-
Replicate now publishes agent skills, a collection of markdown instruction files that give coding assistants expert knowledge about working with AI models on Replicate.
Skills cover model discovery, comparison, and execution via the API, along with detailed prompting techniques for image generation and video generation models. They follow the open Agent Skills spec and work with Claude Code, OpenCode, OpenAI Codex, and other compatible tools.
Install
npx skills add replicate/skillsThis installs all of Replicate’s skills into your project and configures them for your coding assistant automatically.
Skills and MCP
Skills are complementary to Replicate’s MCP server. MCP gives your coding assistant API tools. Skills give it knowledge about how to use those tools well: which models to choose, how to write prompts, and what tradeoffs to consider.
For more details, see the agent skills reference or the GitHub repository.
-
Nano Banana Pro can now fall back to a backup model (currently ByteDance Seedream 5.0 lite) when Google’s API is at capacity, instead of failing with a rate limit error.
How it works
Set
allow_fallback_modeltotruewhen calling the API. If Nano Banana Pro hits a rate limit, it tries to generate the image with Seedream 5.0 lite instead. For certain inputs, for example if the aspect ratio isn’t supported, the original rate limit error is returned.The fallback is off by default. If you don’t set
allow_fallback_model, nothing changes — you’ll get a rate limit error when Google’s API is at capacity.When the fallback is triggered, your logs still show a prediction to Nano Banana Pro. You can tell the fallback was used by checking the
resolutionfield in your output — it says"fallback"instead of the actual resolution. You’re charged the cost of the fallback model, not Nano Banana Pro.Limitations
Our current fallback model, Seedream 5.0 lite, doesn’t support all the same options as Nano Banana Pro:
- Seedream 5.0 lite doesn’t support 1K resolution. If you request 1K, the fallback generates at 2K and downscales the result.
- Seedream 5.0 lite doesn’t support 4K resolution. If you request 4K, the fallback won’t be used and the original rate limit error is returned.
- Seedream 5.0 lite doesn’t support the
4:5and5:4aspect ratios. Requests with these ratios won’t fall back and will return the original rate limit error.
-
Replicate’s MCP server can now be discovered automatically through the official MCP Registry.
We added a
/.well-known/mcp/server.jsonendpoint that publishes metadata about the MCP server. This follows the server.json specification from the Model Context Protocol.How discovery works
The MCP Registry is the official metadata repository for MCP servers, backed by Anthropic, GitHub, and Microsoft. It doesn’t host code—just metadata that describes where to find servers and how to install them.
When you publish a
server.jsonfile at/.well-known/mcp/server.json, the Registry can discover your server automatically. MCP clients then use the Registry to find and install servers.Clients with built-in discovery
A few MCP clients have built-in marketplaces or directories:
-
VS Code has the best Registry integration. Enable
chat.mcp.gallery.enabledin your settings, then search@mcpin the Extensions view to browse and install MCP servers. -
Claude Desktop has a curated extensions directory at Settings > Extensions > Browse extensions.
Other clients like ChatGPT, Cursor, and LM Studio require manual configuration—you add the server URL or edit a config file yourself.
Code mode option
The metadata also exposes the
--toolsflag, which lets you choose between standard tools (all) or code mode (code) when installing. -
-
You can now filter the list predictions API endpoint to show only predictions created through the web interface.
Use the
sourcequery parameter with a value ofweb:curl -s \ -H "Authorization: Bearer $REPLICATE_API_TOKEN" \ "https://api.replicate.com/v1/predictions?source=web"This is useful if you want to see predictions you created using the playground or other parts of the Replicate website, separate from predictions created programmatically via the API.
Note: When filtering by
source=web, results are limited to predictions from the last 14 days. -
Web
- Improved the reliability of google/nano-banana and google/nano-banana-pro
- Improved accessibility when using the search bar across Replicate
Docs
- Added automatic llms.txt generation for documentation, making it easier for language models to discover and understand Replicate’s docs
- Published blog post on how to run Retro Diffusion’s pixel art models on Replicate, including rd-fast, rd-plus, rd-tile, and rd-animation for generating game assets and sprites
-
Web
- Added created and last updated dates on model pages
- Improved pricing display on model pages with clearer messaging for bring-your-own-token models and better visual consistency for single and multiple pricing tiers
- Made FLUX.2 [pro] the default model in the playground
- Added FLUX.2 models (pro, flex, and dev) to the playground
- Improved homepage hero section with clickable hero images that link to model pages, better mobile responsiveness, and reduced bundle size
- Improved mobile homepage hero legibility by adjusting gradient overlays
- Fixed model card text truncation and spacing on the explore page at smaller viewport sizes
- Updated playground to better adhere to platform rate limits
- Improved data retention banner messaging to clarify that failed predictions are not retained indefinitely
- Fixed support form reliability issues
- Fixed an issue where the navigation may have rendered incorrectly on mobile devices
Docs
- Published blog post on how to run FLUX.2 on Replicate, Black Forest Lab’s most advanced image generation model
- Published blog post on how to run Isaac 0.1 on Replicate, an open-weight vision-language model
-
Web
- Added approximate cost display to predictions and trainings on dashboard and predictions pages, showing how much each run costs
- Launched an updated homepage hero section and navigation
- Improved display of code snippets on the Replicate homepage
- Made Nano Banana Pro the default model in the playground
- Improved site search sorting, and improved keyboard shortcut handling
Cog
- Released Cog v0.16.9 with a fix for x-order bug
Docs
- Published blog post on how to prompt Nano Banana Pro with guidance on using its logic, text rendering, character consistency, and world knowledge capabilities
-
Replicate’s local MCP server now supports an experimental “code mode” that allows language models to write and execute TypeScript code directly in a sandboxed environment.
Instead of exposing individual API operations as separate tools, Code mode provides two tools: one for searching SDK documentation, and another for executing TypeScript code using the Replicate SDK within a Deno sandbox. The model uses a built-in docs search tool to learn how to write code against the SDK. This approach is more efficient for complex workflows that involve multiple API calls, as it reduces context window usage and allows the model to write custom logic that calls multiple methods and returns only the final results.
To use code mode, start the local MCP server with the
--code-modeflag:npx -y replicate-mcp@alpha --tools=codeHere’s how to add the local Replicate MCP server in code mode as a tool in Claude Code:
claude mcp add "replicate-code-mode" --scope user --transport stdio -- npx -y replicate-mcp@alpha --tools=codeCode mode is currently experimental and subject to change. It requires Node.js and Deno to be installed locally. Remote cloud sandboxing support is planned but not yet available.
To get started with Code mode, see the Code mode documentation or visit the demo GitHub repo.
-
Web
- Added video support to the before/after slider, allowing side-by-side comparison of video outputs from models like video upscaling and style transfer
- Added pixelated image rendering with size controls (1x, 2x, fit) in the playground for pixel art models
- Improved support for aspect ratios in prediction outputs
- Overhauled focus states across the Replicate UI library
- Add search to Deployments
- Fixed a bug that caused model input fields to display in a different order
- Added FAQs to every collection page
Platform
- Launched deployment setup monitoring for enterprise customers with automatic email notifications when deployments fail setup and customizable setup timeouts
Docs
- Published blog post about extracting text from documents with Datalab Marker and OCR with examples of structured extraction and performance benchmarks
-
Customers on an enterprise plan now have more control over their deployments with two new features: automatic notifications when deployments fail setup, and customizable setup timeouts.
Setup failure notifications
If a deployment fails during the model’s setup function, we’ll notify you via email. This helps you catch issues with your model earlier, before your users reach out.
If you use Slack, you can configure these emails to be sent to a Slack channel using their send emails to Slack feature.
Custom setup timeouts
You can customize the timeout for your deployment’s model setup function. The default timeout is 10 minutes, which works for most models. But if your model needs to download large files, load trained weights, or perform other expensive initialization operations, you can give it more time before we mark it as failed.

You can configure both of these in your deployment settings.
Read more in our deployment monitoring docs or reach out to sales@replicate.com to learn about our enterprise plans.
-
SDK
- Our Python SDK public beta is out now, making it even easier to run AI models from your Python code with full support for every operation in our HTTP API
Web
- Improved playground handling of different output and streaming types
- Fixed search keyboard shortcut in docs to use
Cmd+/on Mac andCtrl+/on Windows for consistency across platforms
API
- Launched prediction deadlines so you can automatically cancel predictions that don’t complete within a specified duration
- Added
sourcefield to prediction API responses to indicate whether predictions were created viaweborapi
Docs
- Split deployment monitoring into its own docs section with detailed information about metrics, GPU memory monitoring, and performance tracking
- Published blog post about how to prompt Veo 3.1 with guidance on reference images, frame control, and image-to-video features
-
You can now set a deadline to automatically cancel a prediction if it doesn’t complete within a specified duration. This is useful when you’re building real-time or interactive experiences, like a virtual try-on experience for an online clothing store. In this case, shoppers have usually moved on if an image takes more than 15 seconds to generate.
