
zsxkib / seedvr2
🔥 SeedVR2: one-step video & image restoration with 3B/7B hot‑swap and optional color fix 🎬✨
zsxkib / humo

zsxkib / compare-image-editing-models
Easily compare the latest AI image editing models

zsxkib / embedding-gemma-300m
Turn any text into 768-dimensional vectors for search, classification, and AI apps 🧠✨

zsxkib / easyocr
Extract text with pixel coordinates from screenshots and images. GPU-accelerated, multi-language, perfect for camera-translation overlays.

zsxkib / outpainter-to-video
🎥 Outpaint videos (i2v) in each direction (top, bottom, left, right)

zsxkib / outpainter
🎨 Outpaint in each direction (top, bottom, left, right)

zsxkib / wan-2.2-unified
Unified interface for all Wan 2.2 video generation models with intelligent T2V/I2V switching

zsxkib / wan-2.2-with-sound
wan-video/wan-2.2 (all variants) + topazlabs/video-upscale + zsxkib/smart-thinksound

zsxkib / voxtral
Voxtral Mini (3B) + Small (24B)🎙️ Speech transcription and audio understanding in 8 languages🧠
zsxkib / seedance-1-with-sound
bytedance/seedance-1-(lite/pro) + topazlabs/video-upscale + zsxkib/smart-thinksound

zsxkib / audio-flamingo-3
🎧Advanced audio understanding with step-by-step reasoning📣
zsxkib / hailuo-02-with-sound
minimax/hailuo-02 + topazlabs/video-upscale + zsxkib/thinksound

zsxkib / smart-thinksound
Automatically generates expert ThinkSound prompts by analyzing your video w/ Claude 4 - no more struggling with complex audio descriptions
zsxkib / thinksound
Generate contextual audio from video using step-by-step reasoning🎶
zsxkib / multitalk
Audio-driven multi-person conversational video generation - Upload audio files and a reference image to create realistic conversations between multiple people
zsxkib / tool-merge-images
Merge multiple images into clean horizontal or vertical strips with precise alignment and sizing controls.

zsxkib / keep
🧼Upscales faces in videos look to be clearer and better using KEEP, Kalman-Inspired Feature Propagation for Video Face Super-Resolution

zsxkib / framepack
🕹️FramePack: video diffusion that feels like image diffusion🎥

zsxkib / dream-o
👗Bytedance's DreamO: unified image customization model (IP, ID, Style, Try-On, etc.)🧣

zsxkib / kimi-audio-7b-instruct
🎧 Kimi-Audio-7B-Instruct, ASR, audio reasoning, captioning, emotion sensing, and TTS into one universal model 🔊

zsxkib / step1x-edit
✍️Step1X-Edit by stepfun-ai, Edit an image using text prompt📸

zsxkib / dia
Dia 1.6B by Nari Labs, Generates realistic dialogue audio from text, including non-verbal cues and voice cloning

zsxkib / kimi-vl-a3b-thinking
Kimi-VL-A3B-Thinking is a multi-modal LLM that can understand text and images, and generate text with thinking processes

zsxkib / mmaudio-t4
Cost-optimized MMAudio V2 (T4 GPU): Add sound to video using this version running on T4 hardware for lower cost. Synthesizes high-quality audio from video content.

zsxkib / infinite-you
Transform your portrait photos into any style or setting while preserving your facial identity

zsxkib / wan-dissolve
zsxkib / wan-cakeify
zsxkib / wan-squish-1000steps

zsxkib / wan-squish-250steps
zsxkib / wan-squish-500steps
zsxkib / wan-squish

zsxkib / wan2.1-with-lora-h100

zsxkib / wan2.1-with-lora-t4

zsxkib / wan2.1-with-lora-l40s

zsxkib / wan2.1-with-lora-a100

zsxkib / wan-lora-trainer
📽️Fine-tune the Wan2.1 both 14b & 1.3b video model using video datasets🎥

zsxkib / step-video-t2v
Generate high-quality videos from text prompts using StepVideo

zsxkib / hibiki
Hibiki: High-Fidelity Simultaneous Speech-To-Speech Translation

zsxkib / star
STAR Video Upscaler: Spatial-Temporal Augmentation with Text-to-Video Models for Real-World Video Super-Resolution

zsxkib / bsrgan
Upscale videos + images with BSRGAN

zsxkib / create-video-dataset
Easily create video datasets with auto-captioning for Hunyuan-Video LoRA finetuning

zsxkib / stable-video-face-restoration
SVFR: A Unified Framework for Generalized Video Face Restoration
zsxkib / hunyuan-video-lora-rose-number-one-girl

zsxkib / hunyuan-video-lora
Hunyuan-Video LoRA Explorer + Trainer

zsxkib / mmaudio
Add sound to video using the MMAudio V2 model. An advanced AI model that synthesizes high-quality audio from video content, enabling seamless video-to-audio transformation.

zsxkib / memo
MEMO is a state-of-the-art open-weight model for audio-driven talking video generation.

