
camenduru / story-diffusion
StoryDiffusion: Consistent Self-Attention for Long-Range Image and Video Generation

camenduru / comfyui-ipadapter-latentupscale
IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models

camenduru / colorize-line-art
ControlNet Line Art Anime

camenduru / zest
ZeST: Zero-Shot Material Transfer from a Single Image

camenduru / instantmesh
InstantMesh: Efficient 3D Mesh Generation from a Single Image with Sparse-view Large Reconstruction Models

camenduru / zephyr-orpo-141b-a35b-v0.1
Mixtral 8x22b v0.1 Zephyr Orpo 141b A35b v0.1

camenduru / magictime
MagicTime: Time-lapse Video Generation Models as Metamorphic Simulators

camenduru / mixtral-8x22b-v0.1-4bit
Mixtral-8x22b-v0.1-4bit

camenduru / streaming-t2v
StreamingT2V: Consistent, Dynamic, and Extendable Long Video Generation from Text

camenduru / emage
EMAGE: Towards Unified Holistic Co-Speech Gesture Generation via Expressive Masked Audio Gesture Modeling
camenduru / minigpt4-video
MiniGPT4-Video: Advancing Multimodal LLMs for Video Understanding with Interleaved Visual-Textual Tokens

camenduru / open-sora-plan-512x512
Open Sora Plan Text To Video

camenduru / attribute-control
Continuous, Subject-Specific Attribute Control in T2I Models by Identifying Semantic Directions

camenduru / arc2face
Arc2Face: A Foundation Model of Human Faces

camenduru / grm
GRM: Large Gaussian Reconstruction Model for Efficient 3D Reconstruction and Generation

camenduru / aniportrait-vid2vid
AniPortrait: Audio-Driven Synthesis of Photorealistic Portrait Animation

camenduru / geowizard
GeoWizard: Unleashing the Diffusion Priors for 3D Geometry Estimation from a Single Image

camenduru / champ
Champ: Controllable and Consistent Human Image Animation with 3D Parametric Guidance

camenduru / renoise-inversion
ReNoise: Real Image Inversion Through Iterative Noising

camenduru / open-sora
Open-Sora is a work-in-progress model.

camenduru / animatediff-lightning-4-step
AnimateDiff-Lightning: Cross-Model Diffusion Distillation

camenduru / apisr
APISR: Anime Production Inspired Real-World Anime Super-Resolution

camenduru / dynami-crafter-interpolation-320x512
DynamiCrafter: Animating Open-domain Images with Video Diffusion Priors

camenduru / visual-style-prompting-controlnet
Visual Style Prompting with Swapping Self-Attention

