
Readme
CogVLM2-Video
Model introduction
We launch a new generation of CogVLM2 series of models and open source two models based on Meta-Llama-3-8B-Instruct. Compared with the previous generation of CogVLM open source models, the CogVLM2 series of open source models have the following improvements:
- Significant improvements in many benchmarks such as
TextVQA,DocVQA. - Support 8K content length.
- Support image resolution up to 1344 * 1344.
- Provide an open source model version that supports both Chinese and English.
Video Understand
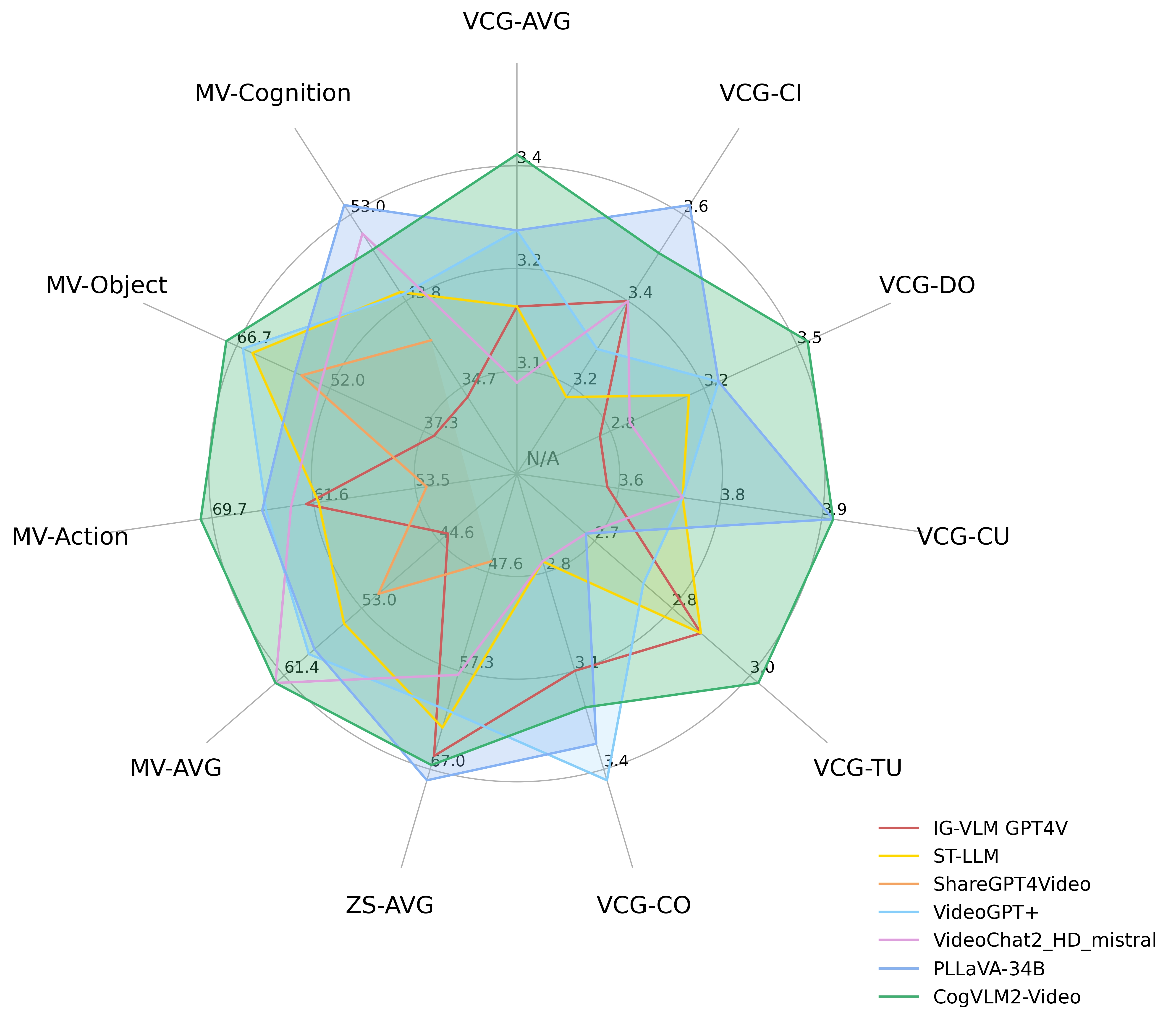
CogVLM2-Video achieves state-of-the-art performance on multiple video question answering tasks. The following diagram shows the performance of CogVLM2-Video on the MVBench, VideoChatGPT-Bench and Zero-shot VideoQA datasets (MSVD-QA, MSRVTT-QA, ActivityNet-QA). Where VCG- refers to the VideoChatGPTBench, ZS- refers to Zero-Shot VideoQA datasets and MV-* refers to main categories in the MVBench.
License
This model is released under the CogVLM2 CogVLM2 LICENSE. For models built with Meta Llama 3, please also adhere to the LLAMA3_LICENSE.
Citation
If you find our work helpful, please consider citing the following papers
@article{hong2024cogvlm2,
title={CogVLM2: Visual Language Models for Image and Video Understanding},
author={Hong, Wenyi and Wang, Weihan and Ding, Ming and Yu, Wenmeng and Lv, Qingsong and Wang, Yan and Cheng, Yean and Huang, Shiyu and Ji, Junhui and Xue, Zhao and others},
journal={arXiv preprint arXiv:2408.16500},
year={2024}
}
@misc{wang2023cogvlm,
title={CogVLM: Visual Expert for Pretrained Language Models},
author={Weihan Wang and Qingsong Lv and Wenmeng Yu and Wenyi Hong and Ji Qi and Yan Wang and Junhui Ji and Zhuoyi Yang and Lei Zhao and Xixuan Song and Jiazheng Xu and Bin Xu and Juanzi Li and Yuxiao Dong and Ming Ding and Jie Tang},
year={2023},
eprint={2311.03079},
archivePrefix={arXiv},
primaryClass={cs.CV}
}