zsxkib / hunyuan-video2video
A state-of-the-art text-to-video generation model capable of creating high-quality videos with realistic motion from text descriptions

zsxkib / jina-clip-v2
Jina-CLIP v2: 0.9B multimodal embedding model with 89-language multilingual support, 512x512 image resolution, and Matryoshka representations

zsxkib / samurai
SAMURAI: Adapting Segment Anything Model for Zero-Shot Visual Tracking with Motion-Aware Memory

zsxkib / allegro
Powerful text-to-video model that generates high-quality videos up to 6 seconds at 15 FPS and 720p resolution from simple text prompt

zsxkib / pyramid-flow
Text-to-Video + Image-to-Video: Pyramid Flow Autoregressive Video Generation method based on Flow Matching

zsxkib / flux-abstract-beings
Surrealist digital art featuring whimsical, anthropomorphic characters with exaggerated textures and vibrant color blocking

zsxkib / flux-caricature

zsxkib / molmo-7b
allenai/Molmo-7B-D-0924, Answers questions and caption about images

zsxkib / flux-music
🎼FluxMusic Text-to-Music Generation with Rectified Flow Transformer🎶

zsxkib / flux-dev-inpainting-controlnet
FLUX.1-dev Inpainting ControlNet model

zsxkib / flux-dev-inpainting
🎨 Fill in masked parts of images with FLUX.1-dev 🖌️
zsxkib / idefics3
Idefics3-8B-Llama3, Answers questions and caption about images

zsxkib / flux-schnell-inpainting
🎨 Fill in masked parts of images with FLUX.1-schnell 🖌️

zsxkib / aura-sr-v2
AuraSR v2: Second-gen GAN-based Super-Resolution for real-world applications

zsxkib / instant-id-ipadapter-plus-face
Make realistic images of real people instantly (w/ ip-adapter-plus-face_sdxl_vit-h)

zsxkib / mimic-motion
MimicMotion: High-quality human motion video generation with pose-guided control
zsxkib / instant-id-basic
Cubiq's ComfyUI InstantID node running `instantid_basic.json` example
zsxkib / whisper-lazyloading
Convert speech in audio to text w/ `tiny`, `small`, `base`, and `large-v3` models

zsxkib / aura-sr
AuraSR: GAN-based Super-Resolution for real-world

zsxkib / qwen2-1.5b-instruct
Qwen 2: A 1.5 billion parameter language model from Alibaba Cloud, fine tuned for chat completions

zsxkib / qwen2-7b-instruct
Qwen 2: A 7 billion parameter language model from Alibaba Cloud, fine tuned for chat completions

zsxkib / qwen2-0.5b-instruct
Qwen 2: A 0.5 billion parameter language model from Alibaba Cloud, fine tuned for chat completions

zsxkib / sd3-controlnet
✨Stable Diffusion 3 w/ ⚡InstantX's Canny, Pose, and Tile ControlNets🖼️

zsxkib / v-express
🫦 Realistic facial expression manipulation (lip-syncing) using audio or video

zsxkib / hololive-style-bert-vits2
🎙️Hololive text-to-speech and voice-to-voice (Japanese🇯🇵 + English🇬🇧)

zsxkib / wd-image-tagger
Image tagger fine-tuned on WaifuDiffusion w/ (SwinV2, SwinV2, ConvNext, and ViT)

zsxkib / ic-light-background
🖼️✨Background images + prompts to auto-magically relights your images (+normal maps🗺️)

zsxkib / blip-3
Blip 3 / XGen-MM, Answers questions about images ({blip3,xgen-mm}-phi3-mini-base-r-v1)

zsxkib / ic-light
✍️✨Prompts to auto-magically relights your images

zsxkib / flash-face
FlashFace: Human Image Personalization with High-fidelity Identity Preservation

zsxkib / animate-diff-scene-assembler
Dkamacho’s Scene Assembler

zsxkib / talknet-asd
🗣️ TalkNet-ASD: Detect who is speaking in a video

zsxkib / aya-101
📚 Aya, an LLM by Cohere capable of understanding and generating content in 101 languages 🗣️
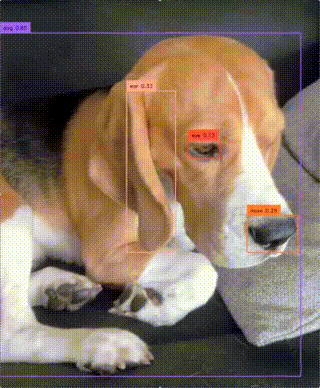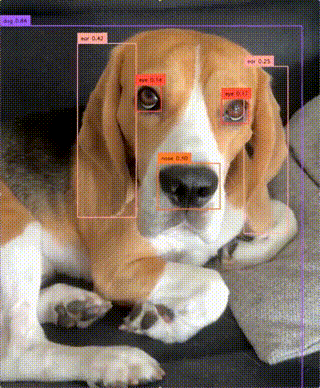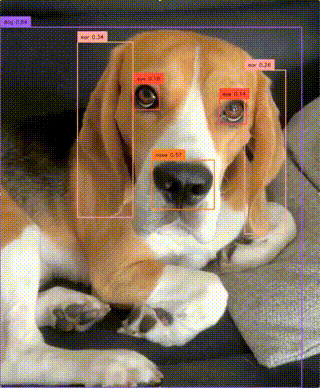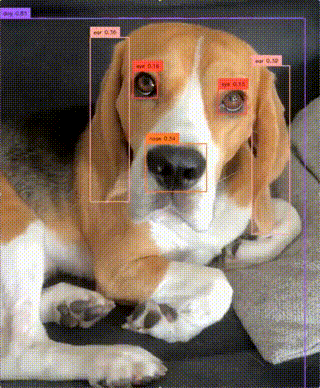
zsxkib / yolo-world
Real-Time Open-Vocabulary Object Detection

zsxkib / uform-gen
🖼️ Super fast 1.5B Image Captioning/VQA Multimodal LLM (Image-to-Text) 🖋️