camenduru / crm
CRM: Single Image to 3D Textured Mesh with Convolutional Reconstruction Model
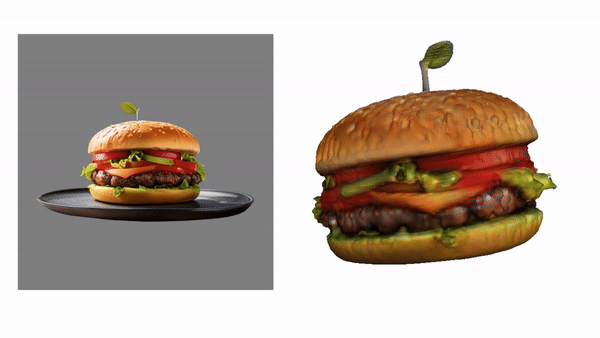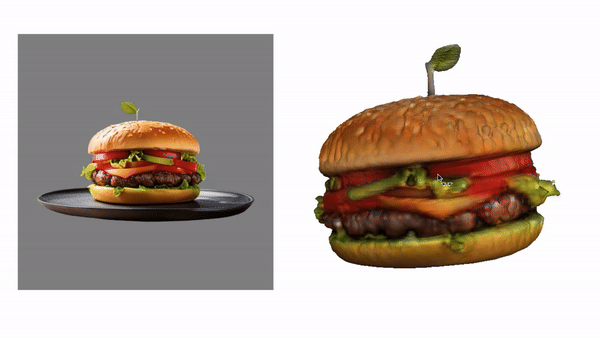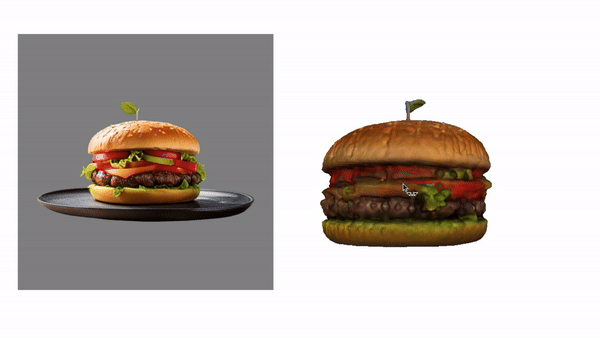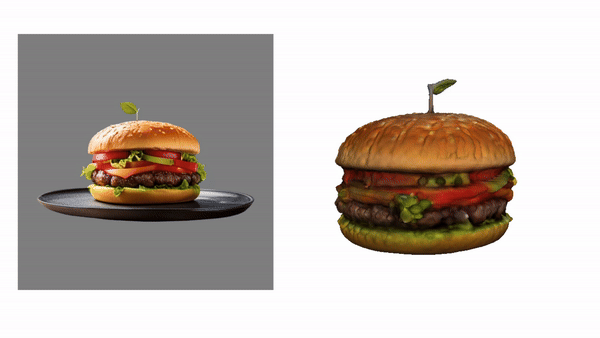
camenduru / tripo-sr
TripoSR: Fast 3D Object Reconstruction from a Single Image
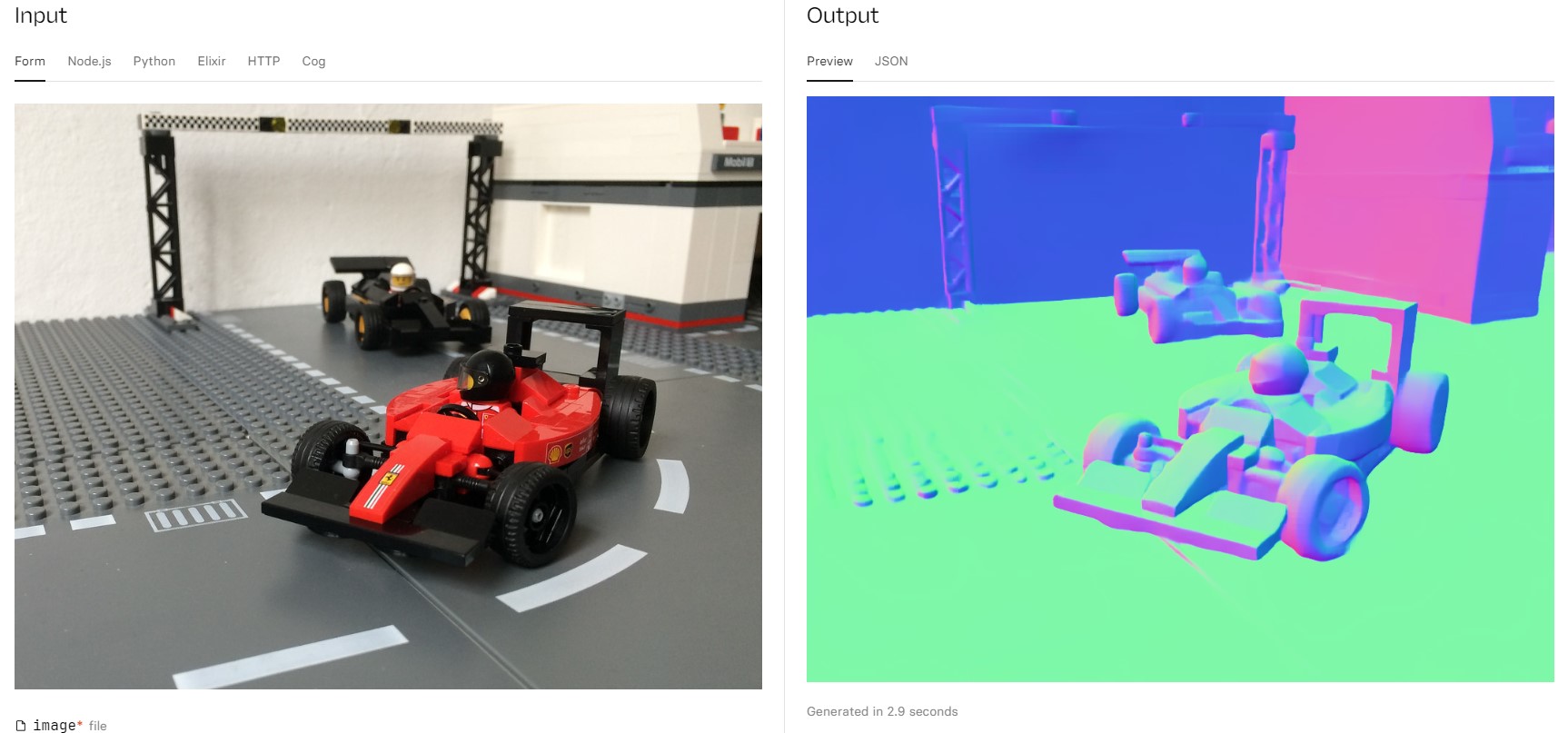
camenduru / dsine
Rethinking Inductive Biases for Surface Normal Estimation

camenduru / dust3r
DUSt3R: Geometric 3D Vision Made Easy

camenduru / lgm-ply-to-glb
LGM: Large Multi-View Gaussian Model for High-Resolution 3D Content Creation

camenduru / magic-dance
MagicDance: Realistic Human Dance Video Generation with Motions & Facial Expressions Transfer

