

Readme
DM-Count
Official Pytorch implementation of the paper Distribution Matching for Crowd Counting (NeurIPS, spotlight).
We propose to use Distribution Matching for crowd COUNTing (DM-Count). In DM-Count, we use Optimal Transport (OT) to measure the similarity between the normalized predicted density map and the normalized ground truth density map. To stabilize OT computation, we include a Total Variation loss in our model. We show that the generalization error bound of DM-Count is tighter than that of the Gaussian smoothed methods. Empirically, our method outperforms the state-of-the-art methods by a large margin on four challenging crowd counting datasets: UCF-QNRF, NWPU, ShanghaiTech, and UCF-CC50.
Usage
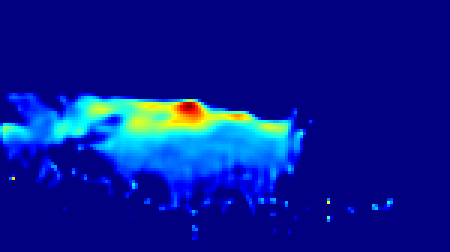
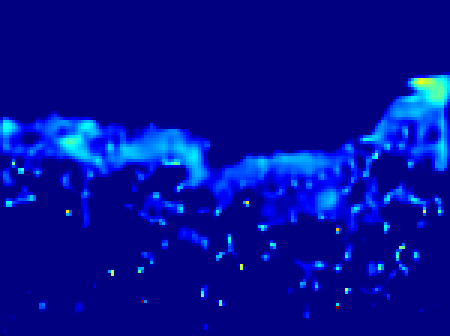
Input an image to view the predicted density map and estimated number of people. You can choose between four pretrained models, each trained on a different crowd counting dataset: UCF-QNRF (qnrf), NWPU (nwpu), Shanghaitech part A (sh_A) and Shanghaitech part B (sh_B).
References
If you find this work or code useful, please cite:
@inproceedings{wang2020DMCount,
title={Distribution Matching for Crowd Counting},
author={Boyu Wang and Huidong Liu and Dimitris Samaras and Minh Hoai},
booktitle={Advances in Neural Information Processing Systems},
year={2020},
}