Readme
CosyVoice 2.0
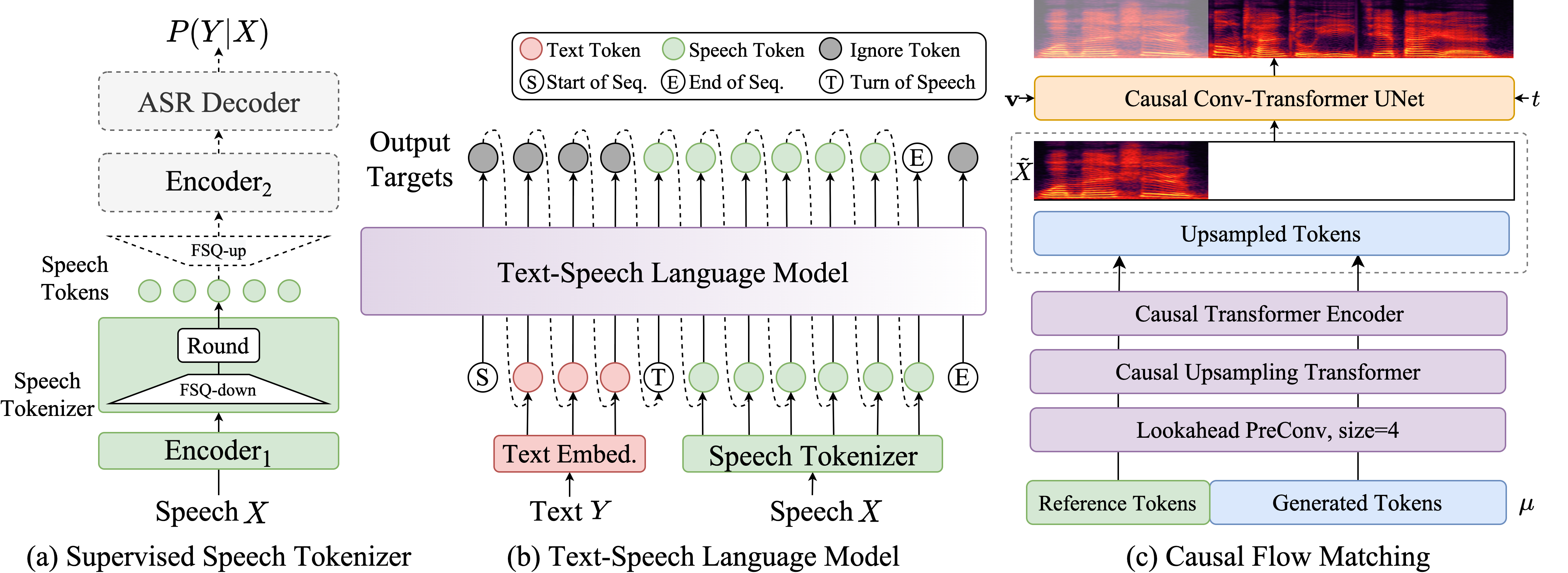 Compared to version 1.0, the new version offers more accurate, more stable, faster, and better speech generation capabilities.
Compared to version 1.0, the new version offers more accurate, more stable, faster, and better speech generation capabilities.
Multilingual
- Support Language: Chinese, English, Japanese, Korean, Chinese dialects (Cantonese, Sichuanese, Shanghainese, Tianjinese, Wuhanese, etc.)
- Crosslingual & Mixlingual:Support zero-shot voice cloning for cross-lingual and code-switching scenarios.
Ultra-Low Latency
- Bidirectional Streaming Support: CosyVoice 2.0 integrates offline and streaming modeling technologies.
- Rapid First Packet Synthesis: Achieves latency as low as 150ms while maintaining high-quality audio output.
High Accuracy
- Improved Pronunciation: Reduces pronunciation errors by 30% to 50% compared to CosyVoice 1.0.
- Benchmark Achievements: Attains the lowest character error rate on the hard test set of the Seed-TTS evaluation set.
Strong Stability
- Consistency in Timbre: Ensures reliable voice consistency for zero-shot and cross-language speech synthesis.
- Cross-language Synthesis: Marked improvements compared to version 1.0.
Natural Experience
- Enhanced Prosody and Sound Quality: Improved alignment of synthesized audio, raising MOS evaluation scores from 5.4 to 5.53.
- Emotional and Dialectal Flexibility: Now supports more granular emotional controls and accent adjustments.