
Emu3: Next-Token Prediction is All You Need
This is the demo for image generation. For vision-language understanding, visit: https://replicate.com/chenxwh/emu3-chat
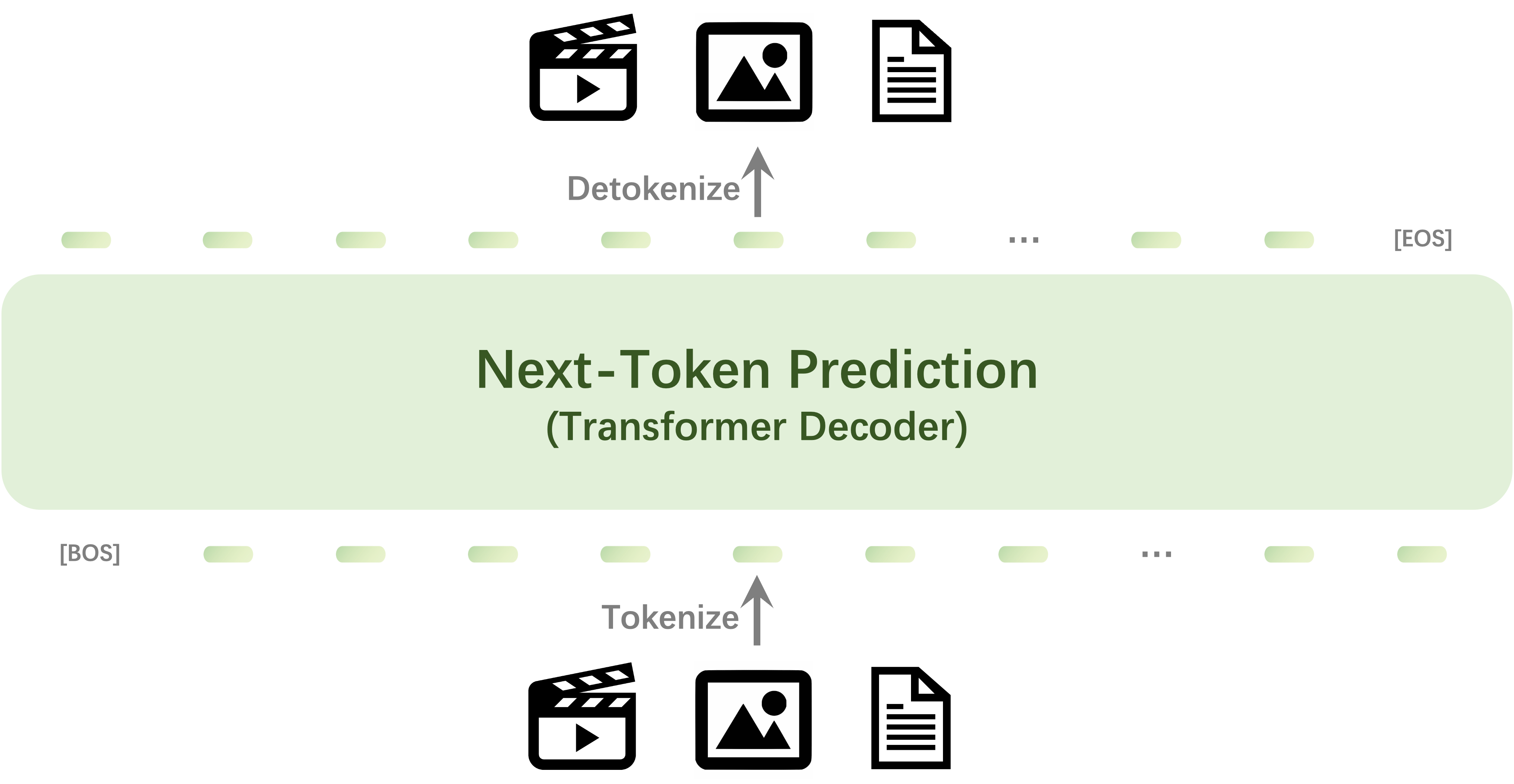
We introduce Emu3, a new suite of state-of-the-art multimodal models trained solely with next-token prediction! By tokenizing images, text, and videos into a discrete space, we train a single transformer from scratch on a mixture of multimodal sequences.
