How to create an AI narrator for your life
A couple of weeks ago, Sir David Attenborough watched me drink a cup of water.
David Attenborough is now narrating my life
— Charlie Holtz (@charlieholtz) November 15, 2023
Here's a GPT-4-vision + @elevenlabsio python script so you can star in your own Planet Earth: pic.twitter.com/desTwTM7RS
Or at least, a clone of him did. I recorded the video in a library on a whim, congested and with a bunch of background noise, and it went viral. It hit the top of Hacker News, Business Insider and Ars Technica wrote about it, and the nearly 4 million people watched an AI David Attenborough describe my blue shirt as part of my “mating display.”
You might be surprised (I am constantly) by all the things you can build now. I’ve experimented with building a posture checker and productivity coach that takes screenshots of my laptop screen and yells (constructive) criticism.
In this post, I’ll explain the concepts behind making your own AI narrator. At the end I’ll link you to some code you can use to make your own.
In the past I’ve described AI models as “magic boxes” that take input, transform it, and give us an output. We can use these magic boxes without having to deeply understand how they work.
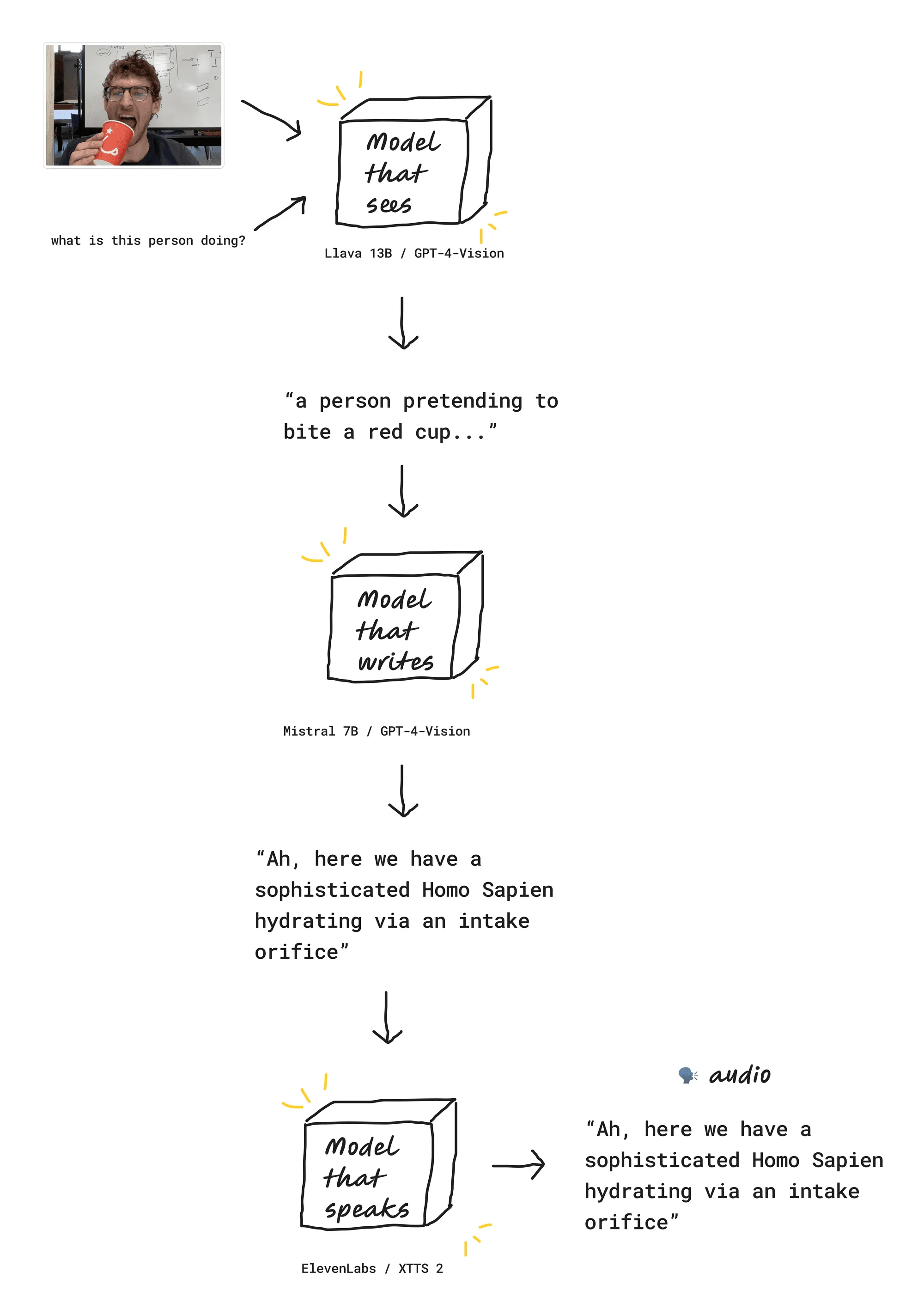
Our code is going to need three magic boxes:
- A vision model that can “see” through our computer camera and describe what we’re seeing.
- A language model that writes our script (in my case, in the style of David Attenborough).
- A text-to-speech model that takes words as input and outputs a spoken audio file.
A model that sees

