




Readme
Swin2SR: SwinV2 Transformer for Compressed Image Super-Resolution and Restoration @ AIM ECCV 2022
Marcos V. Conde, Ui-Jin Choi, Maxime Burchi, Radu Timofte
Computer Vision Lab, CAIDAS, University of Würzburg and MegaStudyEdu, South Korea
This work is inspired by the amazing SwinIR by Jingyun Liang, as a possible improvement.
This is the official repository and PyTorch implementation of Swin2SR. We provide the supplementary material, code, pretrained models and demos. Swin2SR represents a possible improvement of the famous SwinIR by Jingyun Liang (kudos for such an amazing contribution ✋). Our model achieves state-of-the-art performance in:
- classical, lighweight and real-world image super-resolution (SR)
- color JPEG compression artifact reduction
- compressed input super-resolution: top solution at the “AIM 2022 Challenge on Super-Resolution of Compressed Image and Video” organized by Ren Yang and Radu Timofte

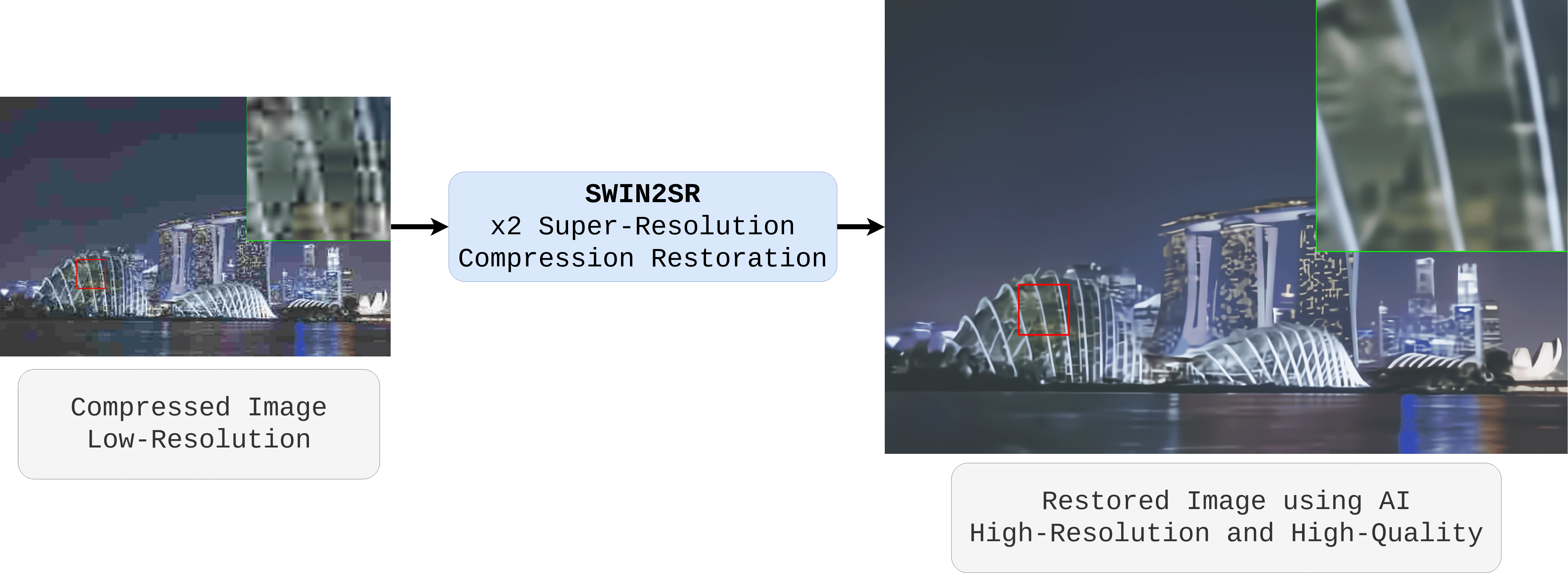
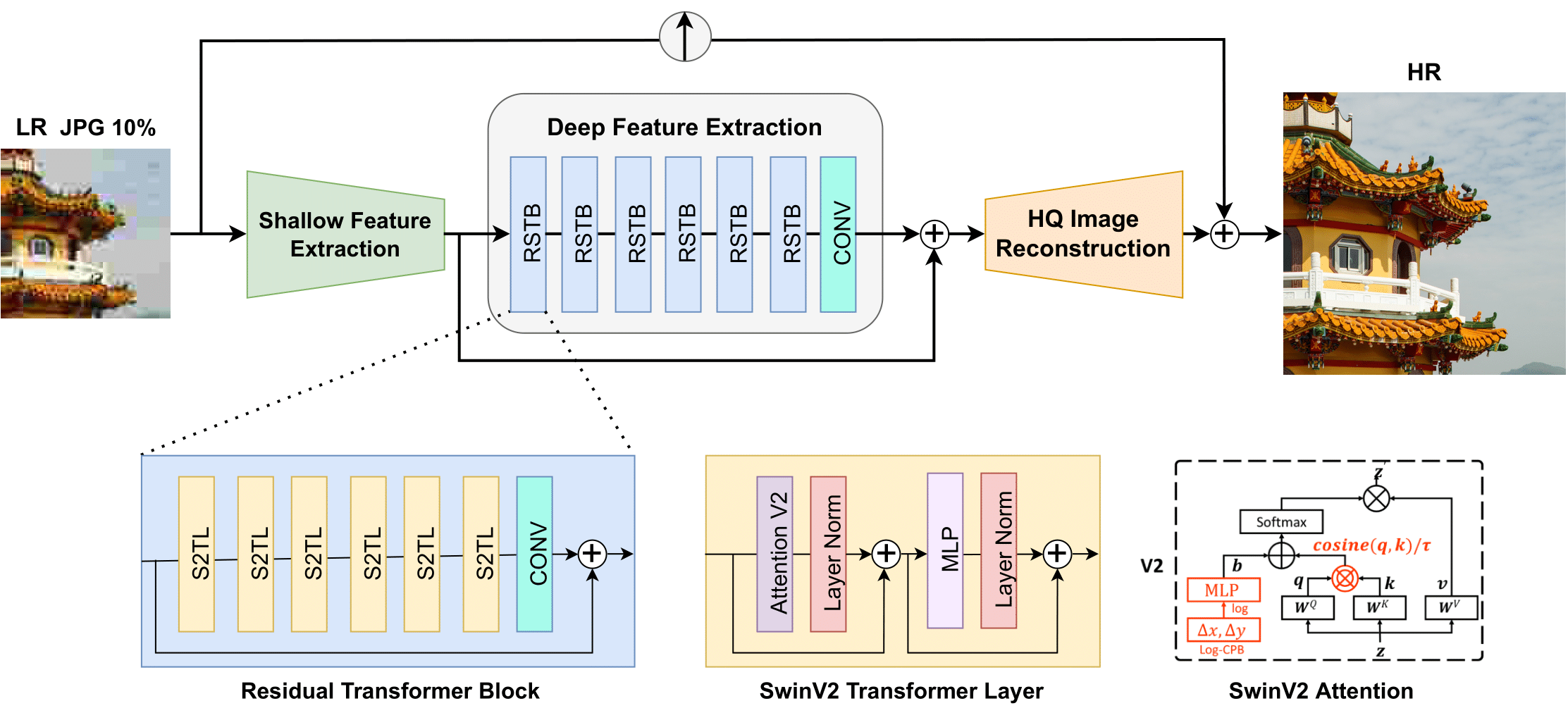
ABSTRACT
Compression plays an important role on the efficient transmission and storage of images and videos through band-limited systems such as streaming services, virtual reality or videogames. However, compression unavoidably leads to artifacts and the loss of the original information, which may severely degrade the visual quality. For these reasons, quality enhancement of compressed images has become a popular research topic. While most state-of-the-art image restoration methods are based on convolutional neural networks, other transformers-based methods such as SwinIR, show impressive performance on these tasks.
