
TANGO: Text to Audio using iNstruction-Guided diffusiOn
🎵 🔥 🎉 🎉 We are releasing Tango 2 built upon Tango for text-to-audio generation. Tango 2 was initialized with the Tango-full-ft checkpoint and underwent alignment training using DPO on audio-alpaca, a pairwise text-to-audio preference dataset. Download the model, Access the demo. Trainer is available in the tango2 directory🎶

Description
TANGO is a latent diffusion model (LDM) for text-to-audio (TTA) generation. TANGO can generate realistic audios including human sounds, animal sounds, natural and artificial sounds and sound effects from textual prompts. We use the frozen instruction-tuned LLM Flan-T5 as the text encoder and train a UNet based diffusion model for audio generation. We perform comparably to current state-of-the-art models for TTA across both objective and subjective metrics, despite training the LDM on a 63 times smaller dataset. We release our model, training, inference code, and pre-trained checkpoints for the research community.

🎵 🔥 We are releasing Tango 2 built upon Tango for text-to-audio generation. Tango 2 was initialized with the Tango-full-ft checkpoint and underwent alignment training using DPO on audio-alpaca, a pairwise text-to-audio preference dataset. 🎶
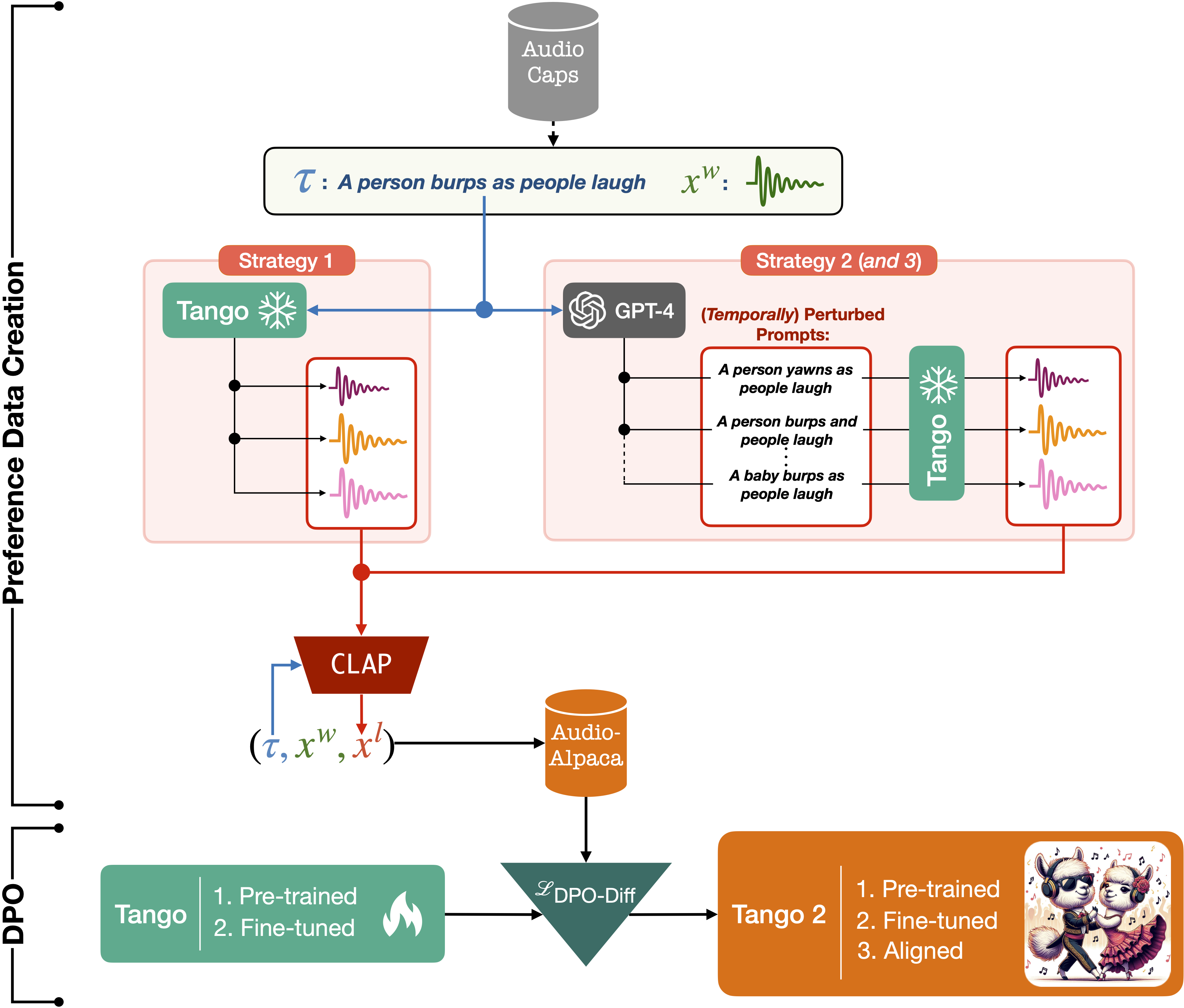
🎵 🔥 We are also making Audio-alpaca available. Audio-alpaca is a pairwise preference dataset containing about 15k (prompt,audio_w, audio_l) triplets where given a textual prompt, audio_w is the preferred generated audio and audio_l is the undesirable audio. Download Audio-alpaca. Tango 2 was trained on Audio-alpaca.
Citation
Please consider citing the following articles if you found our work useful:
@misc{majumder2024tango,
title={Tango 2: Aligning Diffusion-based Text-to-Audio Generations through Direct Preference Optimization},
author={Navonil Majumder and Chia-Yu Hung and Deepanway Ghosal and Wei-Ning Hsu and Rada Mihalcea and Soujanya Poria},
year={2024},
eprint={2404.09956},
archivePrefix={arXiv},
primaryClass={cs.SD}
}
@article{ghosal2023tango,
title={Text-to-Audio Generation using Instruction Tuned LLM and Latent Diffusion Model},
author={Ghosal, Deepanway and Majumder, Navonil and Mehrish, Ambuj and Poria, Soujanya},
journal={arXiv preprint arXiv:2304.13731},
year={2023}
}
Acknowledgement
We borrow the code in audioldm and audioldm_eval from the AudioLDM repositories. We thank the AudioLDM team for open-sourcing their code.