
✨SAM 2: Segment Anything v2 for Images 🎥
NOTE: Note: Currently, we only support image inputs (not video yet) and exclusively offer the large variant of the model.
About
Implementation of SAM 2, a model for segmenting objects in images and videos using various prompts.
Limitations
- Performance may vary depending on image/video quality and complexity.
- Very fast or complex motions in videos might be challenging.
- Higher resolutions provide more detail but require more processing time.
SAM 2 is a 🔥 model developed by Meta AI Research. It excels at segmenting objects in both images and videos with various types of prompts.
Core Model
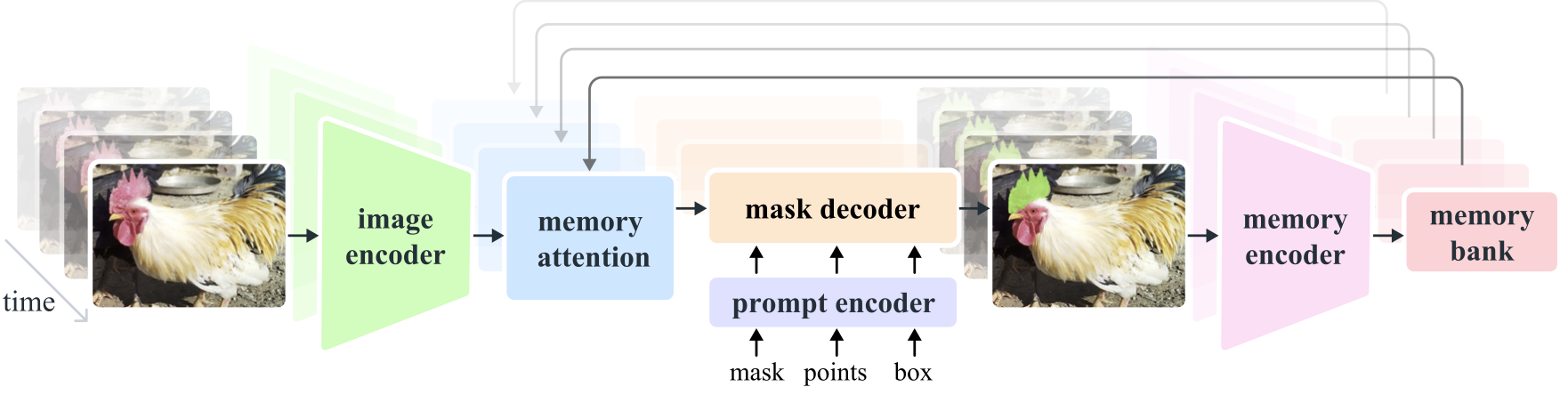
An overview of the SAM 2 framework.
SAM 2 uses a transformer architecture with streaming memory for real-time video processing. It builds on the original SAM model, extending its capabilities to video.
For more technical details, check out the Research paper.
Safety
⚠️ Users should be aware of potential ethical implications: - Ensure you have the right to use input images and videos, especially those featuring identifiable individuals. - Be responsible about generated content to avoid potential misuse. - Be cautious about using copyrighted material as inputs without permission.
Support
All credit goes to the Meta AI Research team
Citation
@article{ravi2024sam2,
title={SAM 2: Segment Anything in Images and Videos},
author={Ravi, Nikhila and Gabeur, Valentin and Hu, Yuan-Ting and Hu, Ronghang and Ryali, Chaitanya and Ma, Tengyu and Khedr, Haitham and R{\"a}dle, Roman and Rolland, Chloe and Gustafson, Laura and Mintun, Eric and Pan, Junting and Alwala, Kalyan Vasudev and Carion, Nicolas and Wu, Chao-Yuan and Girshick, Ross and Doll{\'a}r, Piotr and Feichtenhofer, Christoph},
journal={arXiv preprint},
year={2024}
}