How it works
Set a deadline by including a
Cancel-Afterheader when creating a prediction. See our docs for details on the header format.Here’s an example that sets a 1 minute deadline:
curl -X POST \ -H "Authorization: Bearer $REPLICATE_API_TOKEN" \ -H "Cancel-After: 1m" \ -H "Prefer: wait" \ -H "Content-Type: application/json" \ -d $'{ "input": { "prompt": "The sun rises slowly between tall buildings. [Ground-level follow shot] Bicycle tires roll over a dew-covered street at dawn. The cyclist passes through dappled light under a bridge as the entire city gradually wakes up." } }' \ https://api.replicate.com/v1/models/bytedance/seedance-1-pro/predictionsWhat happens when a deadline is reached
Replicate sets the prediction’s status to
abortedif the deadline is reached before it starts running, andcanceledif the deadline is reached while it’s running.For public models, you’re only charged for predictions with a
canceledstatus, not forabortedones.Deadline vs sync mode wait duration
Prediction deadlines and sync mode serve different purposes. Use prediction deadline (
Cancel-Afterheader) to control when the prediction itself should be canceled. Use sync mode (Prefer: waitheader) to control how long the HTTP request stays open waiting for results.You can also use both together. In the previous cURL example,
Prefer: waitdefaults to 1 min and we’ve explicitly setCancel-Afterto 1 min. This means that the HTTP request will stay open for 1 minute to wait for results, after which the prediction will be canceled, even if it has not completed.Alternatively, setting
Cancel-After: 1mandPrefer: wait=10means that the request returns after 10 seconds. If the prediction is still running, you’ll get an incomplete prediction object, and the prediction will continue to run until it completes or is canceled at the 1-minute deadline.Read more in the docs:
-
Web
- Improved speed and performance across Replicate
- Updated dashboard UI with new navigation components for improved consistency
- Improved collection API filtering for better performance
- Made the Official label on model pages clickable, linking to the official models documentation
API
- Launched the ability to update model metadata via API with
PATCHrequests to update descriptions, README content, and links - Added sorting options to the models.list API to sort by model creation date or latest version date
Docs
- Expanded docs sidebar by default to make navigation easier
- Added comprehensive documentation about rate limiting when you have no payment method
- Published a blog post about IBM Granite 4.0 models now available on Replicate
- Updated getting started guides
Platform
- Added ability to download invoices from billing settings for both monthly billing and credit purchases
Cog
- Released Cog v0.16.8 with registry migration support and credential fallback
- Updated FastAPI requirement to support versions up to 0.119.0
- Fixed Go build issues with version control information injection
- Upgraded test dependencies including TensorFlow updates
-
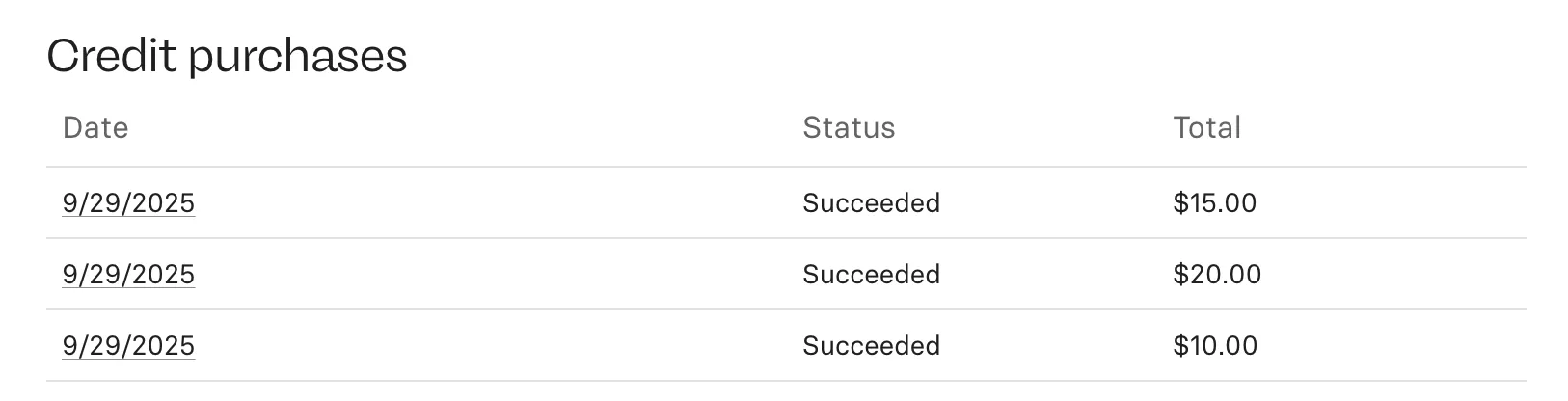
You can download PDFs of your invoices from billing settings.
If you’re billed through prepaid credit, click on any transaction date under Credit purchases to view that invoice.
If you pay monthly, click a specific month under Monthly usage to see a View invoice button next to Download JSON. This opens your invoice in Stripe.

-
The
GET /v1/modelsendpoint now supports sorting with thesort_byandsort_directionquery parameters. This makes it easier to fetch the newest models via the API.# Sort by when models were first created, newest first curl -s \ -H "Authorization: Bearer $REPLICATE_API_TOKEN" \ "https://api.replicate.com/v1/models?sort_by=model_created_at&sort_direction=desc"Sorting options
model_created_at: Sort by when the model was first createdlatest_version_created_at: Sort by when the model’s latest version was created (default)
Sort direction can be
asc(ascending, oldest first) ordesc(descending, newest first).The default behavior remains unchanged: models are sorted by
latest_version_created_atin descending order (newest versions first). -
You can now update model properties using the API with a
PATCHrequest to/v1/models/{owner}/{name}.You can update the following properties:
description- Model descriptionreadme- Model README contentgithub_url- GitHub repository URLpaper_url- Research paper URLweights_url- Model weights URLlicense_url- License URL
Example cURL request:
curl -X PATCH \ https://api.replicate.com/v1/models/your-username/your-model-name \ -H "Authorization: Bearer $REPLICATE_API_TOKEN" \ -H "Content-Type: application/json" \ -d '{ "description": "Detect hot dogs in images", "readme": "# Hot Dog Detector\n\n🌭 Ketchup, mustard, and onions...", "github_url": "https://github.com/alice/hot-dog-detector", "paper_url": "https://arxiv.org/abs/2504.17639", "weights_url": "https://huggingface.co/alice/hot-dog-detector", "license_url": "https://choosealicense.com/licenses/mit/" }'See the API reference for full details.
-
Web
- Updated playground to make it easier to use output images as inputs
- Improved load time and rendering of the homepage
- Added a link to the model detail page to view all predictions you’ve made with that model
API
- Launched a new search API (in beta) that makes it easier to find models, collections, and docs in a single call
Docs
- Published a comprehensive comparison of image editing models to help you choose the right tool for your project
- Moved “Deploy a custom model” to the get-started section for better discoverability
- Added new guide for optimizing models with Pruna to help you make models faster and cheaper
- Added documentation for throttling when you have low credit balance
- Updated rate limits error message format and clarified burst behavior in the API reference
- Enhanced the 404 page
- Fixed some visual inconsistencies, especially when using dark mode
Cog
- Updated Cog to support PyTorch 2.8.0 compatibility in v0.16.7
- Improved
cog initto download the latest agent instructions from docs - Added better support for Python 3.13 base images
-
We’ve added a new search API that makes it easier to find models, collections, and docs.
curl -s \ -H "Authorization: Bearer $REPLICATE_API_TOKEN" \ "https://api.replicate.com/v1/search?query=lip+sync"SDK support
The search API is available in our SDKs:
- TypeScript:
npm install replicate@alphaand usereplicate.search() - Python:
pip install --pre replicateand usereplicate.search() - MCP: Available in both our remote and local MCP servers
Backwards compatibility
The existing
QUERY /v1/modelsendpoint still works, but we recommend migrating to the new search endpoint for improved results.Read our announcement blog post for more details and example code.
- TypeScript:
-
Platform
- Added invoices for purchases of prepaid credit
- Launched torch compile caching with models using
torch.compilestarting 2-3x faster thanks to cached compilation artifacts - Added web URLs to prediction objects, so you can view predictions in your browser directly from API responses
Web
- Added related models to non-official model pages, to help you find similar models
- Fixed rendering issues with the display of remaining credits
- Added better support for models with video cover images
Docs
- Added a comprehensive Security topic with documentation on API token management, including automated token scanning and compromise detection
- Added a torch.compile guide with practical examples for improving model performance
- Added a new guide for optimizing models with Pruna
Cog
- Added torch 2.8.0 compatibility
-
torch.compilecan speed up your inference time significantly, but at the cost of slower startup times. We’ve implemented caching oftorch.compileartifacts across model instances to help your models boot faster.Models using
torch.compilelike black-forest-labs/flux-kontext-dev, prunaai/flux-schnell, and prunaai/flux.1-dev-lora now start 2-3x faster.In our tests of inference speed with black-forest-labs/flux-kontext-dev, the compiled version runs over 30% faster than the uncompiled one, making
torch.compilean important feature to explore.For more details, check out the blog post. If you’re building your own custom models, check out our guide to improving model performance with
torch.compile.To learn more about how to use
torch.compile, check out the official PyTorch torch.compile tutorial. -
- Added Artificial Analysis image and video arena rankings to search results
- Added email verification when signing up for an organization
- Improved rendering of the billing summary on the dashboard
- Continued improving the site navigation across Replicate
- Cleaned up filtering options on the prediction list to make it easier to navigate
- Fixed a bug that may have caused filenames to overflow on the playground
- Fixed a bug when fetching a model’s readme while using an Accept header
- Fixed a bug that may have caused dropdowns to appear incorrectly on Microsoft Edge when using dark mode
- Enhanced radio button visibility on model create with better contrast
- Standardized number formatting across the platform to use consistent en-US locale
- Fixed avatar menu username visibility across different screen sizes
- Improved link underlines in blog posts for better readability and visibility
-
Web
- Overhauled the model page header to make it easier to find what you’re looking for
- Updated the Replicate homepage with the freshest model data
- Tweaked the predictions interface to make filtering clearer
- Continued improving search results, including a bug that led to 404’s on collections, and where video models were not displaying correctly
- Improved docs search results interface
Cog
- Updated Node.js starter guide to user newer models.
- Added docs about secret inputs for model authors and model users.
- Added docs about community models.
- Added docs for using Replicate MCP in Google Gemini CLI
- Added docs for using Replicate MCP in OpenAI Codex CLI
- Guides are now organized into categories: Run models, Build models, Go deeper.
API
- Fixed the deployments.update API to return updated deployment config.
