Karan Desai and Justin Johnson University of Michigan
Model Zoo, Usage Instructions and API docs: kdexd.github.io/virtex
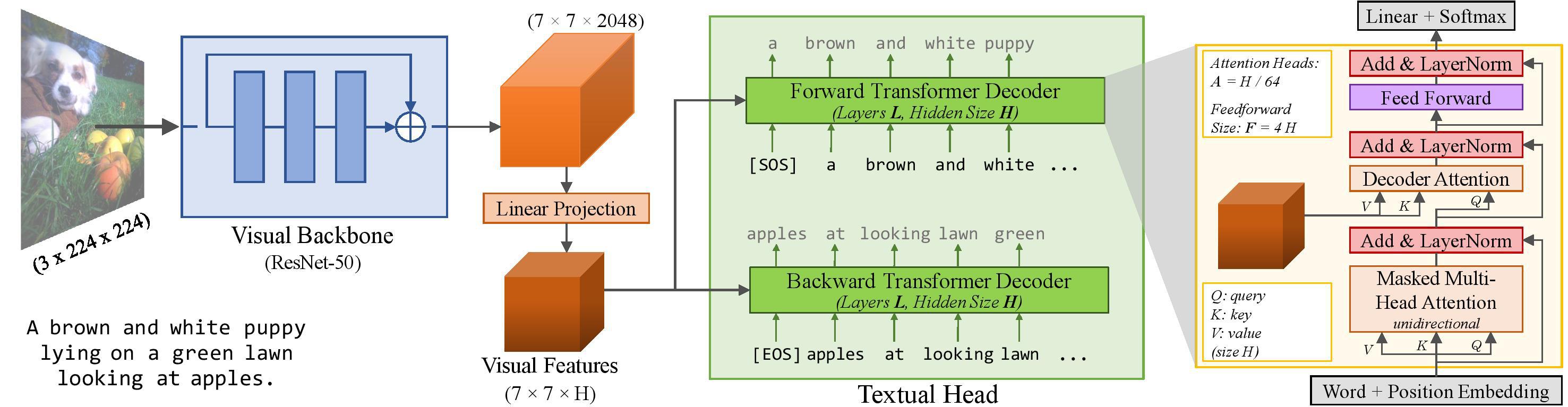
VirTex is a pretraining approach which uses semantically dense captions to learn visual representations. We train CNN + Transformers from scratch on COCO Captions, and transfer the CNN to downstream vision tasks including image classification, object detection, and instance segmentation. VirTex matches or outperforms models which use ImageNet for pretraining – both supervised or unsupervised – despite using up to 10x fewer images.
This is a demo of image captioning using VirTex.
Model created