Emu3 excels in both generation and perception
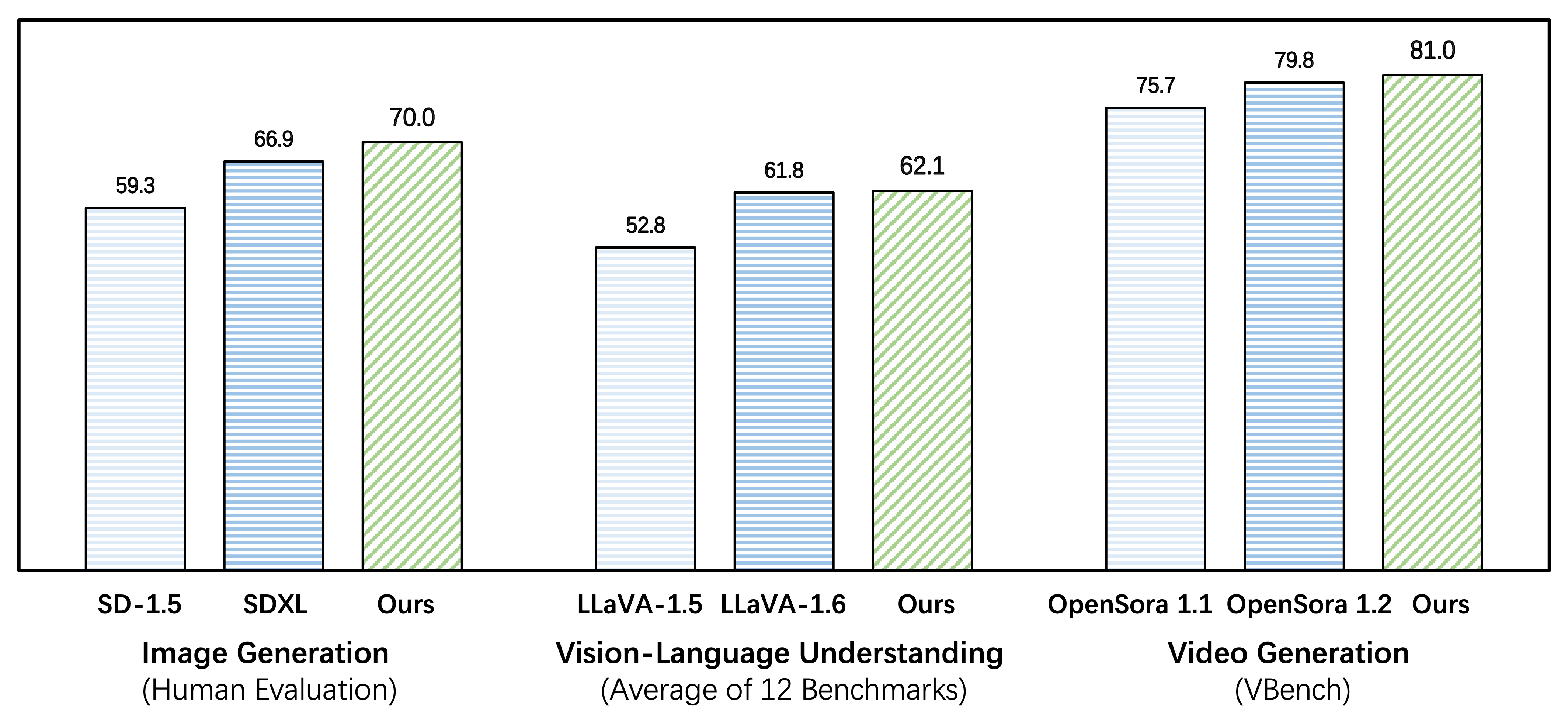
Emu3 outperforms several well-established task-specific models in both generation and perception tasks, surpassing flagship open models such as SDXL, LLaVA-1.6 and OpenSora-1.2, while eliminating the need for diffusion or compositional architectures.
Highlights
- Emu3 is capable of generating high-quality images following the text input, by simply predicting the next vision token. The model naturally supports flexible resolutions and styles.
- Emu3 shows strong vision-language understanding capabilities to see the physical world and provides coherent text responses. Notably, this capability is achieved without depending on a CLIP and a pretrained LLM.
- Emu3 simply generates a video causally by predicting the next token in a video sequence, unlike the video diffusion model as in Sora. With a video in context, Emu3 can also naturally extend the video and predict what will happen next.
Model created