zsxkib / instant-id
Make realistic images of real people instantly

zsxkib / moore-animateanyone
Unofficial Re-Trained AnimateAnyone (Image + DWPose Video → Animated Video of Image)
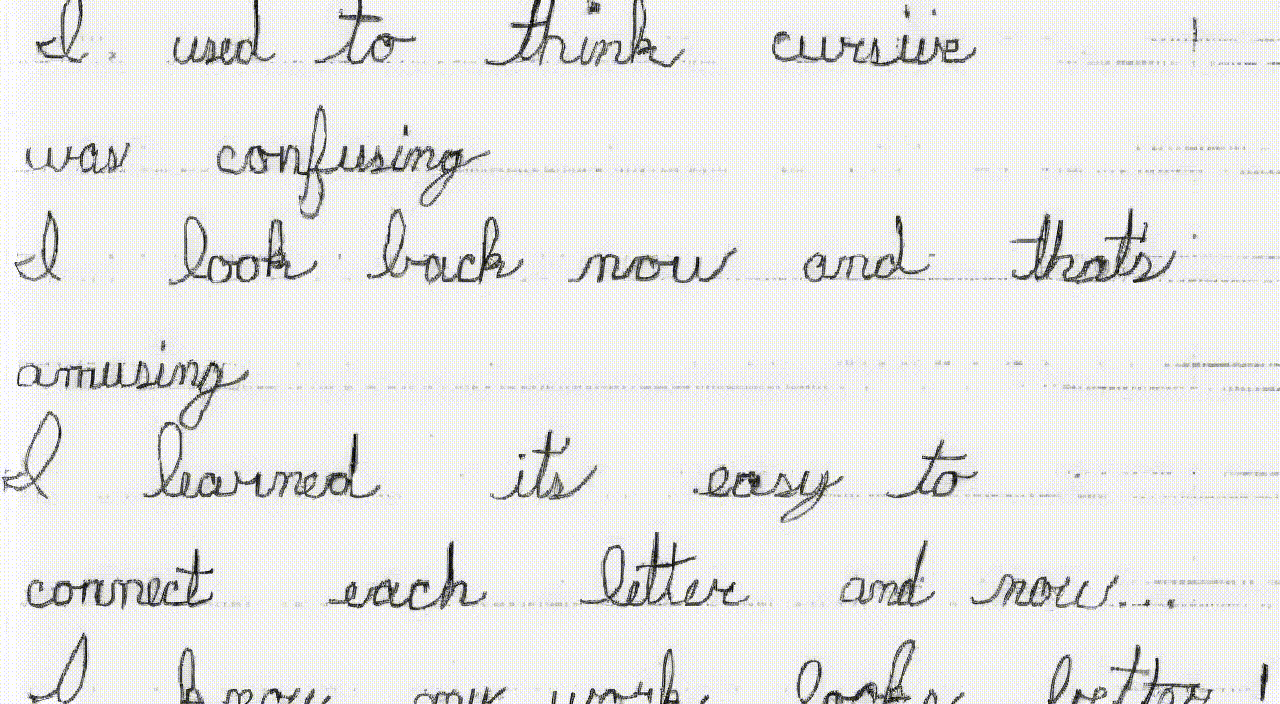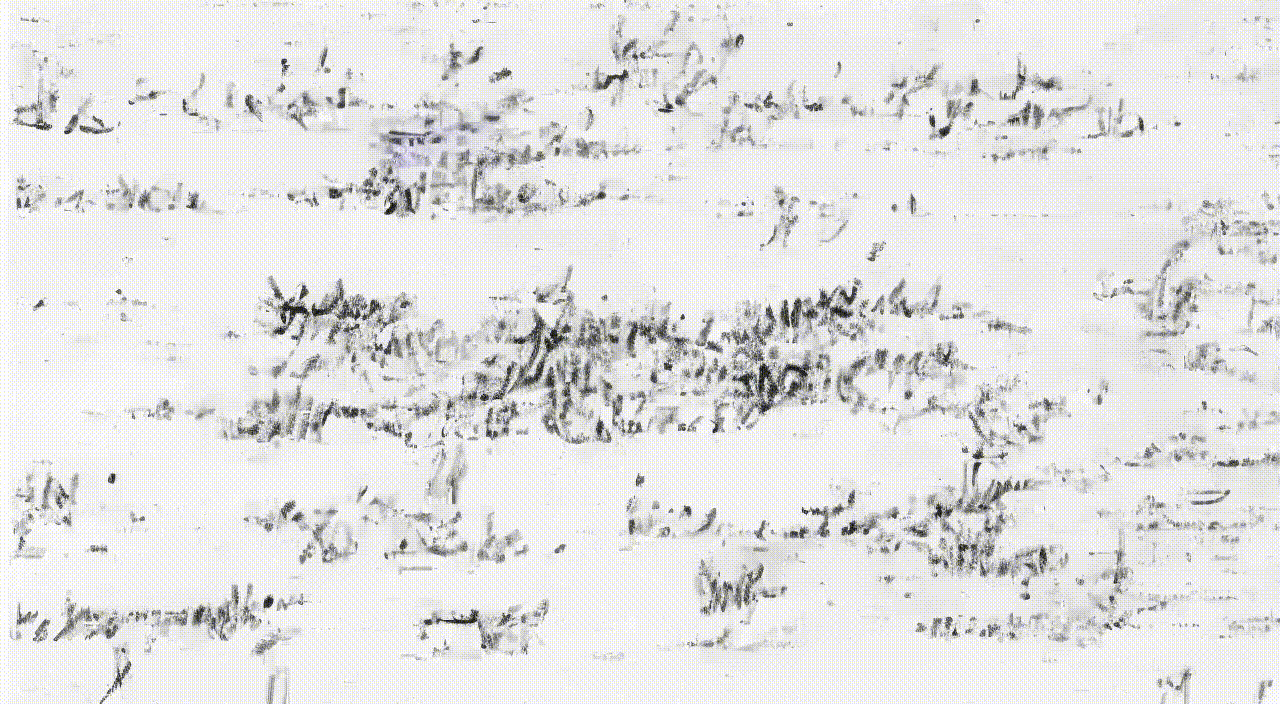