



Readme
Stable Diffusion 3 Medium is a 2 billion parameter text-to-image model developed by Stability AI. It excels at photorealism, typography, and prompt following.
Stable Diffusion 3 on Replicate can be used for commercial work.
Model
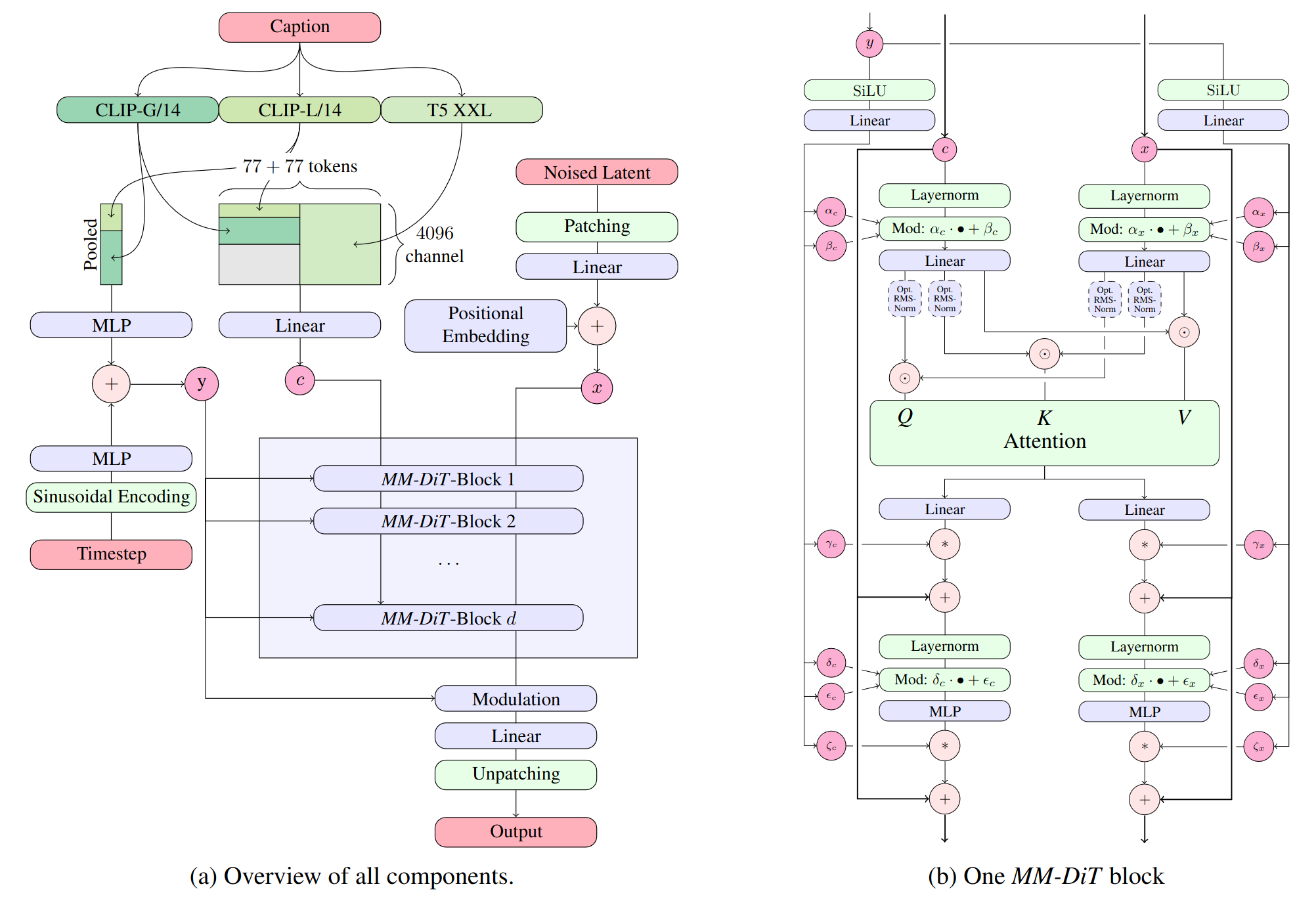
Stable Diffusion 3 Medium is a Multimodal Diffusion Transformer (MMDiT) text-to-image model that features greatly improved performance in image quality, typography, complex prompt understanding, and resource-efficiency.
For more technical details, please refer to the Research paper.
Safety
As part of our safety-by-design and responsible AI deployment approach, Stability AI implement safety measures throughout the development of our models, from the time we begin pre-training a model to the ongoing development, fine-tuning, and deployment of each model. We have implemented a number of safety mitigations that are intended to reduce the risk of severe harms, however we recommend that developers conduct their own testing and apply additional mitigations based on their specific use cases.
For more about our approach to Safety, please visit our Safety page.