- Released mcp.replicate.com, a remote MCP server for Replicate’s HTTP API
-
You can now use the
POST /v1/predictionsHTTP API endpoint to run any model on Replicate, whether it’s an official model or a community model. This removes the confusion about which endpoint to use for different types of models.What changed?
The
POST /v1/predictionsendpoint now accepts official model identifiers in theowner/nameformat, in addition to the existing{owner}/{name}:{version_id}and{version_id}formats.The existing
POST /v1/models/{model_owner}/{model_name}/predictionsendpoint will still be supported for running official models. If you’re already using that endpoint, you don’t need to change anything.This change is backward compatible. Existing code will continue to work without any modifications.
Supported version identifiers
When using the
POST /v1/predictionsendpoint, you can specify models in these formats:{owner}/{name}- For official models (e.g.,black-forest-labs/flux-schnell){owner}/{name}:{version_id}- For community models with full version ID (e.g.,replicate/hello-world:9dcd6d78e7c6560c340d916fe32e9f24aabfa331e5cce95fe31f77fb03121426){version_id}- Just the 64-character version ID (e.g.,9dcd6d78e7c6560c340d916fe32e9f24aabfa331e5cce95fe31f77fb03121426)
Example
Here’s an example of how to run an official model (in this case,
black-forest-labs/flux-schnell) using thePOST /v1/predictionsoperation:curl -X POST https://api.replicate.com/v1/predictions \ -H "Authorization: Token $REPLICATE_API_TOKEN" \ -H "Content-Type: application/json" \ -d '{ "version": "black-forest-labs/flux-schnell", "input": { "prompt": "A photo of a cat" } }' -
Web
- Rolled out a new search experience across Replicate
- Added a new enterprise page
- Added support for filtering models in the playground
- Fixed a bug where dark mode may not have been sticky in certain circumstances
- Fixed a bug where creating a model might silently fail
- Fixed a bug with using keyboard shortcuts in playground causing unexpected results
- Improved 404 pages
- Improved pricing display for models
Cog
- Added support for python 3.13 base images
Models
- Veo-3 now supports 1080p
- Kontext LoRA trainer now supports up to 20k steps
-
You can now purchase prepaid credit for your Replicate account. This is a helpful option if you want to manage your spending more proactively. It can also make paying for Replicate easier if your bank requires additional authentication for recurring charges.
Since July 16, 2025, all new accounts are being billed through prepaid credit instead of being billed monthly. For existing users who signed up before July 16, nothing changes if you don’t want it to. You can continue to get billed monthly - no action required.
At some point in the future, we will be migrating most accounts from monthly billing to prepaid credit. We’ll work with you to make the transition as smooth as possible and will share more details as our plans develop. If you want to move from monthly billing to prepaid credit sooner, email support@replicate.com.
To purchase credit:
- Visit replicate.com/account/billing (or click your avatar → Account settings → Billing).
- Choose Add credit and follow the prompts.
- Optionally, set up auto reload to add to your credit balance when it dips below a preset threshold.
Once you purchase credit, any usage will be deducted from that credit balance. If you run out of credit, we’ll charge you for any overages at the beginning of the following month.
For more details, see our prepaid credit docs.
-
We are introducing a new implementation of Cog’s production runtime component. This is the part of Cog responsible for predictor schema validation, prediction execution and HTTP serving.
tl;dr:
If you’re a model author and want to try out the new runtime, make sure you’re on Cog >= 0.16.0 and add
build.cog_runtime: truetocog.yaml:build: # Enable new Cog runtime implementation cog_runtime: trueMost existing models should work as is, apart from a few exceptions. If you hit one of the exceptions, please follow the messages printed by
cogto update your code. Read below for why these are necessary.Note that:
- The experimental training interface is not supported yet.
- This new runtime will become the default in a future Cog release, after which the existing one will be deprecated.
Why build this?
The existing Cog runtime was written in Python and relies heavily on Pydantic and several other libraries when performing predictions. This leads to several problems:
- Dependency issues: many Python libraries pull in conflicting versions of common dependencies, e.g. Pydantic. This causes runtime errors, sometimes even by just rebuilding the image which pulls a newer version of the dependency. By removing all Python dependencies from Cog runtime, you have total control of your model’s dependency graph.
- Ambiguous predictor interface: we relied on Pydantic for checking predictor input and output types, which can be ambiguous and error prone, e.g. allowing types that may be handled incorrectly by other parts of our ecosystem or user code. It’s also hard to support custom data types due to potentially incompatible Pydantic versions, i.e. v1 vs v2.
- Error handling: since Cog HTTP server and predictor are both Python code running via
multiprocessing, it’s hard to differentiate platform errors, i.e. Cog, vs application errors, i.e. predictor. A model crash may cause the server to end up in a bad state with no useful logging. - Performance: certain things are hard to implement correctly and efficiently in Python, i.e. async HTTP handling, file upload & download, concurrency, serialization.
To tackle these problems, we re-implemented the runtime part of Cog with the following components:
- Schema validation in pure vanilla Python via
inspectand no Pydantic or any other dependency - Decoupled HTTP server rewritten in Go
- Custom, pluggable data serialization
This allows us to minimize the runtime logic in Python and reduce the risk of it interfering with application code. The Go server is now responsible for most of the heavy lifting:
- HTTP server and webhooks
- Input file download and output file upload
- Logging
The Go server communicates with the bare minimum Python runner via JSON files for input/output and HTTP/signals for IPC. The Python runner is solely responsible for invoking the predictor’s
setup()andpredict()methods.What do I need to change?
Most of the Cog API,
Predictor,Input,BaseModel, etc. are source compatible. There are 3 changes that might require updating the model.- Improved semantics of optional inputs
- Cleaner dependencies
- Removal of deprecated File API.
First, ambiguous optional inputs are no longer allowed. For example, in existing Cog, declaring
prompt: strsuggests that it cannot beNone, while it still allowsdefault=None, which can confuse type checkers and lead to buggy code, e.g. if it doesn’t check for none-ness. For example, instead of:def predict(prompt: str=Input(description="prompt", default=None))We should use:
def predict(prompt: Optional[str]=Input(description="prompt")Note that
default=Noneis now redundant and removed, asOptional[str]implies that the input may beNone, and type checker can warn us about checking it.Second notable change is that the new Cog runtime no longer depends on any of the Python dependencies of the existing runtime. You’ll have to add them to
requirements.txtif the model relies on them and they’re not pulled in via any other third party libraries.- attrs
- fastapi
- pydantic
- PyYAML
- requests
- structlog
- typing_extensions
- uvicorn
Third change is the removal of deprecated
cog.FileAPI. Usecog.Pathinstead. -
Web
- Simplified creating a model on Replicate, to be more focused on the task you’re trying to complete
- Added better support for models with videos for cover images, like zsxkib/thinksound
- API tokens page now displays enabled tokens first, and disabled tokens last
- Updated invoices to more clearly show charges under $0.01
- Improved hardware display on model pages
- Improved visibility of focus states for keyboard accessibility across Replicate
- Fixed a bug where the platform status might be hard to read
- Fixed an issue where the total time a prediction ran was not displayed on the prediction page
- Added clipping support for models with outputs that compare images
Cog
- Added
Optionaldocumentation - Added torch 2.7.1 and cuda 12.8 base images
-
Web
- Updated
llms.txtfiles for models to indicate required vs optional inputs. (Here’s an example.) - Launched environment variables in running containers
- All API operations in our OpenAPI schema now have defined response schemas
- Fixed an issue where uploading an image on the API playground could cause the page to jump
- Improved the display of pricing information on model pages
- Added support for multi-string inputs on Replicate playground
- Improved the display of billing information on the dashboard
Cog
- Fixed binary data URLs not outputting anything on
cog predict cog predictnow has support for JSON inputs and outputs with-json- Errors are explicit when the user tries to push an image without a token
- python 3.13 is now the default in
cog init
Docs
- Added documentation on official models
- Added documentation on error codes
- Updated
-
The ability to set a monthly spend limit on your account has been deprecated. If you require this feature, reach out to support.
