


Readme
🚀 Faster Diffusion: Rethinking the Role of UNet Encoder in Diffusion Models
Our approach can easily be combined with various diffusion model-based tasks 🧠 (such as text-to-image, personalized generation, video generation, etc.) and various sampling strategies (like DDIM-50 steps, Dpm-solver-20 steps) to achieve training-free acceleration.
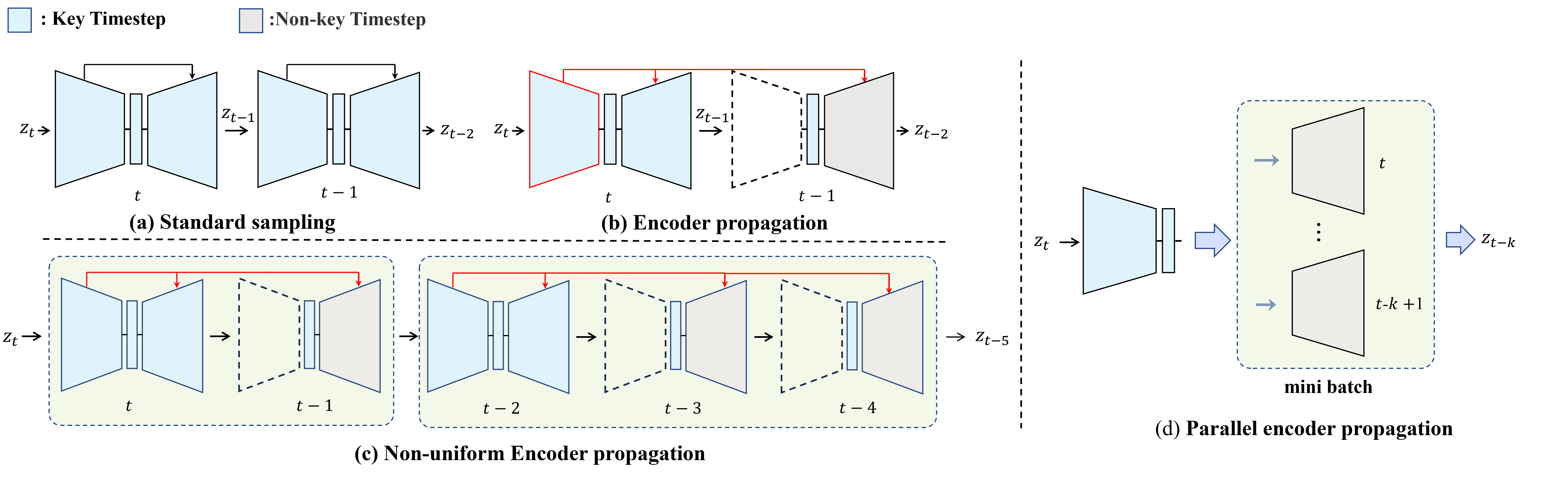
We propose FasterDiffusion, a training-free diffusion model acceleration scheme that can be widely integrated with various generative tasks and sampling strategies. Quantitative evaluation metrics such as FID, Clipscore, and user studies all indicate that our approach is on par with the original model in terms of genenrated-image quality. Specifically, we have observed the similarity of internal features in the Unet Encoder at adjacent time steps in the diffusion model. Consequently, it is possible to reuse Encoder features from previous time steps at specific time steps to reduce computational load. We propose a feature propagation scheme for accelerated generation, and this feature propagation enables independent computation at certain time steps, allowing us to further leverage GPU acceleration through a parallel strategy. Additionally, we introduced a prior noise injection method to improve the texture details of generated images.
Our method is not only suitable for standard text-to-image(~1.8x acceleration for Stable Diffusion and ~1.3x acceleration for DeepFloyd-IF ) tasks but can also be applied to diverse tasks such as text-to-video(~1.5x acceleration on VideoDiffusion), personalized generation(~1.8x acceleration for DreamBooth and Custom Diffusion), and reference-guided generation(~2.1x acceleration for ControlNet), among others.
Citation
@misc{li2023faster,
title={Faster Diffusion: Rethinking the Role of UNet Encoder in Diffusion Models},
author={Senmao Li and Taihang Hu and Fahad Shahbaz Khan and Linxuan Li and Shiqi Yang and Yaxing Wang and Ming-Ming Cheng and Jian Yang},
year={2023},
eprint={2312.09608},
archivePrefix={arXiv},
primaryClass={cs.CV}
}