
Readme
AniPortrait
AniPortrait: Audio-Driven Synthesis of Photorealistic Portrait Animations
Here we propose AniPortrait, a novel framework for generating high-quality animation driven by audio and a reference portrait image. You can also provide a video to achieve face reenacment.
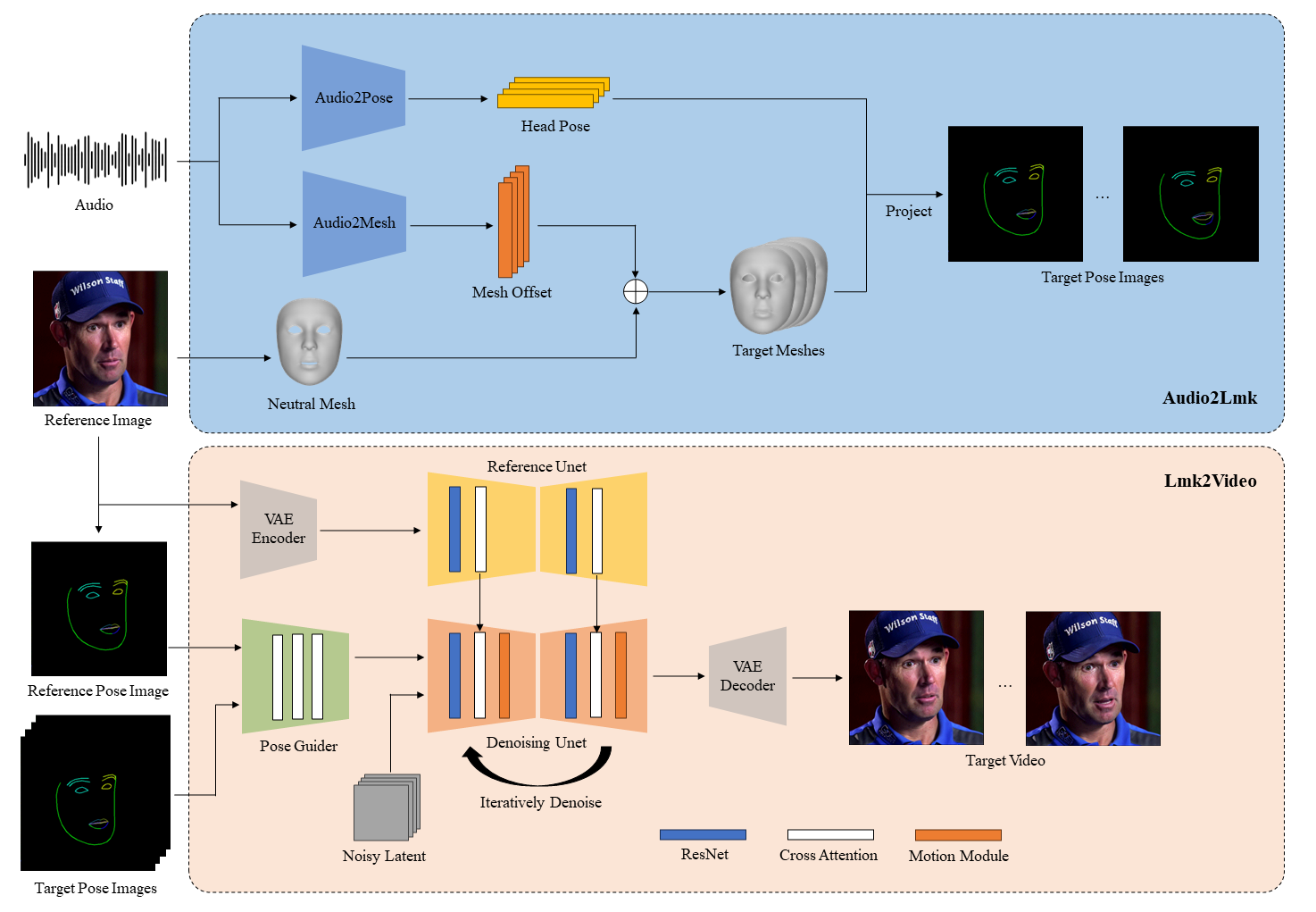
Pipeline
Acknowledgements
We first thank the authors of EMO, and part of the images and audios in our demos are from EMO. Additionally, we would like to thank the contributors to the Moore-AnimateAnyone, majic-animate, animatediff and Open-AnimateAnyone repositories, for their open research and exploration.
Citation
@misc{wei2024aniportrait,
title={AniPortrait: Audio-Driven Synthesis of Photorealistic Portrait Animations},
author={Huawei Wei and Zejun Yang and Zhisheng Wang},
year={2024},
eprint={2403.17694},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
Model created