-
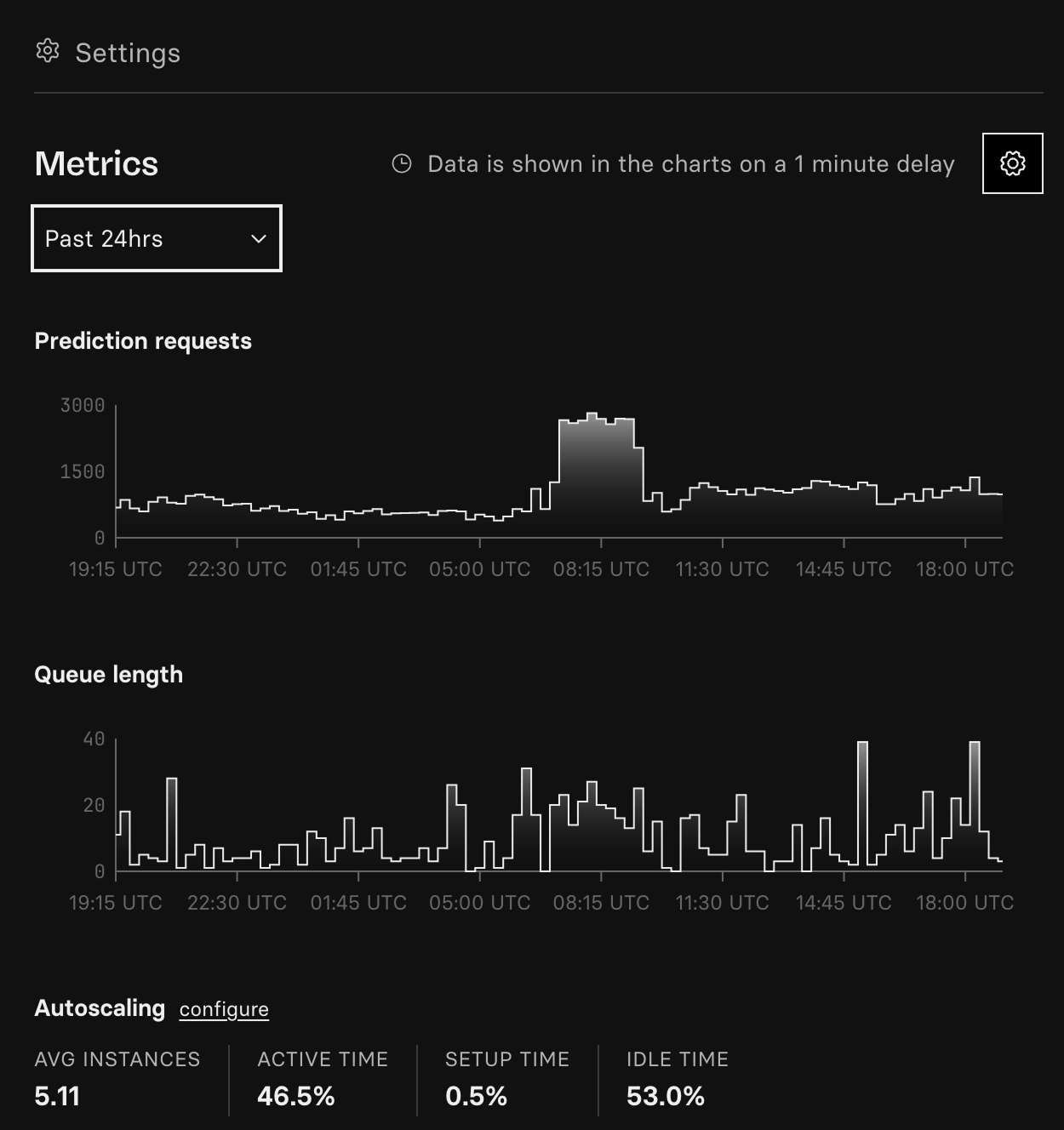
You can now view a full 24 hours of metrics on a deployment’s page — up from the previous 2-hour limit. We’ve widened the aggregation window to 15 minutes (from 1 minute) so the longer view loads quickly and avoids timeouts.
-
Platform
- Improved navigation consistency across Replicate
- Added
.mdextensions to docs, like this one - Added a link to view a prediction upon creation in the API playground, in order to make it easier to run multiple long running predictions
- Added support for more video formats in the API playground, like WEBM
- Fixed an issue that caused sharing links on social platforms to render incorrectly
- Fixed a rendering issue where the footer was displaying incorrectly on some pages
- Fixed some minor rendering issues with the playground UI
Cog
- Fixed binary data URLs not outputting anything on
cog predict cog predictnow has support for JSON inputs and outputs with-json- Errors are explicit when the user tries to push an image without a token
- python 3.13 is now the default in
cog init
-
We now expose the following metadata as environment variables in a running container.
They can be used to identify the image, version, deployment, when debugging or instrumenting your model.
REPLICATE_USERNAME- username, e.g.my-unicorn-ai-startupREPLICATE_MODEL_NAME- model name, e.g.pony-generatorREPLICATE_DOCKER_IMAGE_URI- Docker image URI, e.g.r8.im/<username>/<model_name>@<image_hash>REPLICATE_VERSION_ID- model version, usually the same as image hashREPLICATE_DEPLOYMENT_NAME- deployment name, if running as a deployment
These environment variables are accessible to your code in public models, private models, and deployments.
For more details, see the model documentation.
-
To improve performance when using tools like Replicate’s MCP server, we’ve updated our public API to return smaller response objects for model metadata.
This change removes about ⚡️ 5KB ⚡️ from every serialized model object.
For API operations that return multiple models like
models.searchandcollections.get, this change shaves over 1MB off the response size, dramatically improving the performance and response times for LLMs that are consuming these data.What’s changed?
Every Replicate model has its own OpenAPI schema that defines all of its inputs and outputs. This metadata is incredibly useful, as it tells you exactly what you can do with the model, and it’s documented in a machine-readable and industry-standard JSON Schema format.
Model input and outputs schemas are great, but these OpenAPI schemas also include some metadata that is not useful or relevant. Specifically, the
openapi_schema.pathskey contained unnecessary metadata that is only useful inside Cog’s internal generated FastAPI client. To reduce the size of the generated responses, we’ve removed this key from the version object and replaced it with an empty object. This results in an OpenAPI schema that is still valid, but much smaller.Which API operations are affected?
This change affects all API operations that return model version metadata, including:
models.get- Get a modelmodels.list- List public modelsmodels.search- Search public modelsmodels.versions.get- Get a model versionmodels.versions.list- List model versionscollections.get- Get a collection of modelscollections.list- List collections of models
-
Platform
- Tweaks and updates to the site navigation across Replicate
- Added a last pushed date to the model card to make it easier to check recency in a collection
- Launched improved pricing display for official models
- Launched new FLUX.1 Kontext models from Black Forest Labs, and Veo 3 from Google
- Speed and caching improvements for the most popular model weights and FLUX LoRAs
Docs, talks, and blog posts
-
You can now fine-tune models with the fast FLUX trainer on Replicate.
It’s fast (under 2 minutes), cheap (under $2), and gives you a warm, runnable model plus LoRA weights to download.
We’ll be open-sourcing our work soon — stay tuned.
-
Platform
- Added audio and streaming text support in playground
- Added “Iterate in the playground” links to more supported models
- Added a “More by this user” dropdown to model pages
- Added the ability to copy model content directly to LLMs
- Added support for viewing PDF files in the API playground
- Updated the model header and tweaked layout
- Updated blog and changelog layouts to improve readability
- Fixed a broken image preview when uploading PDF’s in the API playground
Docs
- Added Replicate MCP server and guide
Web
- The API tokens view under account settings now takes an optional
?new-token-namequery param, so you can send someone to that page with a suggested name for their new token. For example, usingmy-cool-app: https://replicate.com/account/api-tokens?new-token-name=my-cool-app.
Partnerships
- We’ve partnered with Hugging Face to bring Replicate inference to their platform.
Cog
- Proper support for nullable fields in OpenAPI schemas
- Cog train can now use classes like
cog predictinstead of just functions. This change enables you to use asetupcall to prepare your model and atraincall to train it. By using this pattern you can cut down on boot times if you are running multiple model trainings.
-
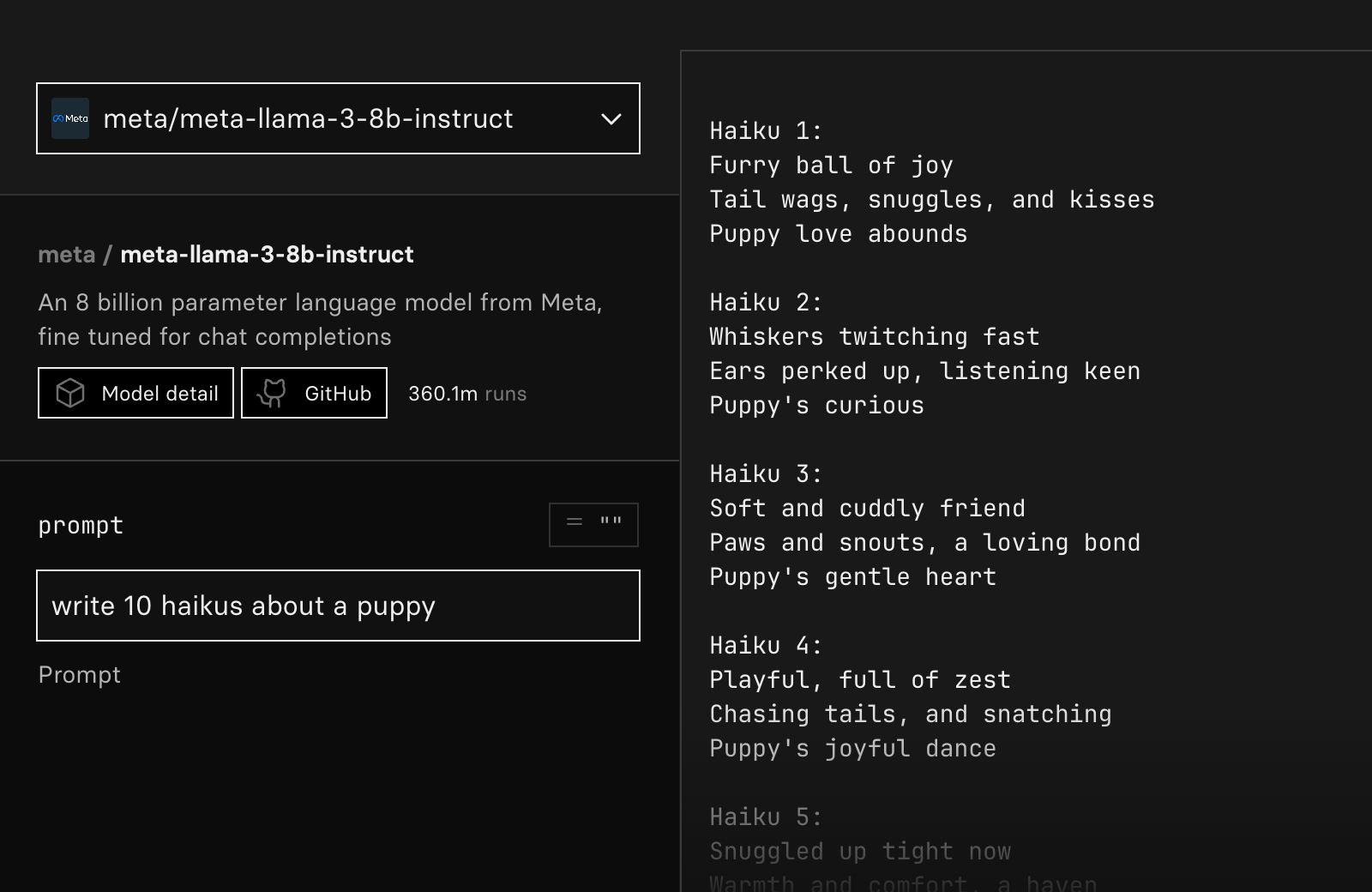
The playground now supports models that output and stream text, so you can quickly compare different language models and play with models like salesforce/blip and yorickvp/llava-13b.
