Readme
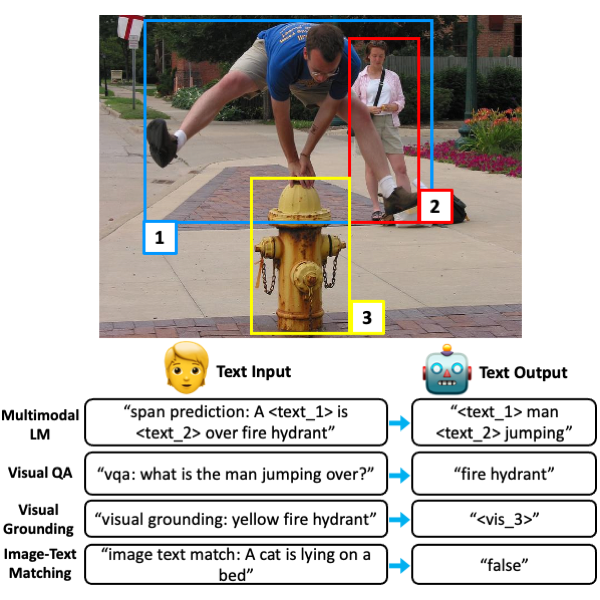
Unifying Vision-and-Language Tasks via Text Generation
- Authors: Jaemin Cho, Jie Lei, Hao Tan, and Mohit Bansal
- Paper (To appear in ICML 2021)
Reference
Please cite our paper if you use our models in your works:
@inproceedings{cho2021vlt5,
title = {Unifying Vision-and-Language Tasks via Text Generation},
author = {Jaemin Cho and Jie Lei and Hao Tan and Mohit Bansal},
booktitle = {ICML},
year = {2021}
}
Model created