


Readme
λ-ECLIPSE: Multi-Concept Personalized Text-to-Image Diffusion Models by Leveraging CLIP Latent Space
This repository contains the inference code for our paper, λ-ECLIPSE.
-
The λ-ECLIPSE model is a light weight support for multi-concept personalization. λ-ECLIPSE is tiny T2I prior model designed for Kandinsky v2.2 diffusion image generator.
-
λ-ECLIPSE model extends the ECLIPSE-Prior via incorporating the image-text interleaved data.
-
λ-ECLIPSE shows that we do not need to train the Personalized T2I (P-T2I) models on lot of resources. For instance, λ-ECLIPSE is trained on mere 74 GPU Hours (A100) compared to it’s couterparts BLIP-Diffusion (2304 GPU hours) and Kosmos-G (12300 GPU hours).
Qualitative Examples:

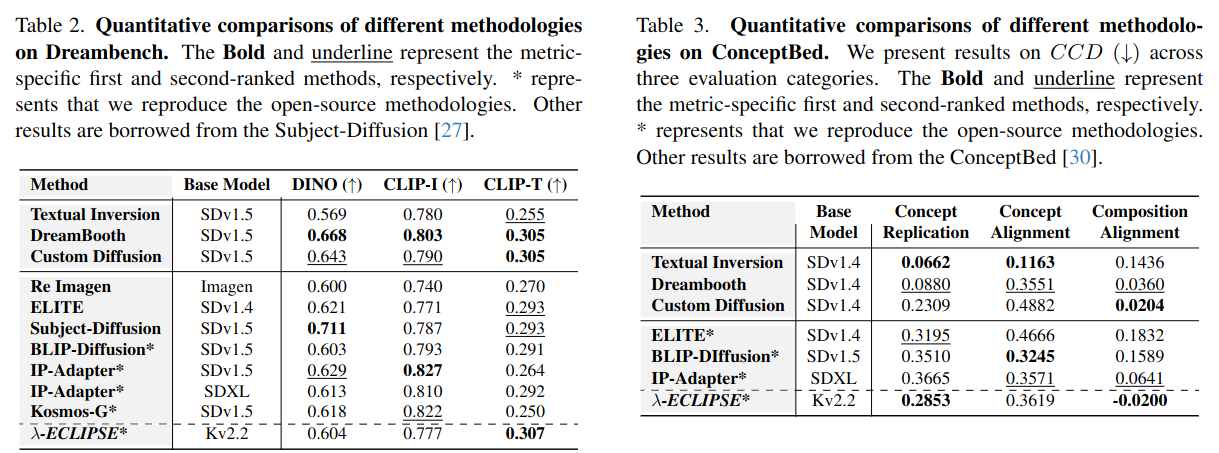
Quantitative Comparisons:
Acknowledgement
We would like to acknoweldge excellent open-source text-to-image models (Kalro and Kandinsky) without them this work would not have been possible. Also, we thank HuggingFace for streamlining the T2I models.