
Readme
ConsistI2V
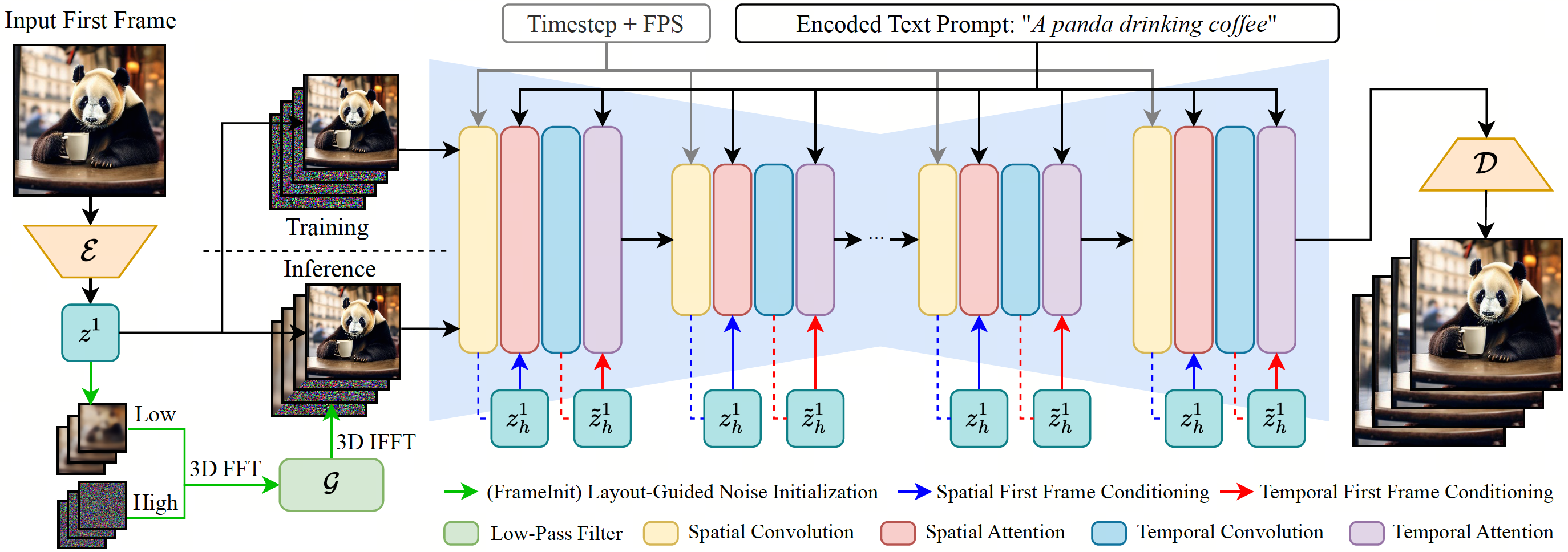
We propose ConsistI2V, a diffusion-based method to enhance visual consistency for I2V generation. Specifically, we introduce (1) spatiotemporal attention over the first frame to maintain spatial and motion consistency, (2) noise initialization from the low-frequency band of the first frame to enhance layout consistency. These two approaches enable ConsistI2V to generate highly consistent videos.
Citation
Please kindly cite our paper if you find our code, data, models or results to be helpful.
@article{ren2024consisti2v,
title={ConsistI2V: Enhancing Visual Consistency for Image-to-Video Generation},
author={Ren, Weiming and Yang, Harry and Zhang, Ge and Wei, Cong and Du, Xinrun and Huang, Stephen and Chen, Wenhu},
journal={arXiv preprint arXiv:2402.04324},
year={2024}
}
Acknowledgements
Our codebase is built upon AnimateDiff, FreeInit and 🤗 diffusers. Thanks for open-sourcing.
Model created