



Readme
Mask2Former: Masked-attention Mask Transformer for Universal Image Segmentation
Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar
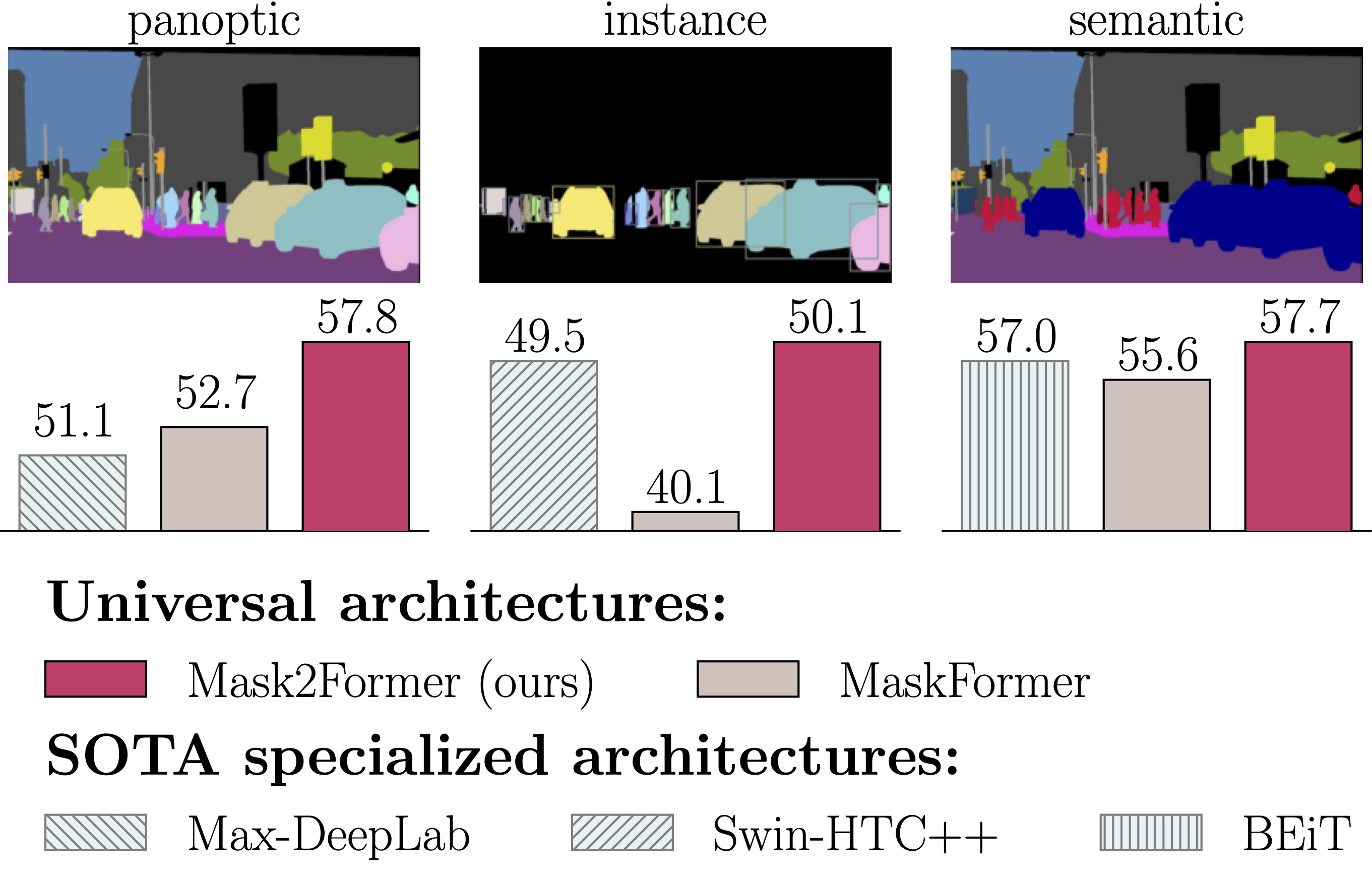
Features
- A single architecture for panoptic, instance and semantic segmentation.
- Support major segmentation datasets: ADE20K, Cityscapes, COCO, Mapillary Vistas.
@article{cheng2021mask2former,
title={Masked-attention Mask Transformer for Universal Image Segmentation},
author={Bowen Cheng and Ishan Misra and Alexander G. Schwing and Alexander Kirillov and Rohit Girdhar},
journal={arXiv},
year={2021}
}
Model created