
Readme
sgmse-speech-enhancement-deverb-replicate
Score-based Generative Models (Diffusion Models) for Speech Enhancement and Dereverberation, for replicate.com
Speech Enhancement and Dereverberation with Diffusion-based Generative Models
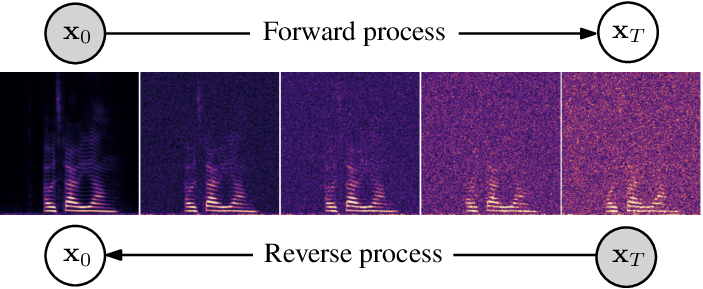
The official PyTorch implementations for the papers:
- Simon Welker, Julius Richter, Timo Gerkmann, “Speech Enhancement with Score-Based Generative Models in the Complex STFT Domain”, ISCA Interspeech, Incheon, Korea, Sept. 2022. [bibtex]
- Julius Richter, Simon Welker, Jean-Marie Lemercier, Bunlong Lay, Timo Gerkmann, “Speech Enhancement and Dereverberation with Diffusion-Based Generative Models”, IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 31, pp. 2351-2364, 2023. [bibtex]
- Julius Richter, Yi-Chiao Wu, Steven Krenn, Simon Welker, Bunlong Lay, Shinji Watanabe, Alexander Richard, Timo Gerkmann, “EARS: An Anechoic Fullband Speech Dataset Benchmarked for Speech Enhancement and Dereverberation”, ISCA Interspecch, Kos, Greece, Sept. 2024. [bibtex]
Audio examples and supplementary materials are available on our SGMSE project page and EARS project page.
Follow-up work
Please also check out their follow-up work with code available:
- Jean-Marie Lemercier, Julius Richter, Simon Welker, Timo Gerkmann, “StoRM: A Diffusion-based Stochastic Regeneration Model for Speech Enhancement and Dereverberation”, IEEE/ACM Transactions on Audio, Speech, Language Processing, vol. 31, pp. 2724 -2737, 2023. [github]
- Bunlong Lay, Simon Welker, Julius Richter, Timo Gerkmann, “Reducing the Prior Mismatch of Stochastic Differential Equations for Diffusion-based Speech Enhancement”, ISCA Interspeech, Dublin, Ireland, Aug. 2023. [github]
For 48 kHz models [3], they offer pretrained checkpoints for speech enhancement, trained on the EARS-WHAM dataset, and for dereverberation, trained on the EARS-Reverb dataset. You can download them here.
Citations / References
They kindly ask you to cite our papers in your publication when using any of their research or code:
@inproceedings{welker22speech,
author={Simon Welker and Julius Richter and Timo Gerkmann},
title={Speech Enhancement with Score-Based Generative Models in the Complex {STFT} Domain},
year={2022},
booktitle={Proc. Interspeech 2022},
pages={2928--2932},
doi={10.21437/Interspeech.2022-10653}
}
@article{richter2023speech,
title={Speech Enhancement and Dereverberation with Diffusion-based Generative Models},
author={Richter, Julius and Welker, Simon and Lemercier, Jean-Marie and Lay, Bunlong and Gerkmann, Timo},
journal={IEEE/ACM Transactions on Audio, Speech, and Language Processing},
volume={31},
pages={2351-2364},
year={2023},
doi={10.1109/TASLP.2023.3285241}
}
@inproceedings{richter2024ears,
title={{EARS}: An Anechoic Fullband Speech Dataset Benchmarked for Speech Enhancement and Dereverberation},
author={Richter, Julius and Wu, Yi-Chiao and Krenn, Steven and Welker, Simon and Lay, Bunlong and Watanabe, Shinjii and Richard, Alexander and Gerkmann, Timo},
booktitle={ISCA Interspeech},
year={2024}
}
[1] Simon Welker, Julius Richter, Timo Gerkmann. “Speech Enhancement with Score-Based Generative Models in the Complex STFT Domain”, ISCA Interspeech, Incheon, Korea, Sep. 2022.
[2] Julius Richter, Simon Welker, Jean-Marie Lemercier, Bunlong Lay, Timo Gerkmann. “Speech Enhancement and Dereverberation with Diffusion-Based Generative Models”, IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 31, pp. 2351-2364, 2023.
[3] Julius Richter, Yi-Chiao Wu, Steven Krenn, Simon Welker, Bunlong Lay, Shinji Watanabe, Alexander Richard, Timo Gerkmann. “EARS: An Anechoic Fullband Speech Dataset Benchmarked for Speech Enhancement and Dereverberation”, ISCA Interspeech, Kos, Greece, 2024.