
Readme
Fine-grained Image Captioning with CLIP Reward
- Authors: Jaemin Cho, David Seunghyun Yoon, Ajinkya Kale, Franck Dernoncourt, Trung Bui, Mohit Bansal
- Findings of NAACL 2022 Paper
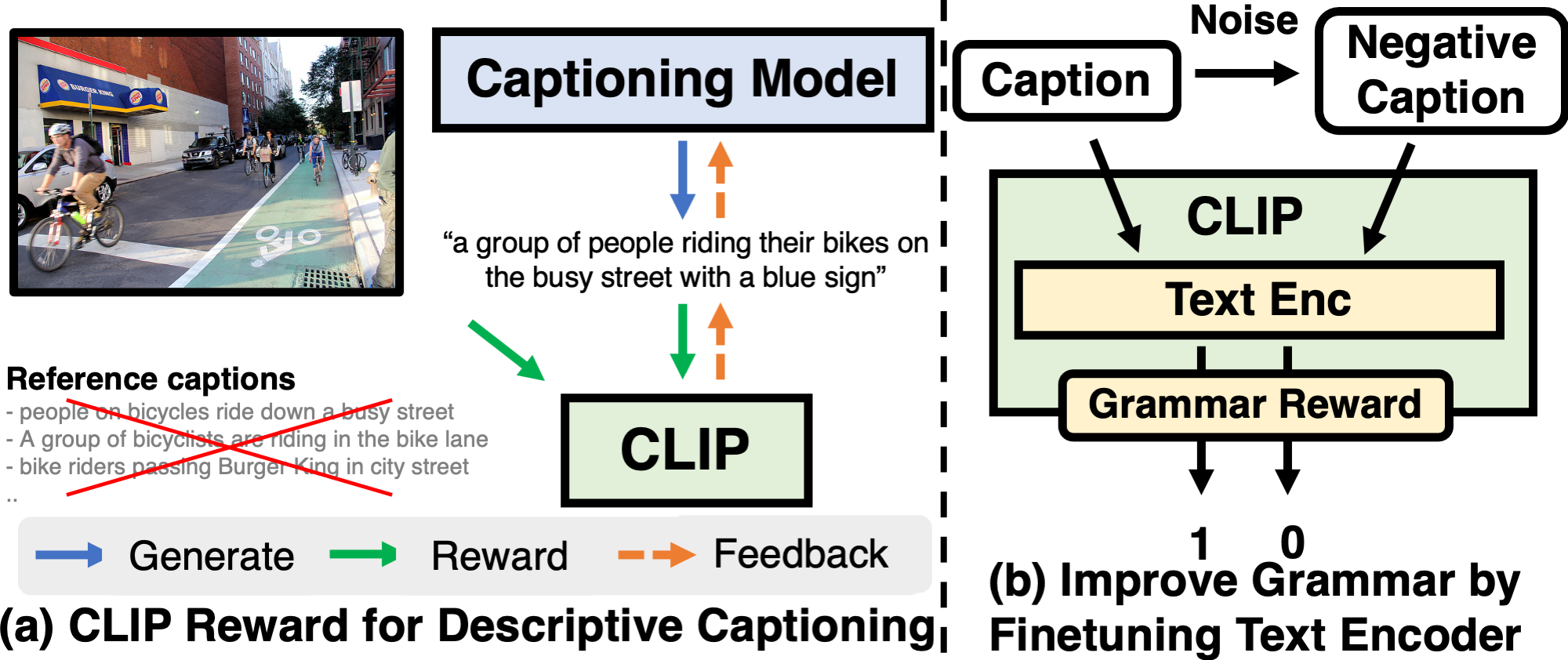
Acknowledgments
We thank the developers of CLIP-ViL, ImageCaptioning.pytorch, CLIP, coco-caption, cider for their public code release.
Reference
Please cite our paper if you use our models in your works:
```bibtex @inproceedings{Cho2022CLIPReward, title = {Fine-grained Image Captioning with CLIP Reward}, author = {Jaemin Cho and Seunghyun Yoon and Ajinkya Kale and Franck Dernoncourt and Trung Bui and Mohit Bansal}, booktitle = {Findings of NAACL}, year = {2022} }
Model created