












Readme
⚡️Sana: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformer

💡 Introduction
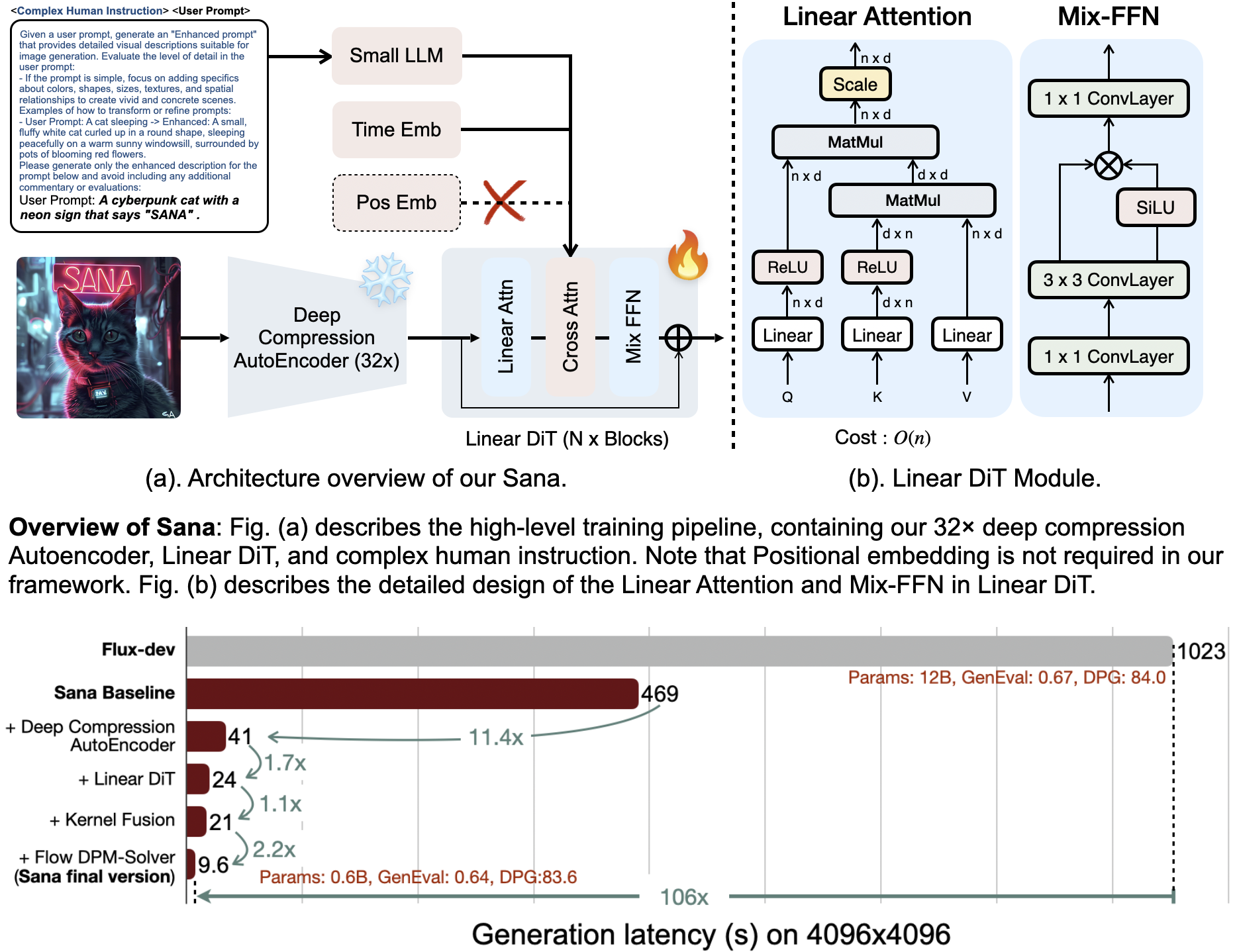
We introduce Sana, a text-to-image framework that can efficiently generate images up to 4096 × 4096 resolution. Sana can synthesize high-resolution, high-quality images with strong text-image alignment at a remarkably fast speed, deployable on laptop GPU. Core designs include:
(1) DC-AE: unlike traditional AEs, which compress images only 8×, we trained an AE that can compress images 32×, effectively reducing the number of latent tokens. \ (2) Linear DiT: we replace all vanilla attention in DiT with linear attention, which is more efficient at high resolutions without sacrificing quality. \ (3) Decoder-only text encoder: we replaced T5 with modern decoder-only small LLM as the text encoder and designed complex human instruction with in-context learning to enhance the image-text alignment. \ (4) Efficient training and sampling: we propose Flow-DPM-Solver to reduce sampling steps, with efficient caption labeling and selection to accelerate convergence.
As a result, Sana-0.6B is very competitive with modern giant diffusion model (e.g. Flux-12B), being 20 times smaller and 100+ times faster in measured throughput. Moreover, Sana-0.6B can be deployed on a 16GB laptop GPU, taking less than 1 second to generate a 1024 × 1024 resolution image. Sana enables content creation at low cost.
🤗Acknowledgements
- Thanks to PixArt-α, PixArt-Σ and Efficient-ViT for their wonderful work and codebase!
📖BibTeX
@misc{xie2024sana,
title={Sana: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformer},
author={Enze Xie and Junsong Chen and Junyu Chen and Han Cai and Haotian Tang and Yujun Lin and Zhekai Zhang and Muyang Li and Ligeng Zhu and Yao Lu and Song Han},
year={2024},
eprint={2410.10629},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2410.10629},
}