



Readme
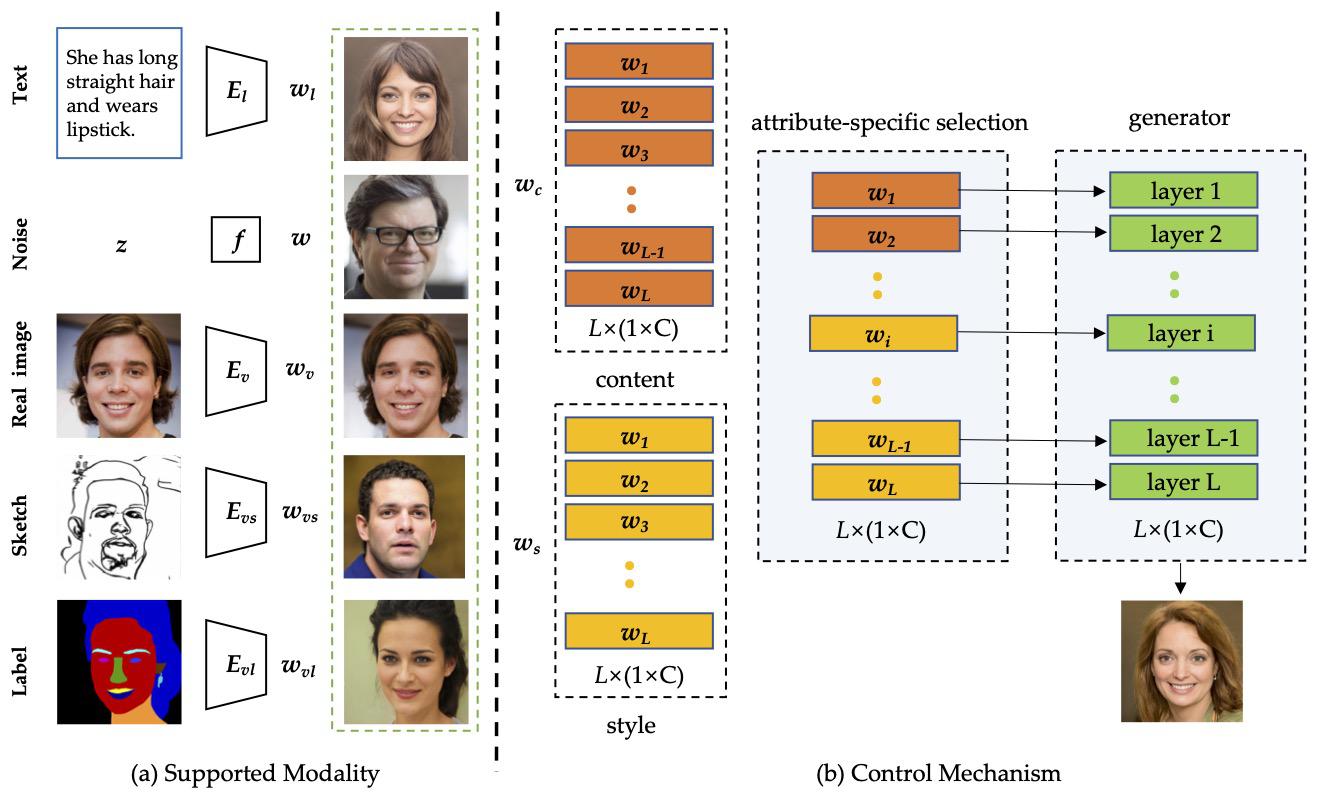
We have proposed a novel method (abbreviated as TediGAN) for image synthesis using textual descriptions, which unifies two different tasks (text-guided image generation and manipulation) into the same framework and achieves high accessibility, diversity, controllability, and accurateness for facial image generation and manipulation. Through the proposed multi-modal GAN inversion and large-scale multi-modal dataset, our method can effectively synthesize images with unprecedented quality.
Acknowledgments
The GAN inversion codes borrow heavily from idinvert and pSp. The StyleGAN implementation is from genforce and StyleGAN2 from Kim Seonghyeon.
Citation
If you find our work, code, or the benchmark helpful for your research, please consider to cite:
@inproceedings{xia2021tedigan,
title={TediGAN: Text-Guided Diverse Face Image Generation and Manipulation},
author={Xia, Weihao and Yang, Yujiu and Xue, Jing-Hao and Wu, Baoyuan},
booktitle={IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2021}
}
@article{xia2021open,
title={Towards Open-World Text-Guided Face Image Generation and Manipulation},
author={Xia, Weihao and Yang, Yujiu and Xue, Jing-Hao and Wu, Baoyuan},
journal={arxiv preprint arxiv: 2104.08910},
year={2021}
}
Model created