




Readme
![]()
Hunyuan-DiT
A Powerful Multi-Resolution Diffusion Transformer with Fine-Grained Chinese Understanding
This repo contains PyTorch model definitions, pre-trained weights and inference/sampling code for our paper exploring Hunyuan-DiT. You can find more visualizations on our project page.
DialogGen:Multi-modal Interactive Dialogue System for Multi-turn Text-to-Image Generation
Abstract
We present Hunyuan-DiT, a text-to-image diffusion transformer with fine-grained understanding of both English and Chinese. To construct Hunyuan-DiT, we carefully designed the transformer structure, text encoder, and positional encoding. We also build from scratch a whole data pipeline to update and evaluate data for iterative model optimization. For fine-grained language understanding, we train a Multimodal Large Language Model to refine the captions of the images. Finally, Hunyuan-DiT can perform multi-round multi-modal dialogue with users, generating and refining images according to the context. Through our carefully designed holistic human evaluation protocol with more than 50 professional human evaluators, Hunyuan-DiT sets a new state-of-the-art in Chinese-to-image generation compared with other open-source models.
🎉 Hunyuan-DiT Key Features
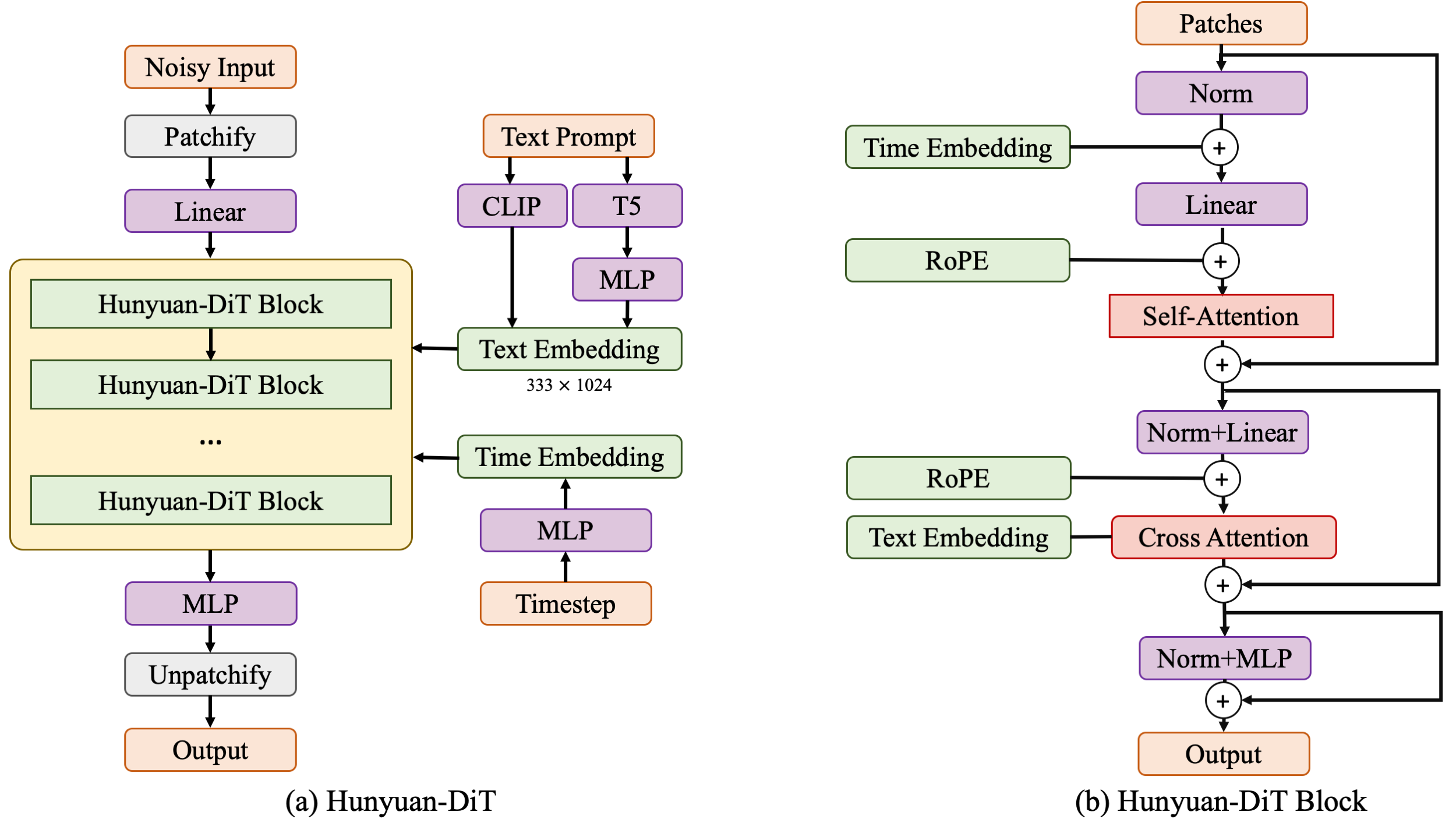
Chinese-English Bilingual DiT Architecture
Hunyuan-DiT is a diffusion model in the latent space, as depicted in figure below. Following the Latent Diffusion Model, we use a pre-trained Variational Autoencoder (VAE) to compress the images into low-dimensional latent spaces and train a diffusion model to learn the data distribution with diffusion models. Our diffusion model is parameterized with a transformer. To encode the text prompts, we leverage a combination of pre-trained bilingual (English and Chinese) CLIP and multilingual T5 encoder.
Multi-turn Text2Image Generation
