multiple characters in a frame. * Non-visual actions such as compliment. * Characters that are infrequent in the training dataset e.g. Rody, Harry. * Background locations that are not found in the cartoon e.g. a busy city. * Color-based descriptions for object. * Completely new characters based on textual descriptions.
Demo Instructions
- In the demo, four captions can be entered in the
captiontext fields for the visual story. - Select a
sourceframe based on the character that is predominant in your visual story. top_krefers to the number of highest probability vocabulary tokens to keep for top-k-filtering.- Only the most probable tokens with probabilities that add up to
top_por higher are kept for generation. - Set
superconditionto True to enable generation using a null hypothesis. - Select between 1-4
n_candidatesto generate a diverse set of stories for the given captions.
References
[1] Maharana, Adyasha, et al. “StoryDALL-E: Adapting Pretrained Text-to-Image Transformers for Story Continuation.” ECCV. 2022.
[2] Li, Yitong, et al. “Storygan: A sequential conditional gan for story visualization.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019.
[3] Kim, Kyung-Min, et al. “DeepStory: video story QA by deep embedded memory networks.” Proceedings of the 26th International Joint Conference on Artificial Intelligence. 2017.
[4] Sharma, Piyush, et al. “Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning.” Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2018.