Try FIBO Chat to see how Fibo can generate, inspire, and refine images!

🌍 Why FIBO?
Text-to-image models have mastered imagination - but not control. FIBO changes that.
FIBO is trained on structured JSON captions up to 1,000+ words and designed to understand and control different visual parameters such as lighting, composition, color, and camera settings, enabling precise and reproducible outputs.
With only 8 billion parameters, FIBO provides a new level of image quality, prompt adherence and proffessional control. Enterprises demand repeatability, governance, and transparency. FIBO delivers - open-source, rights-clear, and ready for production.
🔑 Key Features
- LLM guided JSON-native prompting: structured schemas up to 1,000+ words (lighting, camera, composition, DoF)
- Iterative controlled generation: generate images from short prompts or keep refining and get inspiration from detailed JSONs and input images
- Disentangled control: tweak a single attribute (e.g., camera angle) without breaking the scene.
- Enterprise-grade: 100% licensed data; governance, repeatability, and legal clarity.
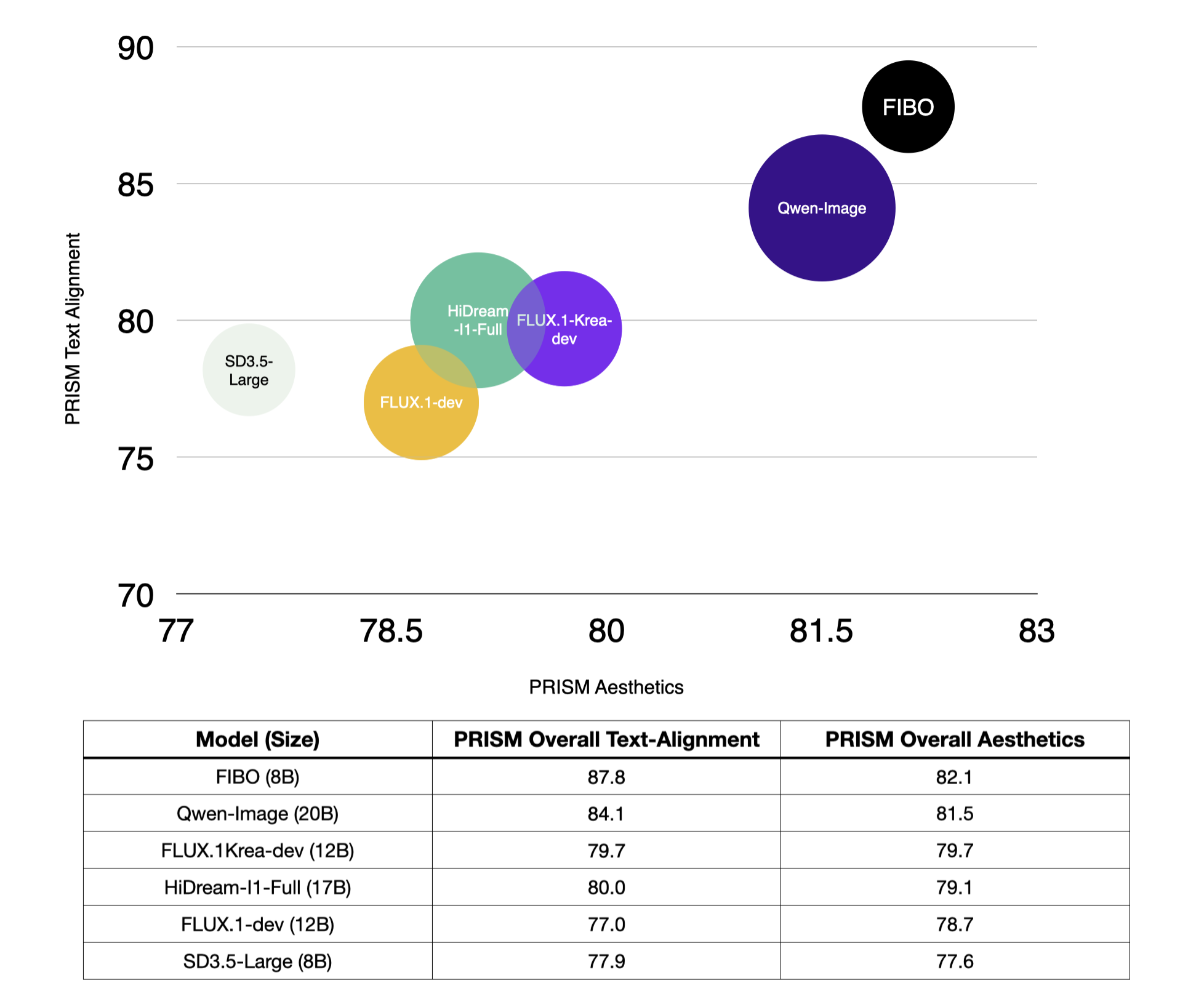
- Wins in both text alignment and aesthetics on PRISM-style evaluations.
💡 What can you do with FIBO?
Generate
Start with a quick idea. FIBO’s language model expands your short prompt into a rich, structured JSON prompt, then generates the image. You get both the image and the expanded prompt.
Refine
Continue from a detailed structured prompt and add a small instruction - for example, “backlit,” “85 mm,” or “warmer skin tones.” FIBO updates only the requested attributes, re-generates the image, and returns the refined prompt alongside it.
Inspire
Provide an image instead of text. FIBO’s vision-language model extracts a detailed prompt describing it, combines that with your creative intent, and generates new, related images - ideal for exploring new directions without altering the original.