Understanding natural language instructions and performing multi-turn interaction with users are important for a text-to-image system. It can help build a dynamic and iterative creation process that bring the user’s idea into reality step by step. In this section, we will detail how we empower Hunyuan-DiT with the ability to perform multi-round conversations and image generation. We train MLLM to understand the multi-round user dialogue and output the new text prompt for image generation.

📈 Comparisons
In order to comprehensively compare the generation capabilities of HunyuanDiT and other models, we constructed a 4-dimensional test set, including Text-Image Consistency, Excluding AI Artifacts, Subject Clarity, Aesthetic. More than 50 professional evaluators performs the evaluation.
🔗 BibTeX
If you find Hunyuan-DiT or DialogGen useful for your research and applications, please cite using this BibTeX:
@misc{li2024hunyuandit,
title={Hunyuan-DiT: A Powerful Multi-Resolution Diffusion Transformer with Fine-Grained Chinese Understanding},
author={Zhimin Li and Jianwei Zhang and Qin Lin and Jiangfeng Xiong and Yanxin Long and Xinchi Deng and Yingfang Zhang and Xingchao Liu and Minbin Huang and Zedong Xiao and Dayou Chen and Jiajun He and Jiahao Li and Wenyue Li and Chen Zhang and Rongwei Quan and Jianxiang Lu and Jiabin Huang and Xiaoyan Yuan and Xiaoxiao Zheng and Yixuan Li and Jihong Zhang and Chao Zhang and Meng Chen and Jie Liu and Zheng Fang and Weiyan Wang and Jinbao Xue and Yangyu Tao and Jianchen Zhu and Kai Liu and Sihuan Lin and Yifu Sun and Yun Li and Dongdong Wang and Mingtao Chen and Zhichao Hu and Xiao Xiao and Yan Chen and Yuhong Liu and Wei Liu and Di Wang and Yong Yang and Jie Jiang and Qinglin Lu},
year={2024},
eprint={2405.08748},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
@article{huang2024dialoggen,
title={DialogGen: Multi-modal Interactive Dialogue System for Multi-turn Text-to-Image Generation},
author={Huang, Minbin and Long, Yanxin and Deng, Xinchi and Chu, Ruihang and Xiong, Jiangfeng and Liang, Xiaodan and Cheng, Hong and Lu, Qinglin and Liu, Wei},
journal={arXiv preprint arXiv:2403.08857},
year={2024}
}