-
We’ve added a new
webproperty to theurlsobject for predictions.This property contains the web URL of the prediction, so you can view it in your browser:
{ "web": "https://replicate.com/p/cky59275mdrm80cpw83rcn3ej0", "get": "https://api.replicate.com/v1/predictions/cky59275mdrm80cpw83rcn3ej0", "stream": "https://stream.replicate.com/v1/files/bcwr-3afcgaxf5opqtgeq5ababozl3erroi6ody73lpkwklvnu7bwtmrq", "cancel": "https://api.replicate.com/v1/predictions/cky59275mdrm80cpw83rcn3ej0/cancel" }Here’s an example of how to get the web URL of your account’s most recent prediction using cURL and jq, then open it in your browser:
curl -s \ -H "Authorization: Bearer $REPLICATE_API_TOKEN" \ "https://api.replicate.com/v1/predictions" \ | jq ".results[0].urls.web" \ | xargs open -
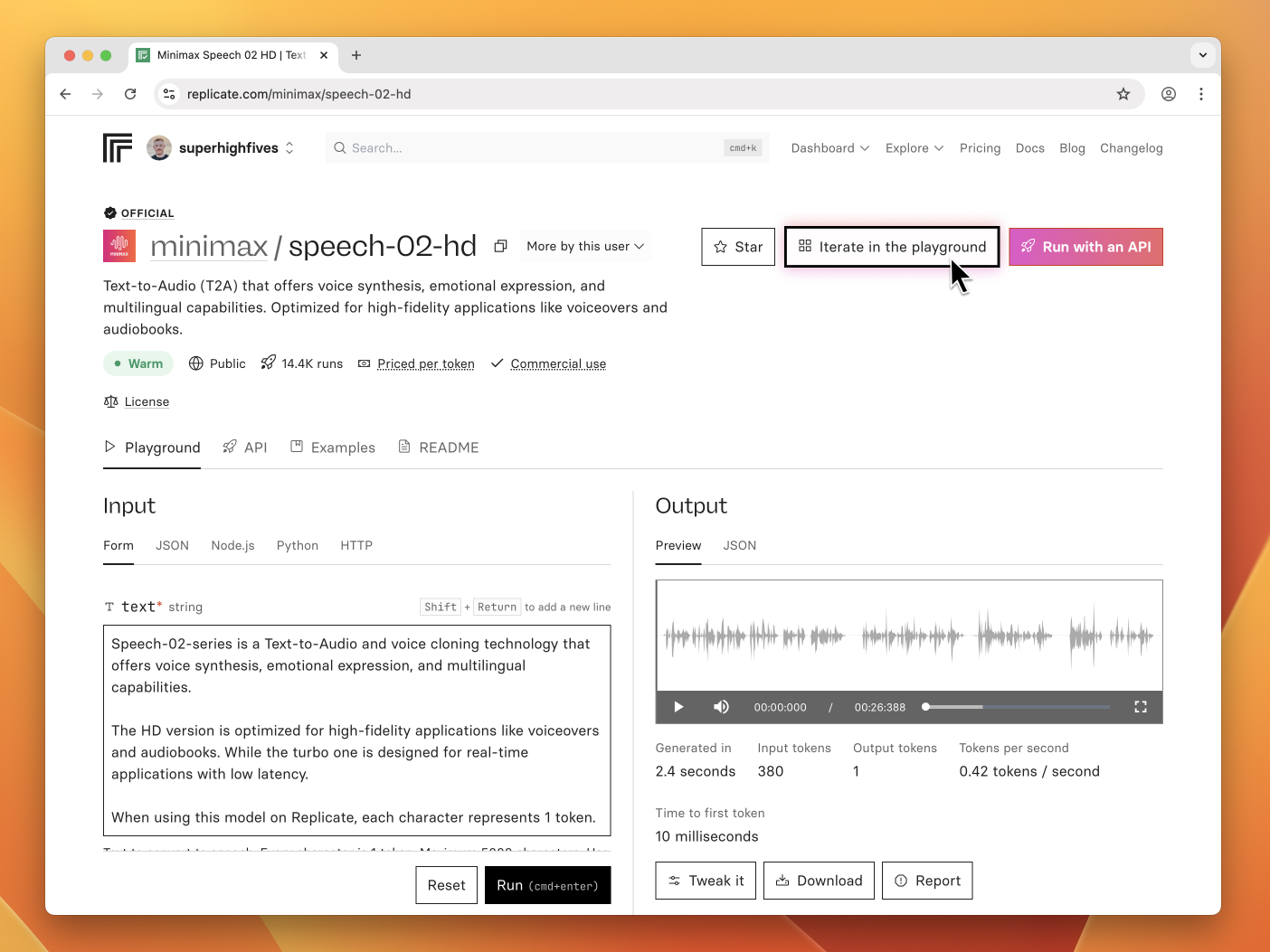
You can now quickly get from a model to iterating on it in the playground. Use the “Iterate in the playground” button on any supported model page.
The playground also now supports previewing audio, so you can generate and listen to audio in the same place.
-
You can now run models and training on NVIDIA H100 GPUs on Replicate.
Multi-GPU configurations (2x, 4x, 8x) of A100 and L40S are also now available for custom models and training runs, not just deployments.
Check out the blog post for more details.
-
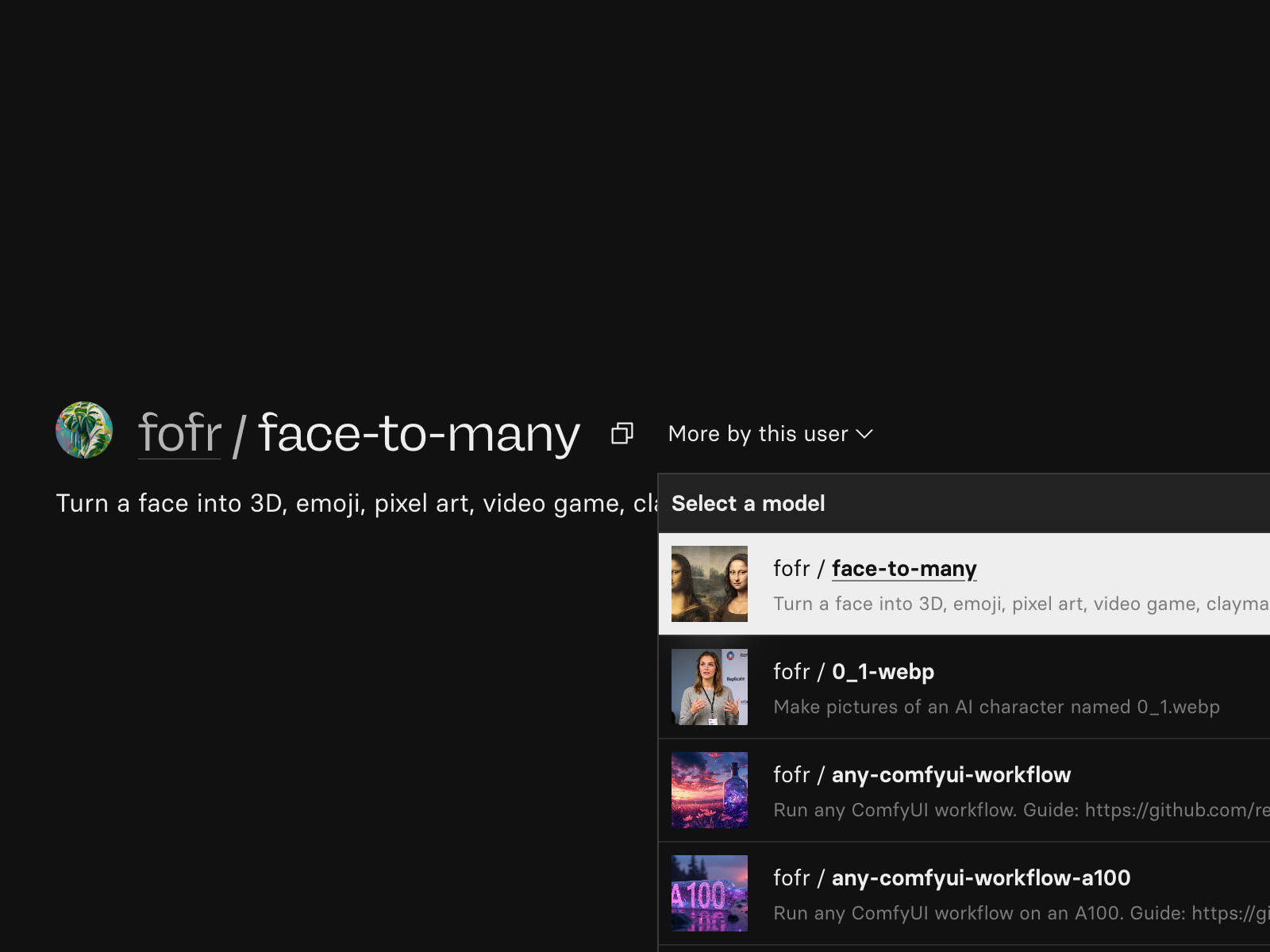
If you’re looking for other models by an author, you can use the “More by this user” button on their model page.