camenduru / ml-mgie
Guiding Instruction-based Image Editing via Multimodal Large Language Models

camenduru / hand-refiner
Hand Refiner 512x512

camenduru / lgm
LGM: Large Multi-View Gaussian Model for High-Resolution 3D Content Creation
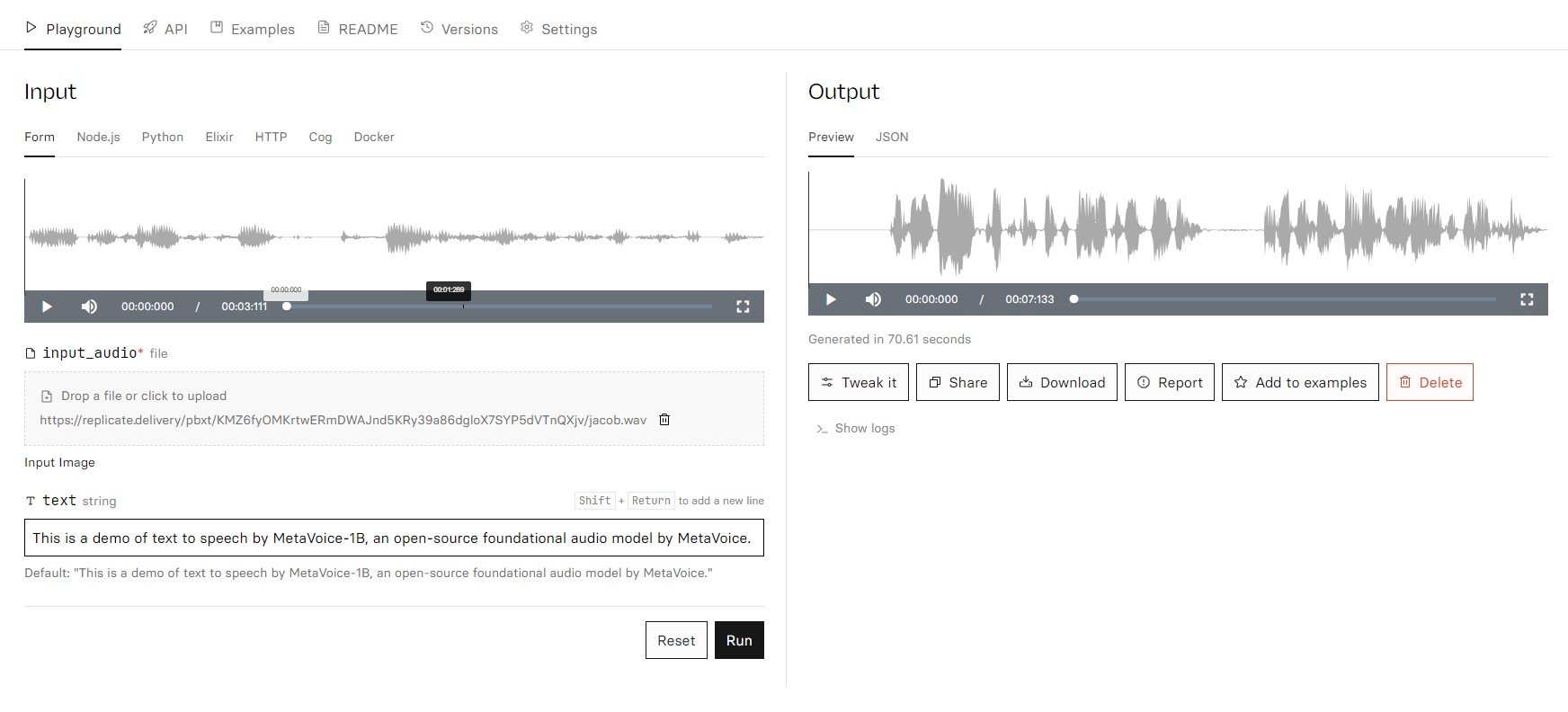
camenduru / metavoice
MetaVoice-1B: 1.2B parameter base model trained on 100K hours of speech
camenduru / dynami-crafter-576x1024
Create a video from an image

camenduru / animate-lcm
AnimateLCM Cartoon3D Model

camenduru / moe-llava
MoE-LLaVA

camenduru / one-shot-talking-face
one-shot-talking-face-replicate

camenduru / motion-director
MotionDirector: Motion Customization of Text-to-Video Diffusion Models

camenduru / dynami-crafter
DynamiCrafter: Animating Open-domain Images with Video Diffusion Priors

camenduru / wizardlm-2-8x22b
WizardLM 2 8x22B

camenduru / mixtral-8x22b-v0.1-instruct-oh
Mixtral-8x22b-v0.1-Instruct-Open-Hermes

camenduru / mixtral-8x22b-instruct-v0.1
Mixtral 8x22b Instruct v0.1

camenduru / hairfastgan
HairFastGAN: Realistic and Robust Hair Transfer with a Fast Encoder-Based Approach