In this paper, we explore the novel Swin Transformer V2, to improve SwinIR for image super-resolution, and in particular, the compressed input scenario. Using this method we can tackle the major issues in training transformer vision models, such as training instability, resolution gaps between pre-training and fine-tuning, and hunger on data. We conduct experiments on three representative tasks: JPEG compression artifacts removal, image super-resolution (classical and lightweight), and compressed image super-resolution. Experimental results demonstrate that our method, Swin2SR, can improve the training convergence and performance of SwinIR, and is a top-5 solution at the “AIM 2022 Challenge on Super-Resolution of Compressed Image and Video”.
Citation and Acknowledgement
@inproceedings{conde2022swin2sr,
title={{S}win2{SR}: SwinV2 Transformer for Compressed Image Super-Resolution and Restoration},
author={Conde, Marcos V and Choi, Ui-Jin and Burchi, Maxime and Timofte, Radu},
booktitle={Proceedings of the European Conference on Computer Vision (ECCV) Workshops},
year={2022}
}
This project is released under the Apache 2.0 license. The codes are heavily based on Swin Transformer and SwinV2 Transformer by Ze Liu. We also refer to codes in KAIR, BasicSR and SwinIR. Please also follow their licenses. Thanks for their awesome works.
Contact
Marcos Conde (marcos.conde@uni-wuerzburg.de) is the contact person. Please add in the email subject “swin2sr”.