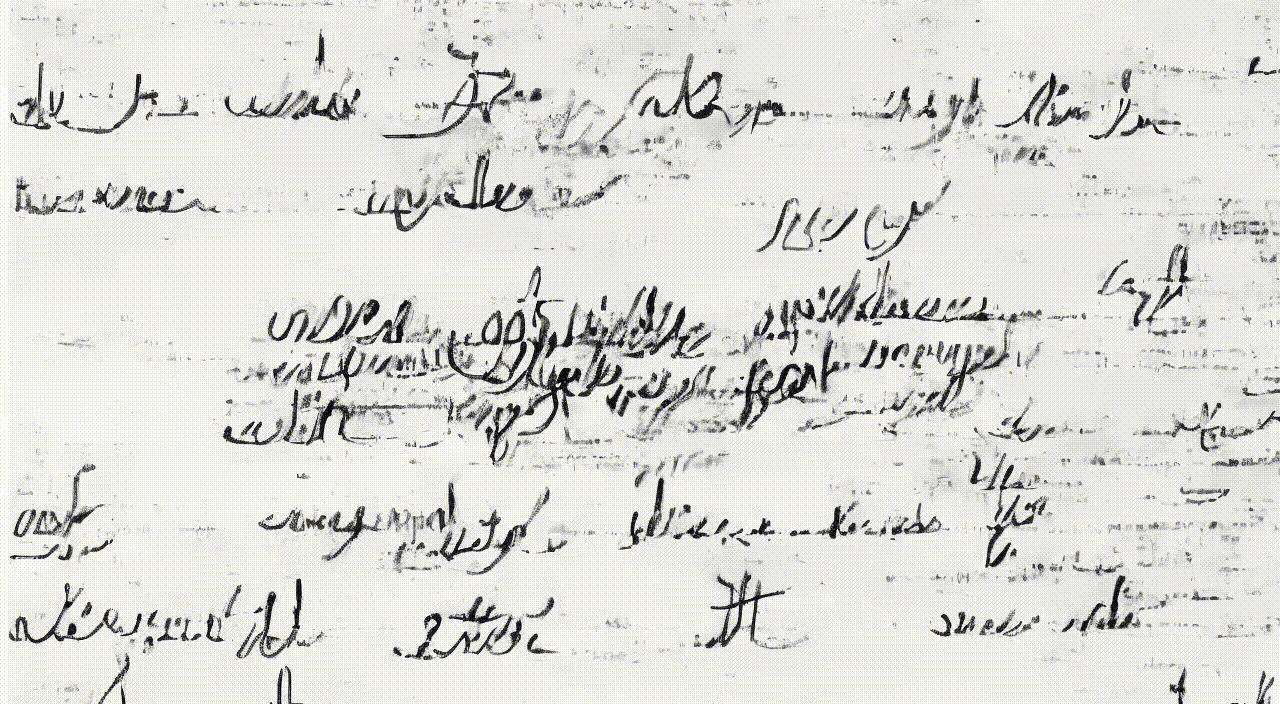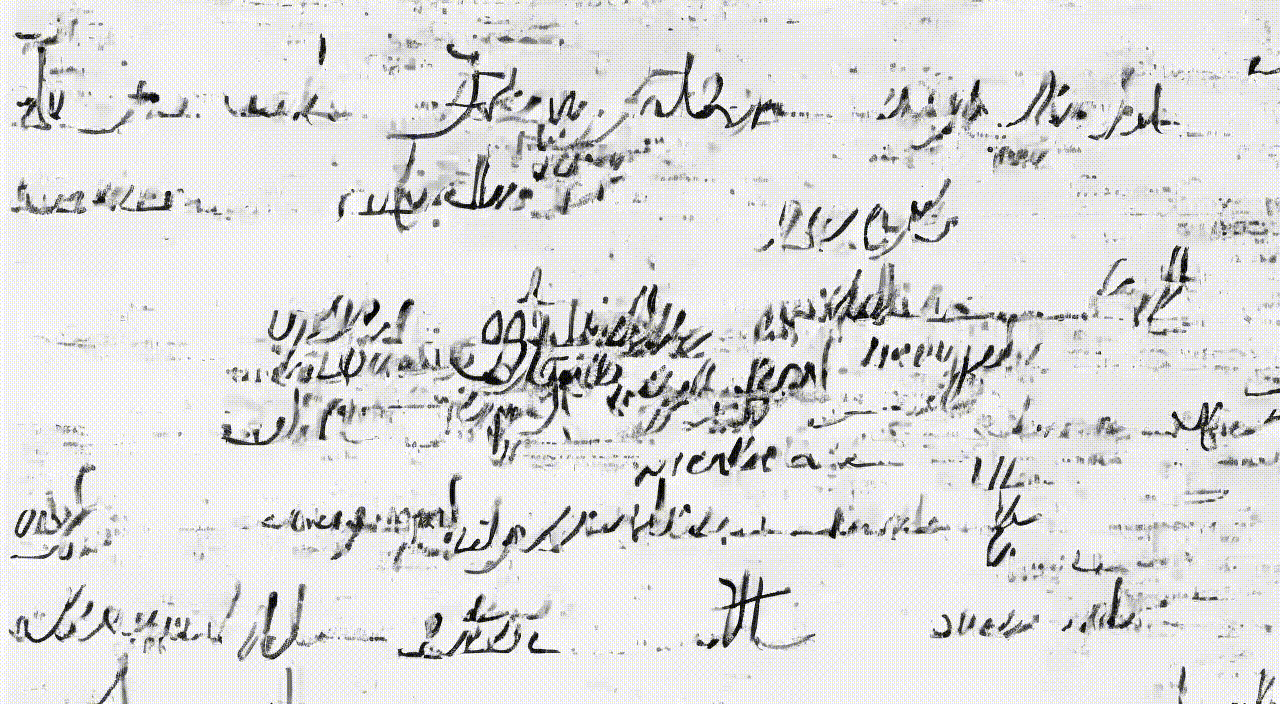
zsxkib / trocr-base-handwritten
🖋️➡️📱Converts handwritten text images into digital text
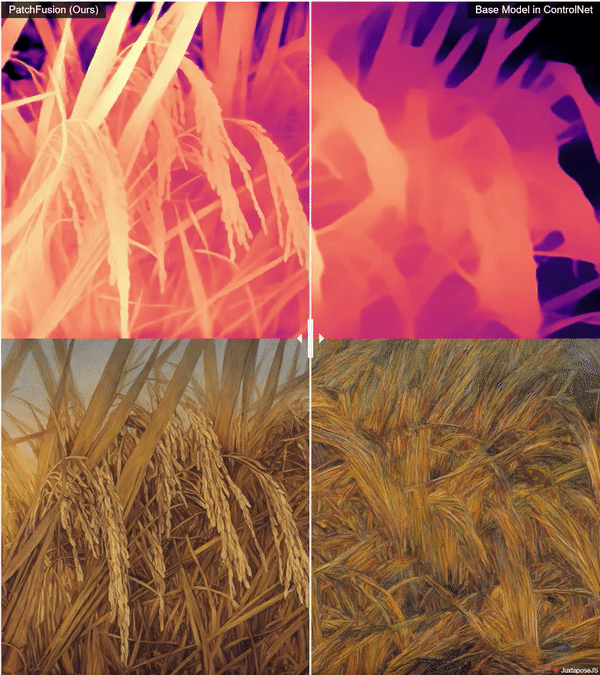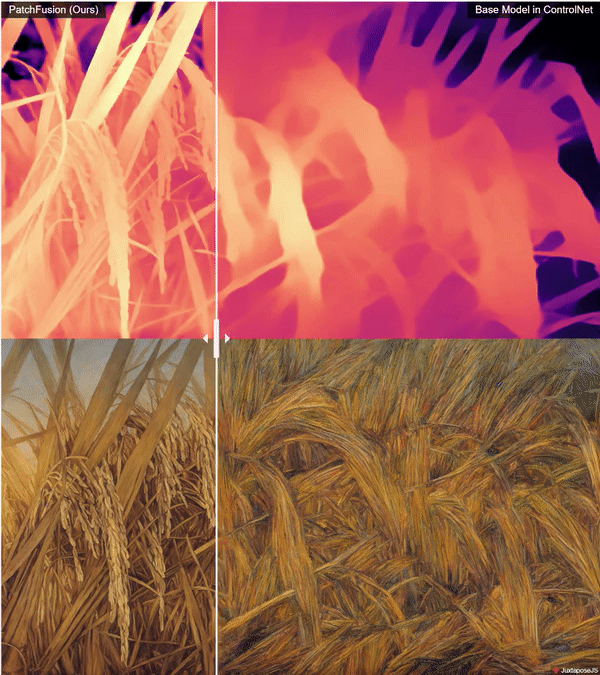