
We use LoFTR to match the feature points from two images. LoFTR predicts thousands of dense point correspondences, and it works even in low-texture area. These correspondences are accurate and robust, so they give us good information for image alignment.
The LoFTR model was pre-trained on MegaDepth dataset, which contains large amount of outdoor scene images collected from Internet with depth map annotations. The ground-truth matches are computed by camera poses and depth maps. Since LoFTR is a detector-free model, it does not learn to detect feature points from specific scene. Instead, LoFTR learns how to match the dense features directly, so it can be easily adapted to other domains, even the scene is very different from training datasets. Thus, it achieves good performance in our application.
After upload image pair, model will match their common feature points, and return the matching result with numpy array in res.npy file.
The size of array is (2, N, 2), where the first index represents the image number, the second index represents i-th feature point, and the third index represents the x-y coordinate.
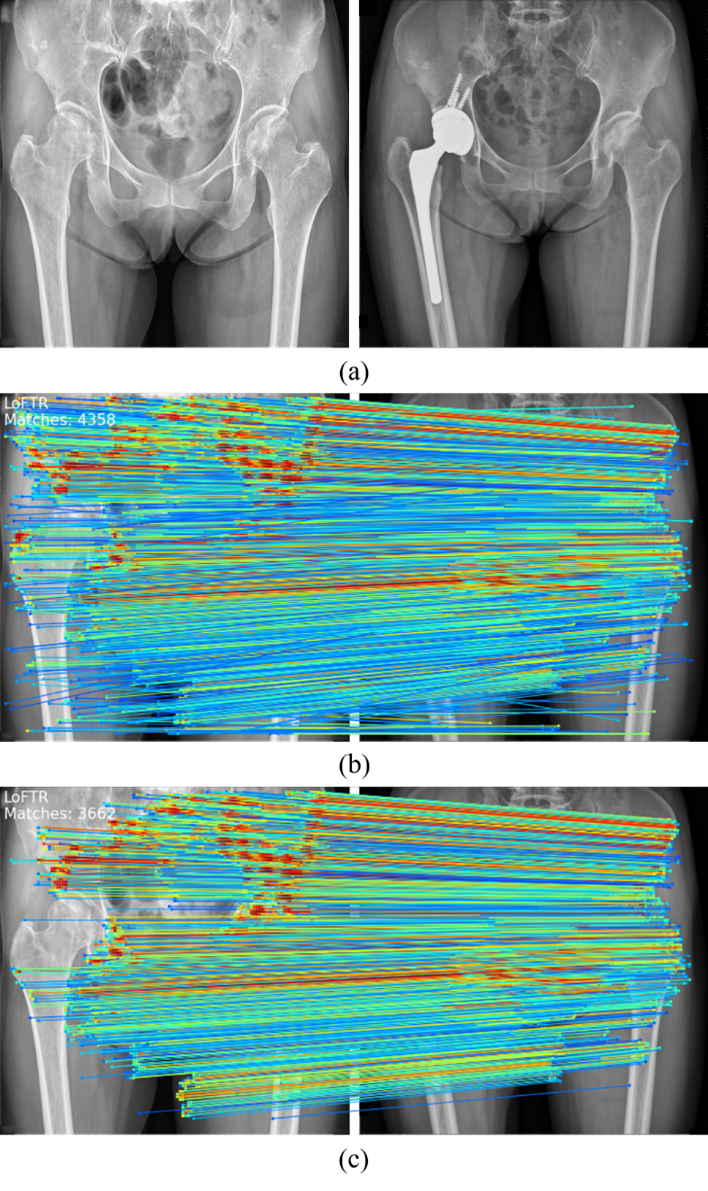 The feature matching results with LoFTR. (a) Original image pair; (b) matching result; (c) Matching result with outlier removal using RANSAC.
The feature matching results with LoFTR. (a) Original image pair; (b) matching result; (c) Matching result with outlier removal using RANSAC.