
Readme
✨MimicMotion: High-Quality Human Motion Video Generation🎥
About
Implementation of MimicMotion, a model for generating high-quality human motion videos with confidence-aware pose guidance.
Examples
Here are some examples of MimicMotion’s outputs:






<span>Highlights: rich details, good temporal smoothness, and long video length. </span>
Limitations
- The model performs best with clear, well-lit input videos and images.
- Very complex or rapid motions may be challenging for the model to reproduce accurately.
- Higher resolutions provide more detail but require more processing time and resources.
MimicMotion is a 🔥 model developed by Tencent AI Lab. It excels at generating high-quality human motion videos with rich details and good temporal smoothness.
MimicMotion on Replicate can be used for research and non-commercial work. For commercial use, please contact the original authors.
Core Model
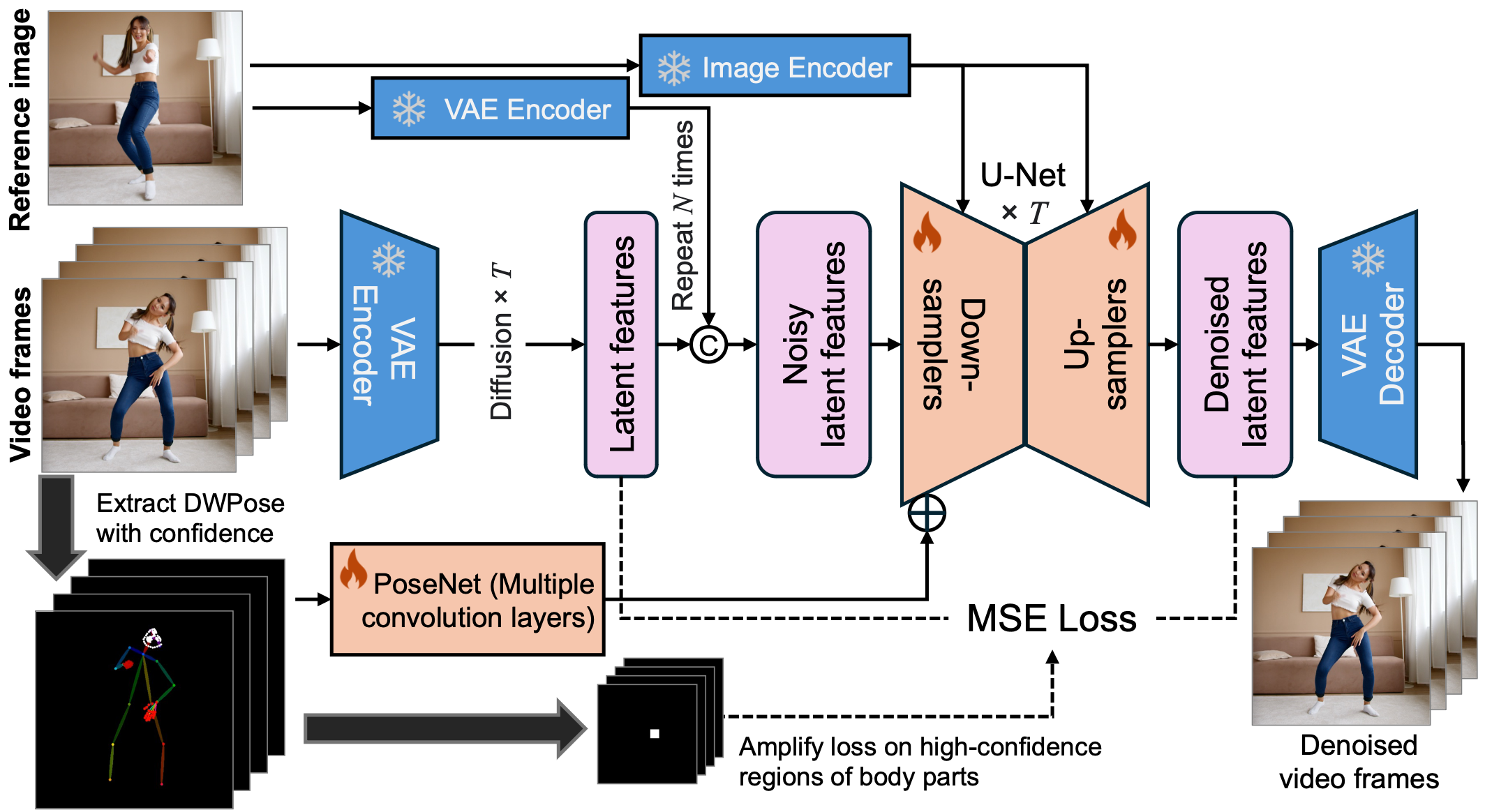
An overview of the framework of MimicMotion.
MimicMotion uses a sophisticated architecture including a UNet-based spatio-temporal model, VAE, CLIP vision model, and custom PoseNet. It features confidence-aware pose guidance and progressive latent fusion for improved video generation.
For more technical details, check out the Research paper.
Safety
⚠️ Users should be aware of potential ethical implications: - Ensure you have the right to use reference videos and images, especially those featuring identifiable individuals. - Be responsible and transparent about generated content to avoid potential misuse for misinformation. - Be cautious about using copyrighted material as reference inputs without permission. - Avoid using the model to create videos that could be mistaken for real footage of individuals without their consent.
For more about ethical AI use, visit Tencent’s AI Ethics Principles.
Support
All credit goes to the Tencent AI Lab team Give me a follow on Twitter if you like my work! @zsakib_
Citation
@article{mimicmotion2024,
title={MimicMotion: High-Quality Human Motion Video Generation with Confidence-aware Pose Guidance},
author={Yuang Zhang and Jiaxi Gu and Li-Wen Wang and Han Wang and Junqi Cheng and Yuefeng Zhu and Fangyuan Zou},
journal={arXiv preprint arXiv:2406.19680},
year={2024}
}
Changelog
- Bug fix for
NoSuchFileerror