
This is a cog implementation of https://github.com/gwang-kim/DiffusionCLIP.
DiffusionCLIP: Text-Guided Diffusion Models for Robust Image Manipulation (CVPR 2022)


DiffusionCLIP: Text-Guided Diffusion Models for Robust Image Manipulation
Gwanghyun Kim, Taesung Kwon, Jong Chul Ye
CVPR 2022Abstract:
Recently, GAN inversion methods combined with Contrastive Language-Image Pretraining (CLIP) enables zero-shot image manipulation guided by text prompts. However, their applications to diverse real images are still difficult due to the limited GAN inversion capability. Specifically, these approaches often have difficulties in reconstructing images with novel poses, views, and highly variable contents compared to the training data, altering object identity, or producing unwanted image artifacts. To mitigate these problems and enable faithful manipulation of real images, we propose a novel method, dubbed DiffusionCLIP, that performs text-driven image manipulation using diffusion models. Based on full inversion capability and high-quality image generation power of recent diffusion models, our method performs zero-shot image manipulation successfully even between unseen domains and takes another step towards general application by manipulating images from a widely varying ImageNet dataset. Furthermore, we propose a novel noise combination method that allows straightforward multi-attribute manipulation. Extensive experiments and human evaluation confirmed robust and superior manipulation performance of our methods compared to the existing baselines.
Description
This repo includes the official PyTorch implementation of DiffusionCLIP, Text-Guided Diffusion Models for Robust Image Manipulation. DiffusionCLIP resolves the critical issues in zero-shot manipulation with the following contributions. - We revealed that diffusion model is well suited for image manipulation thanks to its nearly perfect inversion capability, which is an important advantage over GAN-based models and hadn’t been analyzed in depth before our detailed comparison. - Our novel sampling strategies for fine-tuning can preserve perfect reconstruction at increased speed. - In terms of empirical results, our method enables accurate in- and out-of-domain manipulation, minimizes unintended changes, and significantly outperformes SOTA baselines. - Our method takes another step towards general application by manipulating images from a widely varying ImageNet dataset. - Finally, our zero-shot translation between unseen domains and multi-attribute transfer can effectively reduce manual intervention.
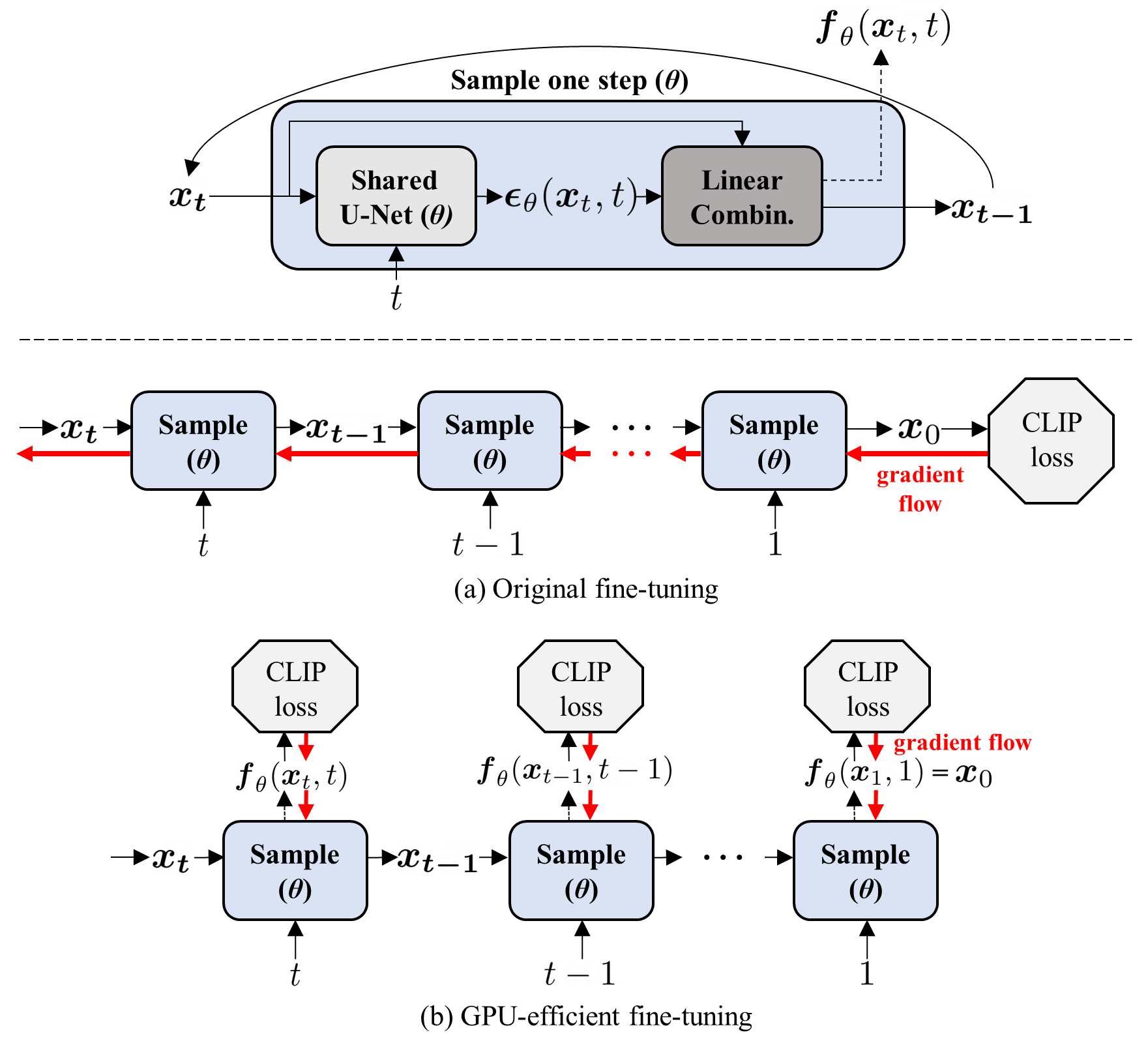
The training process is illustrated in the following figure. Once the diffusion model is fine-tuned, any image from the pretrained domain can be manipulated into the corresponding to the target text without re-training:

We also propose two fine-tuning scheme. Quick original fine-tuning and GPU-efficient fine-tuning. For more details, please refer to Sec. B.1 in Supplementary Material.
Novel Applications
The fine-tuned models through DiffusionCLIP can be leveraged to perform the several novel applications.
Manipulation of Images in Trained Domain & to Unseen Domain

Image Translation from Unseen Domain into Another Unseen Domain

Generation of Images in Unseen Domain from Strokes

Multiple Attribute Changes

Related Works
Usage of guidance by CLIP to manipulate images is motivated by StyleCLIP and StyleGAN-NADA. Image translation from an unseen domain to the trained domain using diffusion models is introduced in SDEdit, ILVR. DDIM sampling and its reveral for generation and inversion of images are introduced by in DDIM, Diffusion Models Beat GANs on Image Synthesis.
Our code strcuture is based on the official codes of SDEdit and StyleGAN-NADA. We used pretrained models from SDEdit and ILVR.
Citation
If you find DiffusionCLIP useful in your research, please consider citing:
@InProceedings{Kim_2022_CVPR,
author = {Kim, Gwanghyun and Kwon, Taesung and Ye, Jong Chul},
title = {DiffusionCLIP: Text-Guided Diffusion Models for Robust Image Manipulation},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {2426-2435}
}
Additional Results
Here, we show more manipulation of real images in the diverse datasets using DiffusionCLIP where the original pretrained models are trained on AFHQ-Dog, LSUN-Bedroom and ImageNet, respectively.