-
Platform
- Overhauled the pricing page
- Overhauled the explore navigation tab to make finding the playground easier
- Fixed an issue where the
importstatement in Node API code examples could show in the wrong place - Added support for more input types in the playground, including secrets and multi-file upload
- Fixed a bug when filtering predictions by deployments
- Fixed an issue that could potentially impact the use of keyboard shortcuts on form submissions
- Made quality of life improvements to speed up docs
Docs
- Added an LLM-friendly copy-and-paste, including links to use each doc in ChatGPT and Claude
-
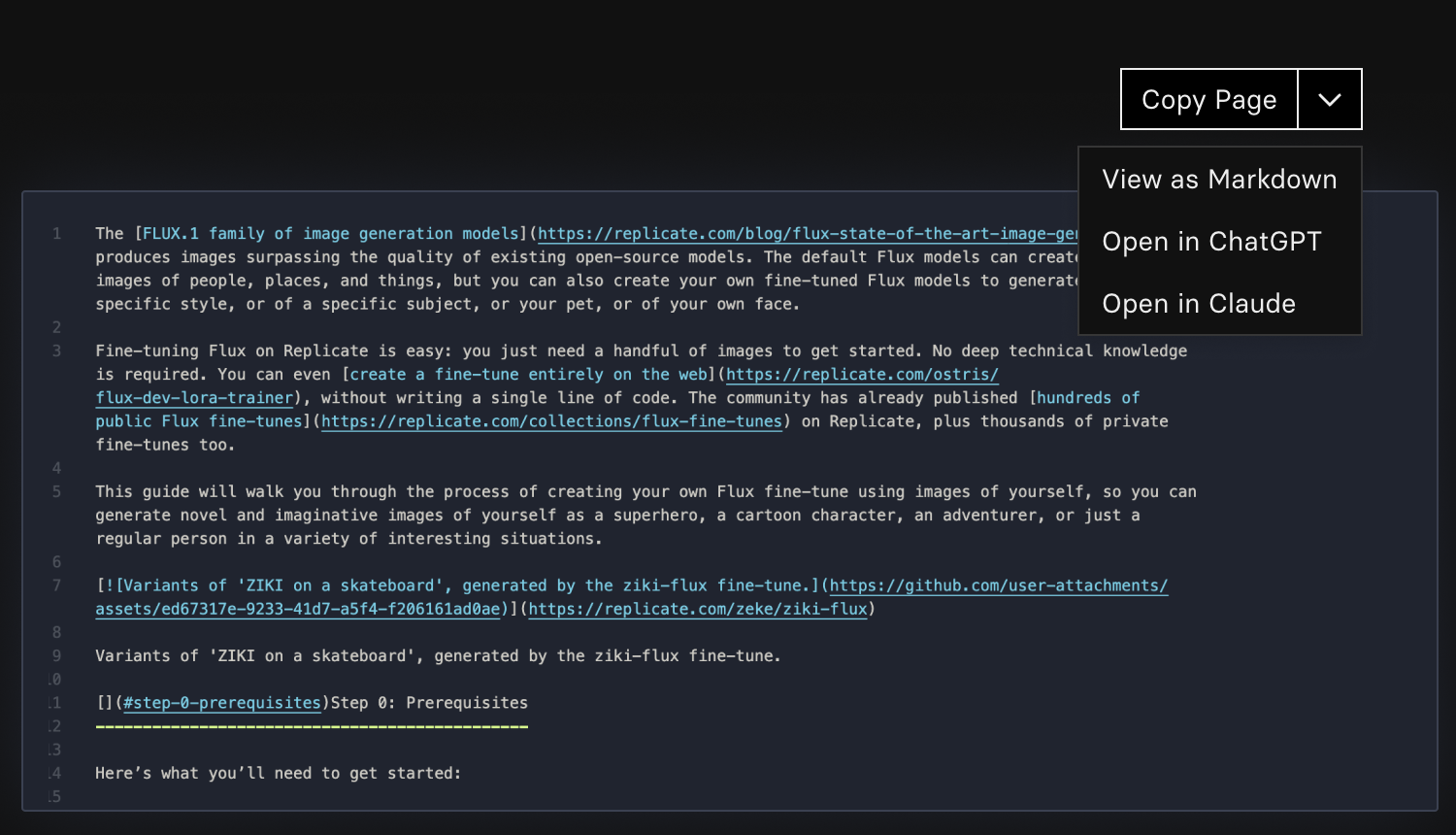
You can now copy-and-paste LLM-friendly code snippets from the docs, including links to use each doc in ChatGPT and Claude. This helps you use Replicate docs as a reference while working with LLMs.
-
Cog
- Added
cog predictsupport for inputs that are marked as optional - Improvements to performance and reliability through caching
Platform
- Rolled out the new navigation
- Fixed an issue that caused errors not to be clearly displayed when creating an organization
- Dramatically improved the performance of the Explore page
- Made it clearer that certain fine tune models shouldn’t be deployed on different hardware
- Fixed the vertical alignment of the predictions list on the deployment detail view
- Overhauled the support form
- Improved display of models without cover images
- Made careers page routing more consistent
- Fixed a case where that may have occasionally caused a redirect loop on the website
Docs
- Performance improvements
- Reduced initial download size when loading docs
Web
- Fixed OpenGraph preview images for shared predictions
- Added
-
API
- models.examples.list - List example predictions made using the model
- models.readme.get - Get the README content for a model
Cog
- Cog 0.14 is out! The main new feature in 0.14.0 is models that run predictions concurrently via async/await. At time of writing the latest version is now 0.14.3.
Platform
- Added directions for accessing docker images on private models
Playground
- Fixed an issue that sometimes caused the playground to reset to the default inputs between runs
- Fixed a bug when displaying multiple video inputs in the playground (beta)
Web
- Overhauled navigation to focus on specific tasks
- Improved feature flag implementation
- Updated the fallback cover image for models
- Fixed a bug that may have caused visual artifacts when using WebGL
- Fixed a bug with z-indexes between navigation and search
-
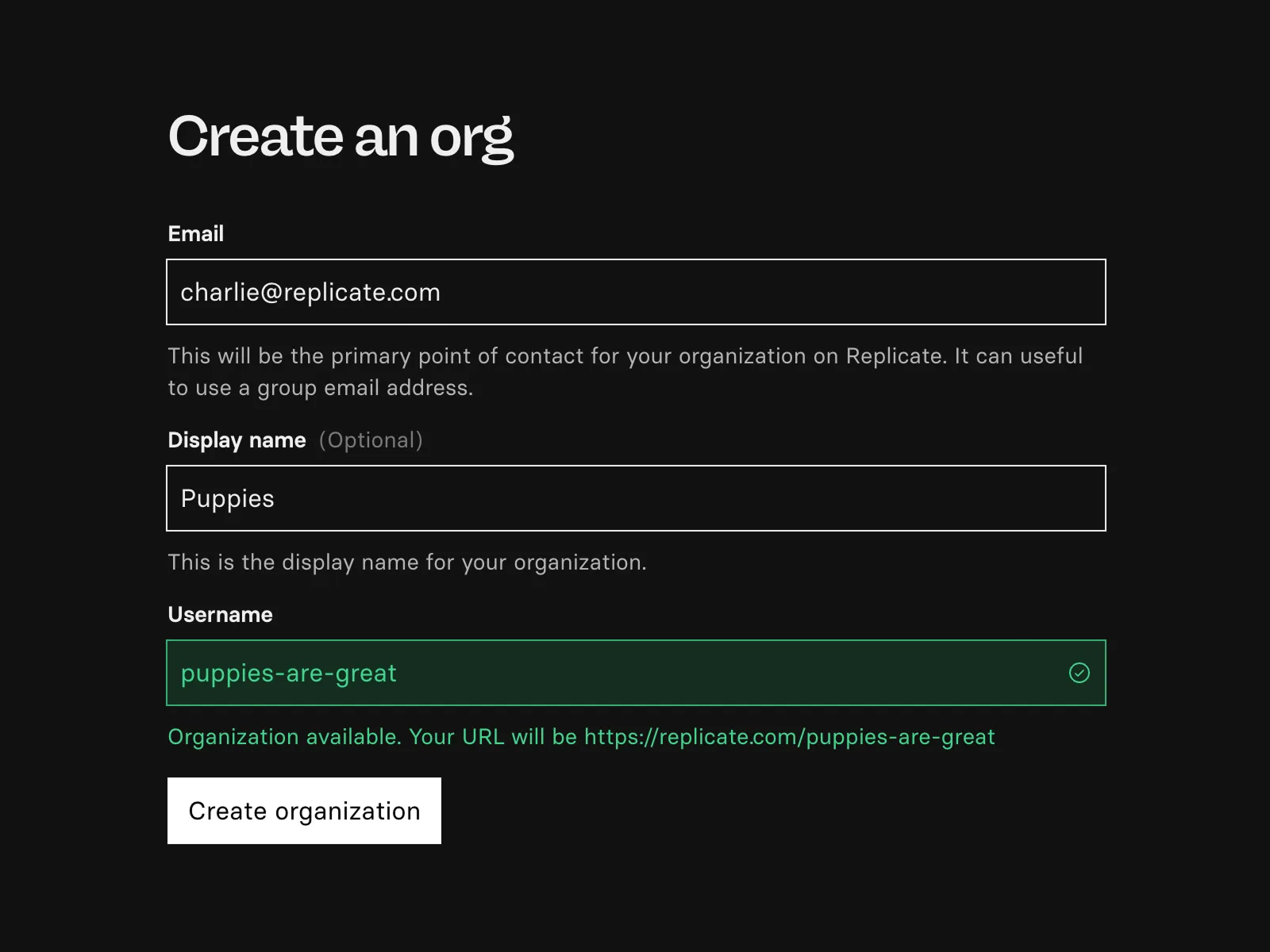
You can now create an organization on Replicate without needing a linked GitHub organization.