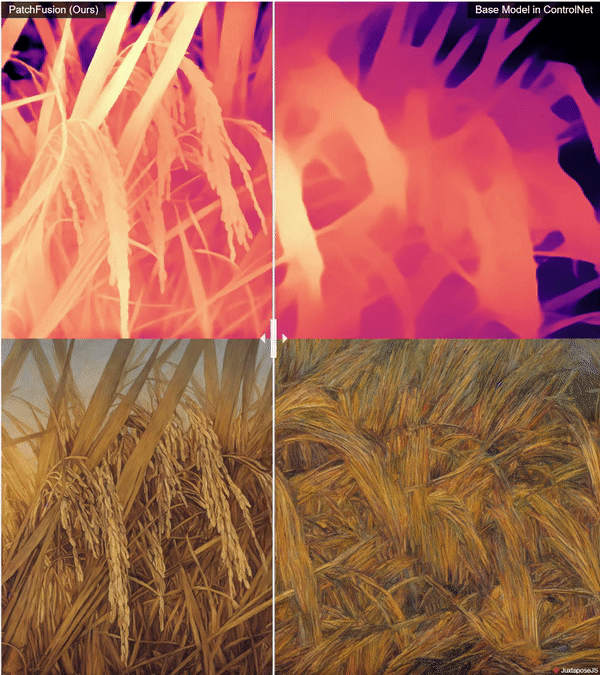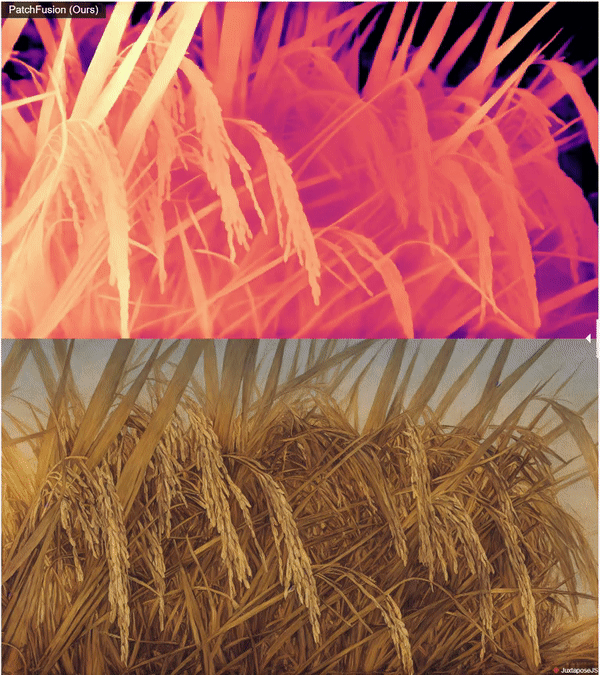
zsxkib / patch-fusion
Super High Quality Depth Maps 🗺️: An End-to-End Tile-Based Framework 🏗️ for High-Resolution Monocular Metric Depth Estimation 🔍📏

