


Readme
UniDiffuser
Code and models for the paper “One Transformer Fits All Distributions in Multi-Modal Diffusion”

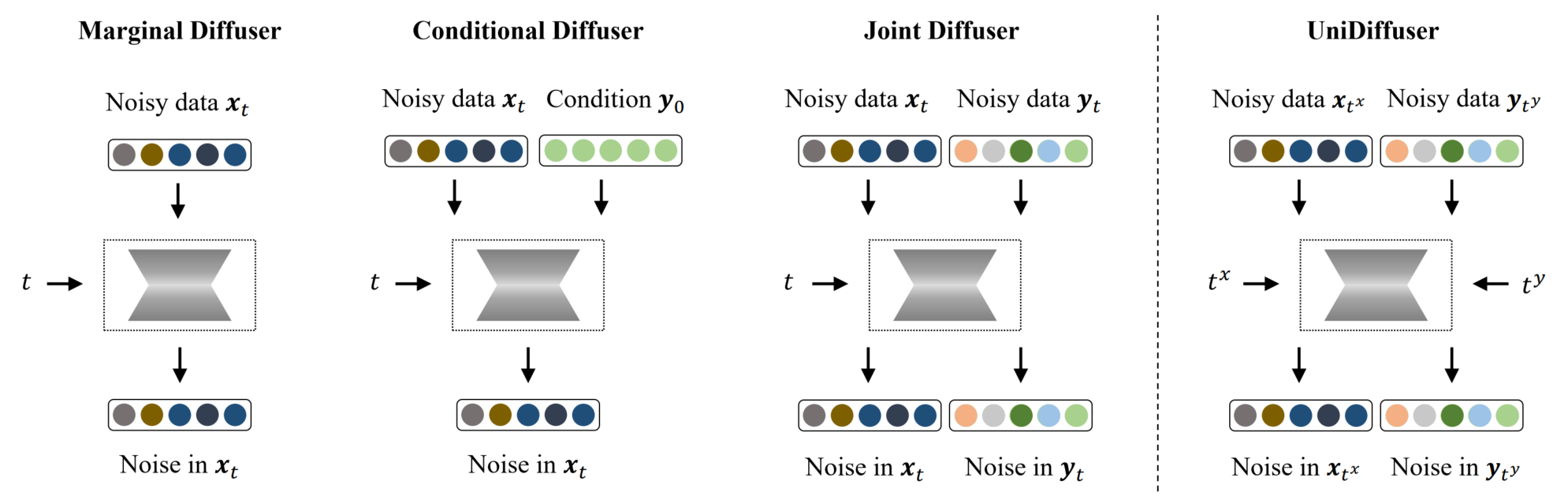
UniDiffuser is a unified diffusion framework to fit all distributions relevant to a set of multi-modal data in one model. Its key insight is – learning diffusion models for marginal, conditional, and joint distributions can be unified as predicting the noise in the perturbed data, where the perturbation levels (i.e. timesteps) can be different for different modalities. Inspired by the unified view, UniDiffuser learns all distributions simultaneously with a minimal modification to the original diffusion model – perturbs data in all modalities instead of a single modality, inputs individual timesteps in different modalities, and predicts the noise of all modalities instead of a single modality. UniDiffuser is parameterized by a transformer for diffusion models to handle input types of different modalities. Implemented on large-scale paired image-text data, UniDiffuser is able to perform image, text, text-to-image, image-to-text, and image-text pair generation by setting proper timesteps without additional overhead. In particular, UniDiffuser is able to produce perceptually realistic samples in all tasks and its quantitative results (e.g., the FID and CLIP score) are not only superior to existing general-purpose models but also comparable to the bespoken models (e.g., Stable Diffusion and DALL-E 2) in representative tasks (e.g., text-to-image generation).
References
If you find the code useful for your research, please consider citing
@article{bao2022one,
title={One Transformer Fits All Distributions in Multi-Modal Diffusion at Scale},
author={Bao, Fan and Nie, Shen and Xue, Kaiwen and Li, Chongxuan and Pu, Shi and Wang, Yaole and Yue, Gang and Cao, Yue and Su, Hang and Zhu, Jun},
year={2023}
}
@inproceedings{bao2022all,
title={All are Worth Words: A ViT Backbone for Diffusion Models},
author={Bao, Fan and Nie, Shen and Xue, Kaiwen and Cao, Yue and Li, Chongxuan and Su, Hang and Zhu, Jun},
booktitle = {CVPR},
year={2023}
}
This implementation is heavily based on the U-ViT code.