
Readme
🦙🎧 LLaMA-Omni: Seamless Speech Interaction with Large Language Models
LLaMA-Omni is a speech-language model built upon Llama-3.1-8B-Instruct. It supports low-latency and high-quality speech interactions, simultaneously generating both text and speech responses based on speech instructions.
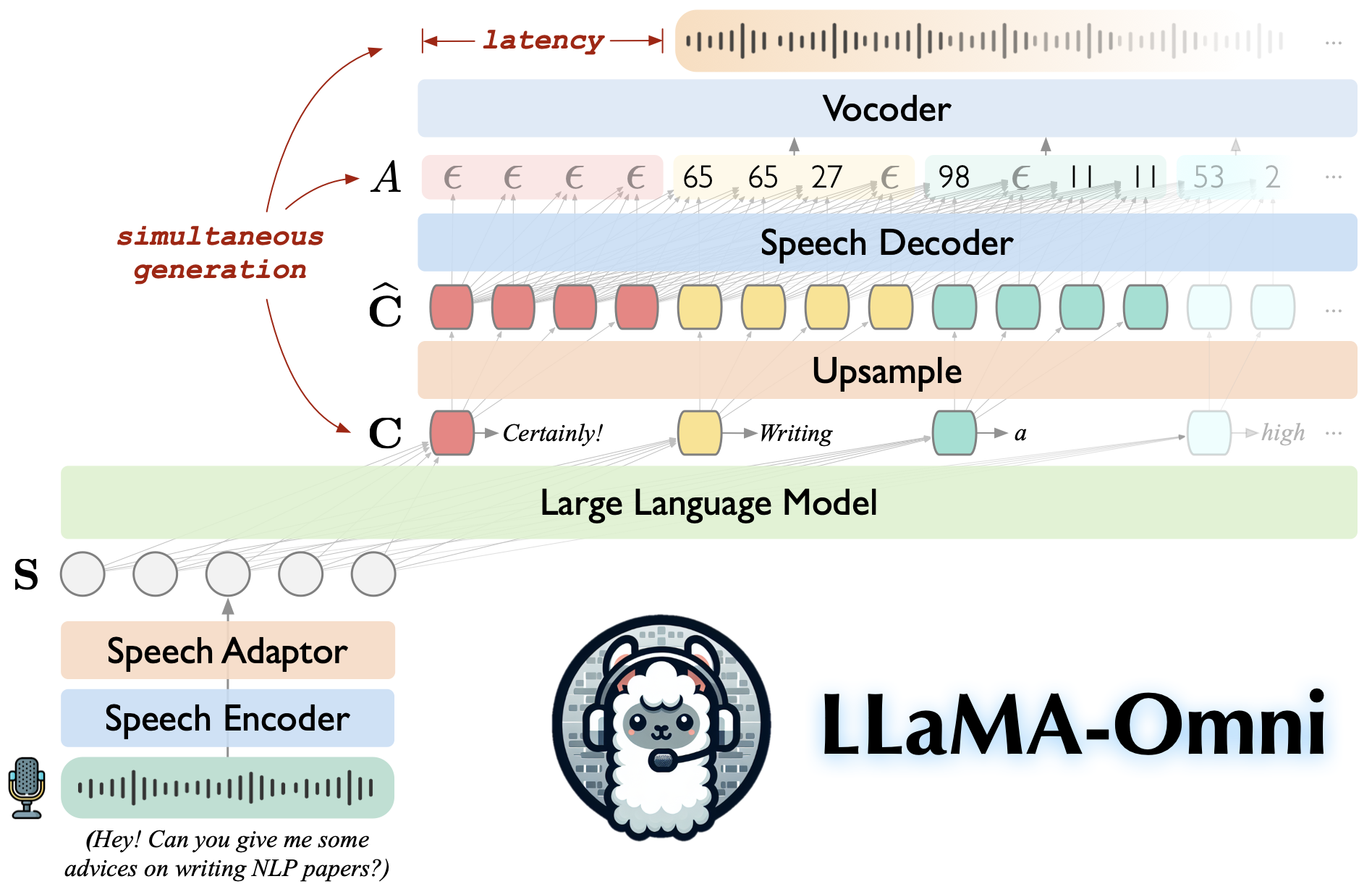
💡 Highlights
-
💪 Built on Llama-3.1-8B-Instruct, ensuring high-quality responses.
-
🚀 Low-latency speech interaction with a latency as low as 226ms.
-
🎧 Simultaneous generation of both text and speech responses.
-
♻️ Trained in less than 3 days using just 4 GPUs.
LICENSE
Our code is released under the Apache-2.0 License. Our model, as it is built on Llama 3.1, is required to comply with the Llama 3.1 License.
Acknowledgements
- LLaVA: The codebase we built upon.
- SLAM-LLM: We borrow some code about speech encoder and speech adaptor.
Citation
If you have any questions, please feel free to submit an issue or contact fangqingkai21b@ict.ac.cn.
If our work is useful for you, please cite as:
@article{fang-etal-2024-llama-omni,
title={LLaMA-Omni: Seamless Speech Interaction with Large Language Models},
author={Fang, Qingkai and Guo, Shoutao and Zhou, Yan and Ma, Zhengrui and Zhang, Shaolei and Feng, Yang},
journal={arXiv preprint arXiv:2409.06666},
year={2024}
}
Model created