zsxkib / create-rvc-dataset
Create your own Realistic Voice Cloning (RVC v2) dataset using a YouTube link

zsxkib / realistic-voice-cloning
Create song covers with any RVC v2 trained AI voice from audio files.

zsxkib / stable-diffusion-safety-checker
Identifies NSFW images

zsxkib / film-frame-interpolation-for-large-motion
FILM: Frame Interpolation for Large Motion, In ECCV 2022.

zsxkib / animatediff-illusions
Monster Labs' Controlnet QR Code Monster v2 For SD-1.5 on top of AnimateDiff Prompt Travel (Motion Module SD 1.5 v2)

zsxkib / animatediff-prompt-travel
🎨AnimateDiff Prompt Travel🧭 Seamlessly Navigate and Animate Between Text-to-Image Prompts for Dynamic Visual Narratives

zsxkib / diffbir
✨DiffBIR: Towards Blind Image Restoration with Generative Diffusion Prior

zsxkib / animate-diff
🎨 AnimateDiff (w/ MotionLoRAs for Panning, Zooming, etc): Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning

zsxkib / st-mfnet
📽️ Increase Framerate 🎬 ST-MFNet: A Spatio-Temporal Multi-Flow Network for Frame Interpolation

zsxkib / draggan
🐲 DragGAN 🐉 - "Drag Your GAN: Interactive Point-based Manipulation on the Generative Image Manifold"