Our first step is finding a vision model that can “see.” Many of the models we’re used to take text as an input, like ChatGPT or stable diffusion. We send the model text, and we get back text, images, or video. But for our life narrator, we want a model that can take images as input, and can then answer questions about those images.
We have two inputs for our vision model: an image and a text prompt. The model then returns a text response.
We have a few options here, and be warned that I am biased.
Llava 13B
Llava 13B is an open-source vision model. It’s cheap, and fast enough for our purposes. This is what I’d recommend. Llava runs on an A40 GPU and costs $0.000725 per second to run.
Here’s an example Llava 13B prediction:

Llava gives us this response:
The person in the image is holding a red cup up to their mouth, opening their mouth wide, and pretending to take a bite or drink from the cup.
A Llava prediction takes 1.5-3 seconds to return a response, so each request will cost about $0.0017.
GPT-4-Vision
This is the model I used in my demo video. It’s smarter than Llava, but it’s slightly slower and more expensive to run.
If we prompt it with the same image and question as above (“What is this person doing?”), we get this (in 2.5-4 seconds):
The person in the image is holding a red cup to their open mouth, as if they are about to eat or drink from it. They’re looking directly at the camera, and the expression on their face could be perceived as playful or humorous. They are not actually consuming the cup, but the pose suggests a mock action, perhaps for a lighthearted photo or joke.
GPT-4-Vision is a bit complicated. It’s priced by image resolution plus per token. A 250px by 140px image costs $0.00255 and $0.03 per $1K output tokens. You’ll also need to be off their waitlist to try it.
Feed the model
We also need a way to feed input images to these vision models. I’d recommend using your computer’s webcam. Here’s a script I wrote (with GPT-4’s major help) that takes a photo from your webcam every 5 seconds and saves it to a local file. It also downsizes the images — this is important, because it makes it faster (and cheaper) for our image models to read.
We have something for our model to “see”. Let’s wire up a function that can describe the image we’re seeing live.
A model that writes a script

Next, we want a model to write our script to be narrated. The output of this magic box is the words that David Attenborough speaks in my video.
Here’s an example of how to do this with Mistral 7B.. Our prompt is:
Here is a description of an image. Can you pretend you are {narrator}
and narrate it as if it is a nature documentary. Make it short.
If I do anything remotely interesting, make a big deal about it!
DESCRIPTION:
The person in the image is holding a red cup up to their mouth,
opening their mouth wide, and pretending to
take a bite or drink from the cup.
The description here is the output from our vision model in the step before. Our response looks something like:
In this fascinating observation, we see a remarkable display of human behavior.
The person in the image is holding a red cup, poised to take a bite or drink.
As they open their mouth wide, we can see the intricate workings of their
teeth and jaw, a testament to the incredible adaptability of the human body.
It's a sight to behold, a reminder of the complexities that make us who we are.I’d recommend limiting the max tokens returned to somewhere around 128. We want as fast a response time as possible. The output above took 2.7s, so right now we’re at 5-6ish second total response time.
Note we can also use GPT-4-Vision to return our response. And we can actually skip a step––we don’t need to ask for a description of an image and then translate that into a David Attenborough style script. We can do both in one prediction. GPT-4-Vision is smart enough to do both at once.
Here’s the system prompt I used:
You are {narrator}. Narrate the picture of the human as if it is a nature documentary.
Make it snarky and funny. Don't repeat yourself. Make it short.
If I do anything remotely interesting, make a big deal about it!The GPT-4-Vision API returns a response in 3.5-8 seconds (but generally closer to 3).
A model that speaks
Finally, we want our model to speak. And speak with style! We don’t want a robotic voice. We want some gusto.

There are a bunch of options here. The highest quality output you’re going to get is through ElevenLabs’s voice cloning feature. A cheaper, open source equivalent for voice cloning is XTTS-v2. Both allow you to upload text for your speaker to say, and audio for your speaker to sound like. Then you get an output that sounds like your speaker audio.
If you’re using Eleven, use their Turbo v2 model —it has 400ms latency. Check out my play_audio() function here.
The world is weird now
Our full workflow now looks like this:
And that’s it! You now know how to make your own interactive voice clone. There are a lot of cool things that are now possible. Like I mentioned, I’ve experimented with building a posture checker and productivity coach. A few days ago OthersideAI released a “Self-Operating Computer Framework” that takes screenshots of your screen to control your computer:
The world is weird now. In a good way. Happy hacking!