Organizations let you share access to models, API tokens, billing, dashboards, and more. When you run models as the organization, it gets billed to your shared credit card instead of your personal account. Learn more about organizations in the docs.
-
Web
- Improvements to the org creation experience
- Added better support for feature flags across the site
- Improved the error messages for failed trainings
- Fixed a bug with the sitemap for docs
- Added a visual to make it clearer when a prediction has multiple outputs
Playground
- Updated defaults to include new models
- Fixed an issue when using multiple video files as inputs for a prediction
Docs
-
Web
- Launched better predictions list filtering
- Launched the ability to create organizations without GitHub
- Fixed a layout bug on the deployment overview
- Tidied up the display of predictions on the deployment overview
- Tweaked the display of changelog items
- Fixed a bug when filtering dates in certain timezones and locales
- Fixed a bug that caused certain output file types to fail to load on the prediction web view
- Overhauled the account switcher to be more reliable
- Updated the account view to separate out account and organization management
- Overhauled the account update form view
Playground
- Added the state of a playground prediction to the grid view
-
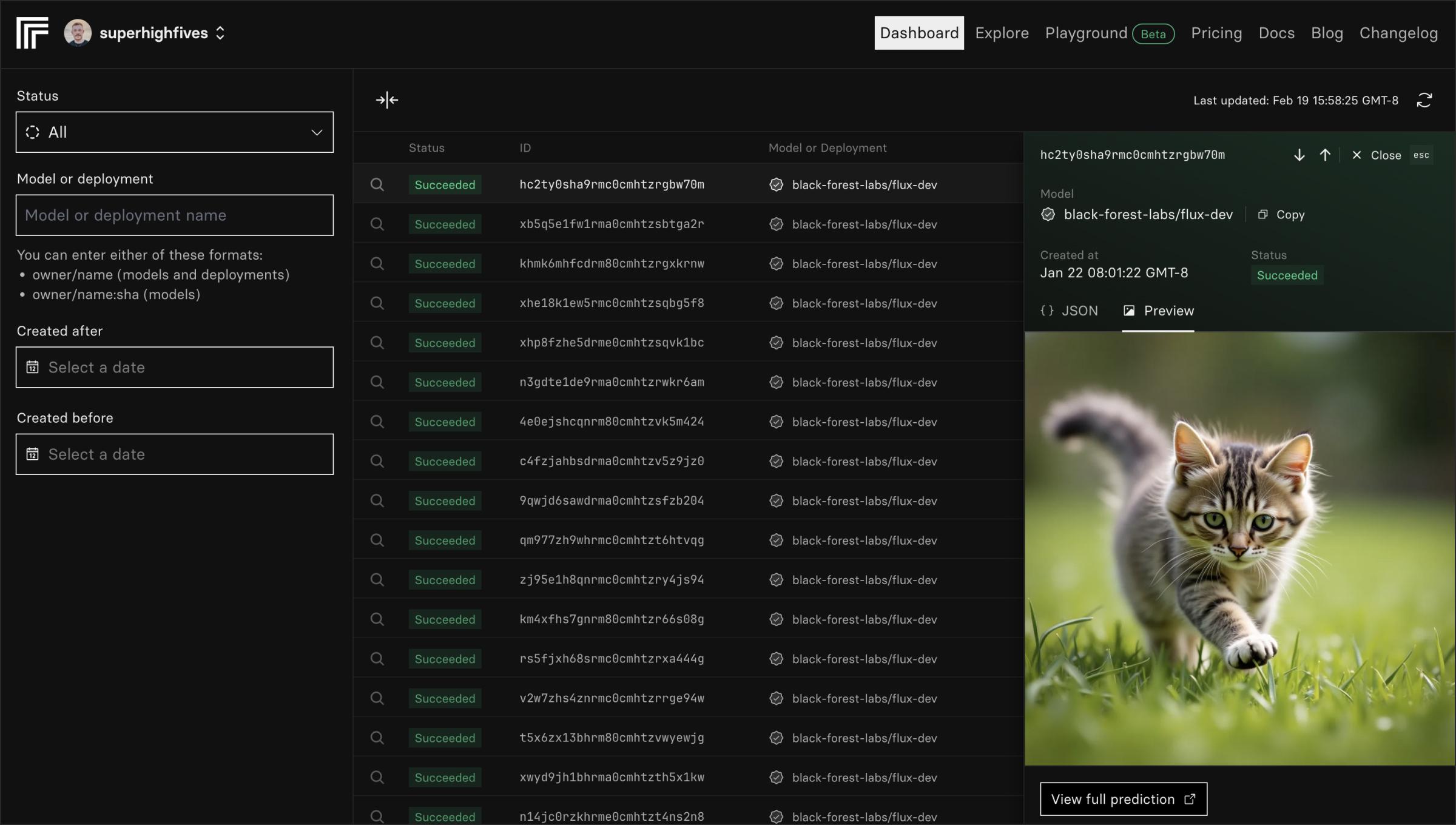
You can now filter the last 24 hours of predictions by model, deployment, version, and status. You can also quickly scan through all your predictions by date.
Take a look at replicate.com/predictions.
-
Web
- Added list of recent predictions to the deployments overview
- Fixed a bug when using the browser back button
- Fix for trigger word highlighting when using certain characters in the playground
- Minor updates to terms of service
- Created the official models collection
- Made the relationship between featured models and free usage clearer throughout the site
Playground
- Added the ability to restore model defaults
- Added a way to run multiple generations at once
- Updated the UI to make it clearer when you can select multiple items
- Fixed an error caused by losing connectivity while on the playground
- Fixed a bug that made numeric inputs unclearable
- Made the selected model persist on refresh
- Improved the date picker visibility in light mode
Docs
- Published a guide to building CI/CD pipelines for Cog models
- Released a video showing how to run Replicate models on Cloudflare Workers
- Updated the Getting started with Next.js guide and repo to use Flux Schnell
- Update API docs with examples for fetching model input and output schemas.
- Fixed a bug which could cause the sidebar to display on smaller breakpoints
API
- Added
created_beforeandcreated_afterfilters to the “list predictions” HTTP API
-
Web
- Launched official models
- Added latest predictions to the deployment detail page
- Fixed an issue with displaying certain pages on Replicate when logged out
- Updated the model detail API playground to make it possible to train with inputs that aren’t
.zip - Made it clearer when creating a deployment that flux fine-tunes shouldn’t be deployed
- Fixed a bug where numeric inputs could increment on scroll on the model detail API playground
- Fixed a bug that could cause inaccessible models to show up in collections
- Improved the experience of sharing predictions via web
- Improved clarity of autoscaling charts for deployments
- Made it easier to copy the model identifier (for official models) or the model identifier and
sha(for community models) - Updated chart for GPU metrics to make values easier to differentiate
Playground
- Added an icon to thumbnails to differentiate video content from other types
- Made it easier to see when errors occur and why
- Added the ability to remove multiple items from the grid on the playground
- Fixed a bug when selecting individual items that could cause all items to be deselected
- Added Vercel AI SDK snippets to playground
- Improved the loading and handling of large number of videos
Docs
- Updated deployment documentation
- Improved syntax highlighting across docs
-
Official models are always on and have predictable pricing. We maintain them in collaboration with the authors of the model to make sure they’re high quality.
A number of models have worked this way for a while, but we’re now giving it a name to make clear which ones work like this.
API
The way you call these models is a little different. If you’re using a client library, you don’t need to specify a version. For black-forest-labs/flux-1.1-pro in Node.js, for example:
const output = await replicate.run( "black-forest-labs/flux-1.1-pro", { prompt: "A t-rex on a skateboard looking cool" } );If you’re using the HTTP API, you use the
POST /models/<owner>/<name>/predictionsendpoint and you don’t need to specify a version. For example:curl https://api.replicate.com/v1/models/black-forest-labs/flux-1.1-pro/predictions \ --request POST \ --header "Authorization: Bearer $REPLICATE_API_TOKEN" \ --header "Content-Type: application/json" \ --header "Prefer: wait" \ --data @- <<'EOM' { "input": { "prompt": "A t-rex on a skateboard looking cool" } } EOMNothing has changed about how you run other models. The best way to find out how to run a model is the API documentation on a model.
Pricing
Instead of being charged by the amount of time a model runs, you’re charged by output. For example, black-forest-labs/flux-1.1-pro is charged for each image it generates, but for other models this might be things like the number of tokens or the length of a video.
You can find out about each model’s pricing on the pricing section of the model.
Models
Here are some of the models that are now official:
- black-forest-labs/flux-1.1-pro
- black-forest-labs/flux-dev
- black-forest-labs/flux-schnell
- deepseek-ai/deepseek-r1
- minimax/video-01
- meta/meta-llama-3-70b
- recraft-ai/recraft-v3
Take a look at the official models collection for the full list.