zsxkib / illuminati-diffusion
🧿 Illuminati Diffusion w/ Textual Inversion Embeddings 🧬
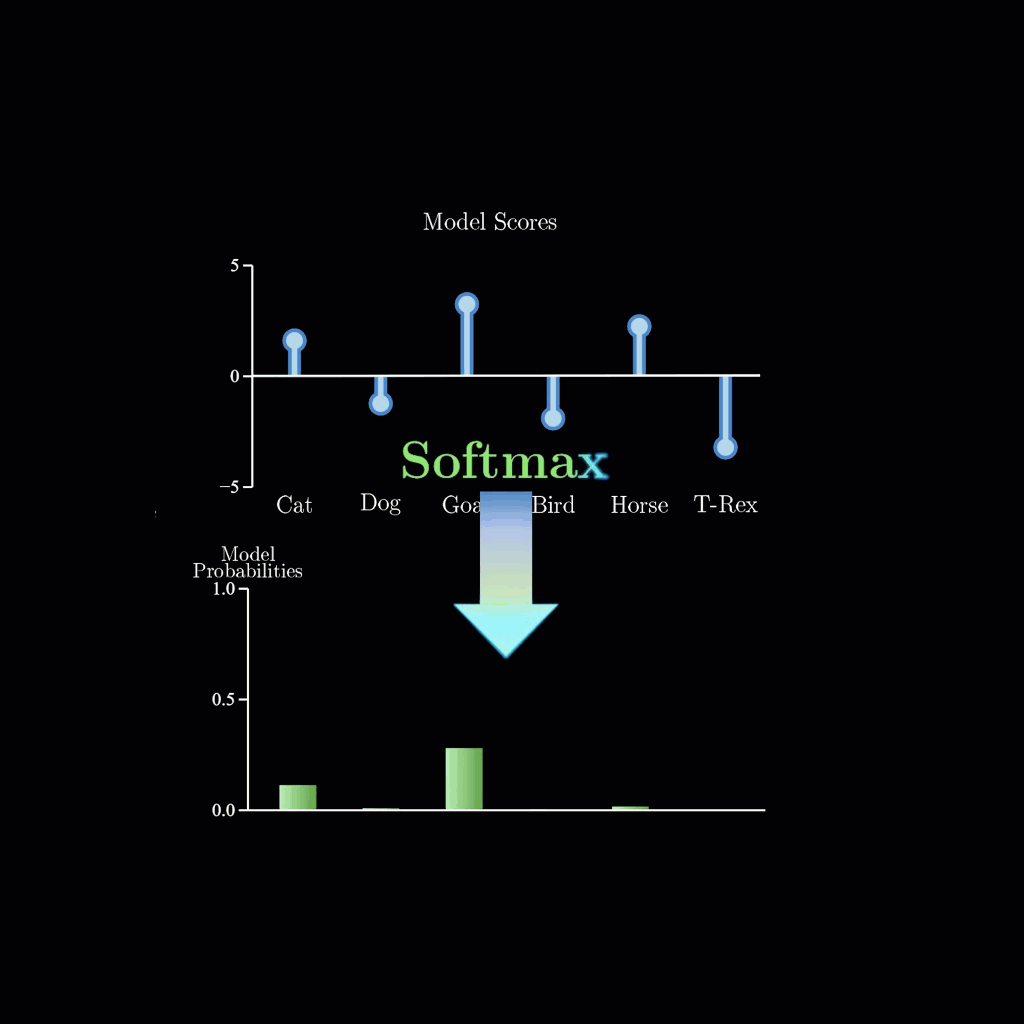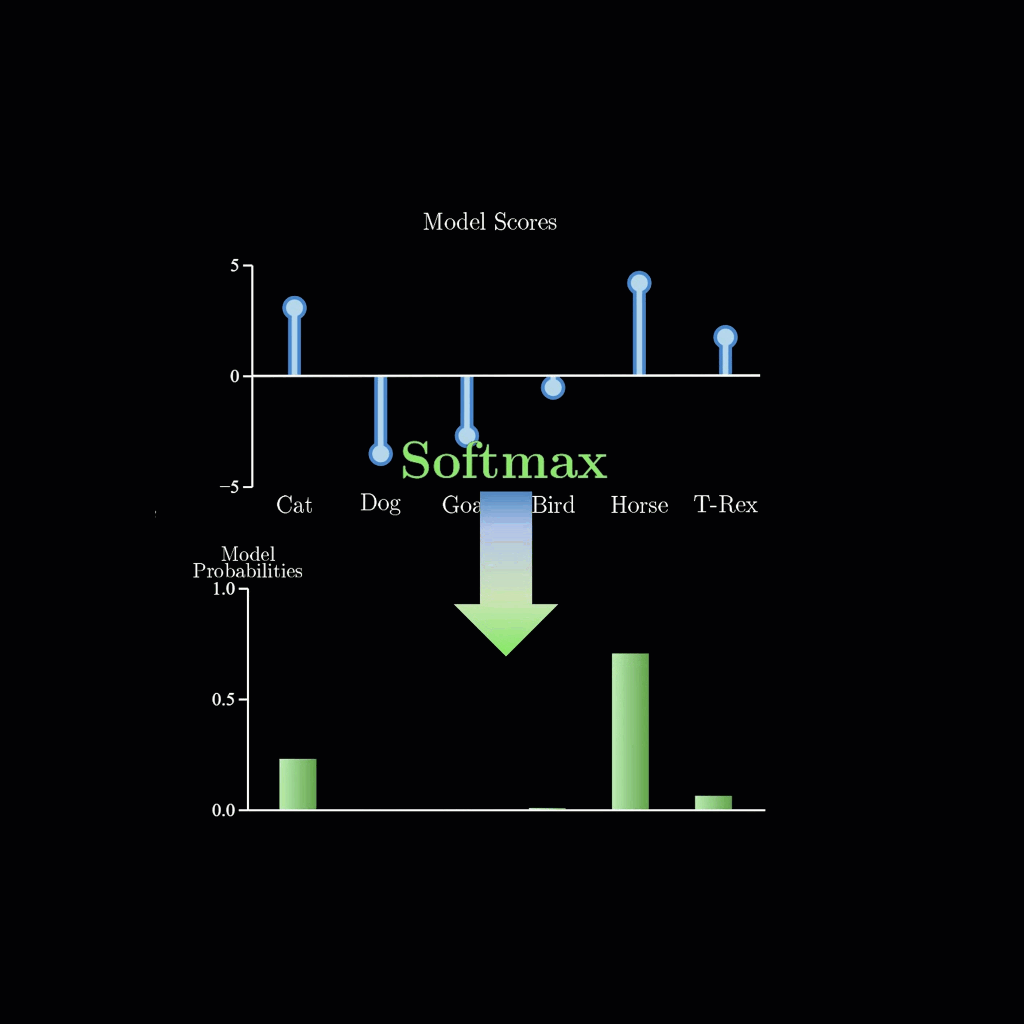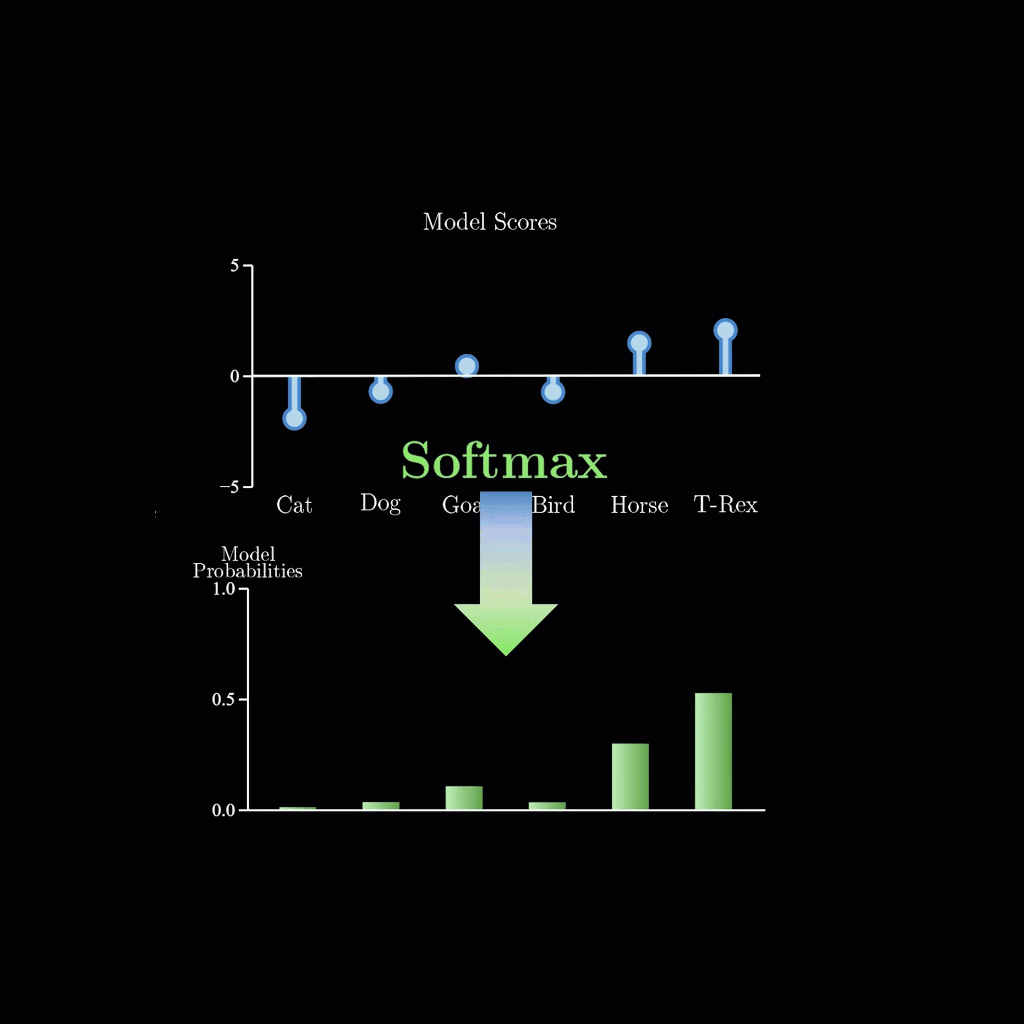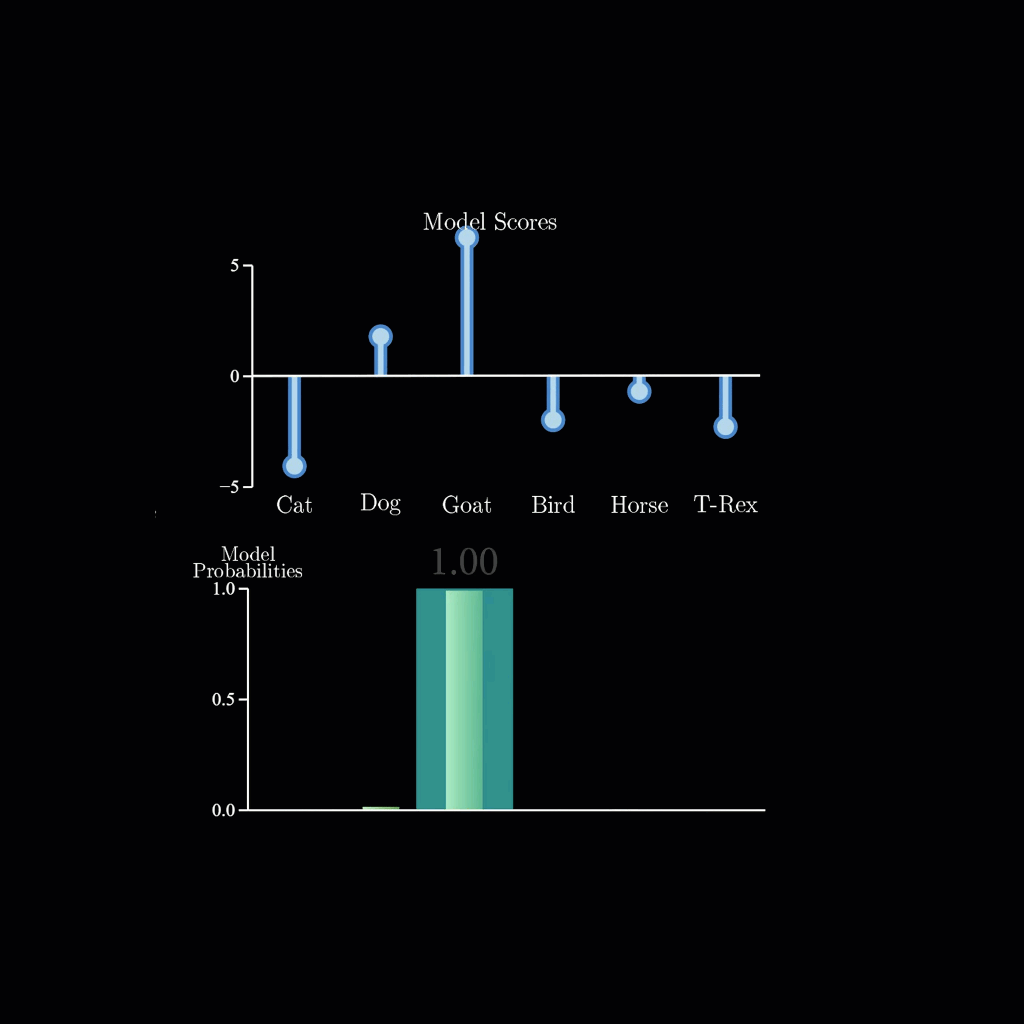
zsxkib / lil-flan-bias-logits-warper
Logit Warping via Biases for Google's FLAN-T5-small

zsxkib / clip-age-predictor
Age prediction using CLIP - Patched version of `https://replicate.com/andreasjansson/clip-age-predictor` that works with the new version of cog!

zsxkib / emotion2color
Transform your text into a beautiful two-tone color gradient that represents your emotions.

zsxkib / hello-world
A "Hello World" model for me to get to grips with `cog` and Replicate