-
Web
- Relaunched the Replicate homepage
- Fixed a bug that caused the Replicate site to display a flash of no styles during deployments
- Improved the mobile navigation
- Fixed rounding in deployment GPU memory chart
- Migrated Remix to React Router 7
- Fixed a bug that shows run costs as
$null - Added video output previews to prediction table
- Fixed an issue where videos took over the screen for mobile devices
- Updated terms of service
- Made it easier to open support tickets when you’re an organization without an email address set
- Added a link to unpaid invoices in the dashboard to make it easier to pay them
- Updated training form to allow more file types than just
.zip
Playground
- Added video models to the playground by default
- Tweaked the UI elements on the playground to make interactivity clearer
- Added deep linking for models, allowing them to be automatically added to the playground
- Improved the visibility of impacted form fields when tweaking predictions on the playground
- Updated downloaded files to use standardized filenames and zip files
- Added keyboard shortcuts to prediction detail dialog to make it easier to flick through predictions
- Updated messaging to make it clearer that any model with URI output is supported
- Reordered models to show user-added ones first
Docs
- Added markdown routes to all docs
- Resolved an issue that made it difficult to navigate to site policy
- Added a clearer way to get to the next part of an article
-
Web
- Launched GPU usage monitoring for deployments
- Updated time display on the dashboard to be more granular
- Fixed an issue where audio files weren’t rendering correctly when provided as blobs
- Added dark mode support for additional media types
- Overhauled the model examples interface for model owners
- Added the ability to test different lighting styles on the 3D renderer, for models like firtoz/trellis
- Made it easier to view predictions by model version for model owners
- Fixed a bug when linking to billing from disabled deployments
- Dark mode fixes for table views
- Made it clearer when sharing a prediction from a private model that it will make the prediction public
- Better support loading deployment metric graphs with lots of data
- Added the ability to click from deployment prediction graph to the relevant predictions
- Fixed a bug that would cause the browser to record history push changes when toggling dark mode
Platform
- Added support for GPU usage monitoring for deployments
Playground
- Updated model list to be easier to browse for larger numbers of models
Docs
- Published a guide to dynamic image caching with Cloudflare
- Added a list of our subprocessors
-
We’ve stopped our experimental support for language model training.
You can still run all of the existing language models and fine-tuned models, but we no longer support training on those models to create derivative fine-tunes.
You can also still publish your own custom models using Cog.
Check out these docs for more information about building and publishing custom models:
We do still support fine-tuning image models. Check out these docs for more information:
-
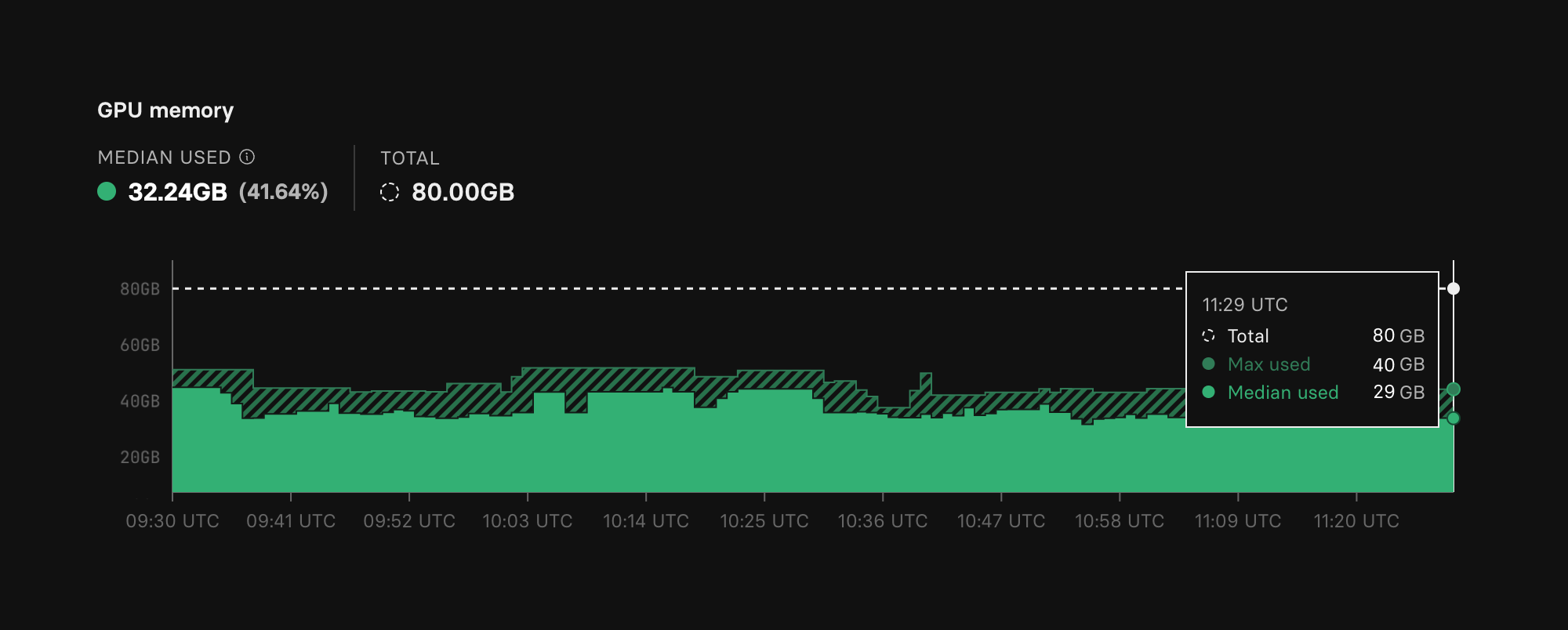
You can now monitor how much GPU memory your deployments are using. The visualization shows the total memory available to your deployment, and a median and max usage over the last 2 or 24 hours across all your instances.
Take a look at replicate.com/deployments.
-
Playground
- Fixed some significant rendering bugs in Safari, especially on the model picker and grid view
- Simplified the beta banner to be less obtrusive
Web
- You can now view errors in your prediction or other lists inline
- Fixed a bug that caused the browser navigation API to add multiple instances of each page
- Collections contain featured models, hand picked by our team
- The text-to-video collection now includes six of the top models from the Artificial Analysis leaderboard.
- WebGL errors are better handled on the site, like when you see the Replicate goo
- You can now deep link to default models on the playground (beta)
- Fixed a bug when highlighting the
trigger_wordon Flux fine-tunes - Increased the number of featured models visible on the explore page
- Improved sharing of collections and blog posts on social media
- Improved the availability of the account switcher across Replicate
- Added the status badge more consistently across Replicate
- Fixed an issue with the blog RSS feed that caused images to not be displayed
- Made it clearer that customers only pay for run time on private trained models
- Updated model detail page to more accurately reflect the hardware being used when created through training
Docs
- The text-to-video collection includes six of the top models from the Artificial Analysis leaderboard.
-
Playground
- Added FLUX1.1 [pro] ultra to default models, along with a number of new models
- Improved image loading on playground
- Optimizations when rendering many images, especially with larger images files (like with black-forest-labs/flux-1.1-pro-ultra)
- Better handling of enums of numbers in the playground
- Fixed a bug that cropped images in the grid
- Fixed a bug where an image may have been prematurely flagged as downloadable
- Added the ability to invert masks after inpainting, undo strokes, and to use the mouse wheel to alter brush resizing
Web
- Improved signposting when you first sign up and land on the dashboard
- Moved thumbnail images to the right in the prediction list to make browsing easier
- Improved navigation rendering across Replicate
- Added the ability to show preview pricing for hardware on pricing
- Improved the onboarding flow to make the steps clearer
- Improved invoice JSON download visibility
- Improved discoverability of the new playground from model detail pages
- Updated terms and privacy pages
Platform
- Added support for per-video pricing
- Added support for L40S GPUs
Docs
- Published a new doc about OpenAPI schemas for the HTTP API and all models.
-
Runtime
- Rollback of data URLs in the new sync API.
Playground
- Added file picker to playground to simplify file uploading
- Added Stable Diffusion 3.5L to the default models
- Added Recraft V3 to the default models
- Made keyboard shortcuts clearer between different operating systems
- Added download link to the grid in the playground
- Fixed an issue where predictions were incorrectly being flagged as ephemeral
- Added model card to the playground, to give more context on models
Web
- Made keyboard shortcuts clearer between different operating systems
- Improved the rendering and support of legacy blog posts
- Updated API examples to better represent different return types
- Made switching between themes easier across the site
- Made the placement of “add to example” buttons for model owners on predictions clearer
- Ongoing improvements to dark mode across web
- Updated sitemaps for web
- Resolved an issue where certain pages would redirect to add a trailing slash to the URL
Docs
- Added HTTP API docs for new synchronous predictions.
- Updated sitemaps for docs
-
Replicate will stop supporting models built with Python 3.7 at 12:00 PM UTC (Coordinated Universal Time) on Friday, November 15th.
Python 3.7 was declared end-of-life in late June 2023. Since then, we’ve continued running models built with it to give model maintainers time to migrate to newer Python versions.
Although we would like to continue running these models indefinitely, we must prioritize the security needs of our customers. After Python 3.7 support ends, requests to affected models will fail with a 400-level error with an explanation.
Please update your models to a newer Python version before this date to avoid any interruptions, and let us know if you have questions or need help updating your models.
-
Runtime
- Dropped support for running Python 3.6 and 3.7 models
- Dropped support for pushing Python 3.8 models, but existing ones will still run
- Added support for Pydantic 2
Playground
- Added inline inpainting to the playground
- Added video to the playground
- Added more granular grid sizes to the playground
- Fixed a bug that caused double submissions on the playground form
- Added better handling for unsupported outputs on the playground
- Improved focus states in the grid and list view for the playground
- Added the ability to delete items from the playground grid
- Made keyboard shortcuts more visible for the playground
- Improved scrolling performance for playground
Web
- Relaunched the about page, including job roles and applications
- Better handle longer queue lengths for deployment metrics
- Fixed a display bug with pricing on models for signed out users
- Fixed some z-index weirdness for signed out users
- Improved copy / saving of streamed images on web
- Fixed bugs in per-model API endpoint documentation
- Handled models without a cover image better, especially on social media
- Reduced inconsistencies for input schema tables between model versions and the model API tab
- Improved display of plural units in the model pricing table
- Added sorting by name and cost to invoices, and the ability to download invoices as JSON
- Improved handling of multi file strings on the model page
- Fixed bug on the model detail page when pasting JSON
- Handled an edge case where the state of a model didn’t match visually
- Fixed a few cases where the colors were wrong in dark mode
Docs
- Moved guides into docs
- Updated selection color on our docs to improve accessibility
- Improved readability for monospaced fonts on docs
- Handled image caching for docs better
-
Finally. You can switch it in the footer.
-
Playground is a way to quickly try out and compare the output of models on Replicate.
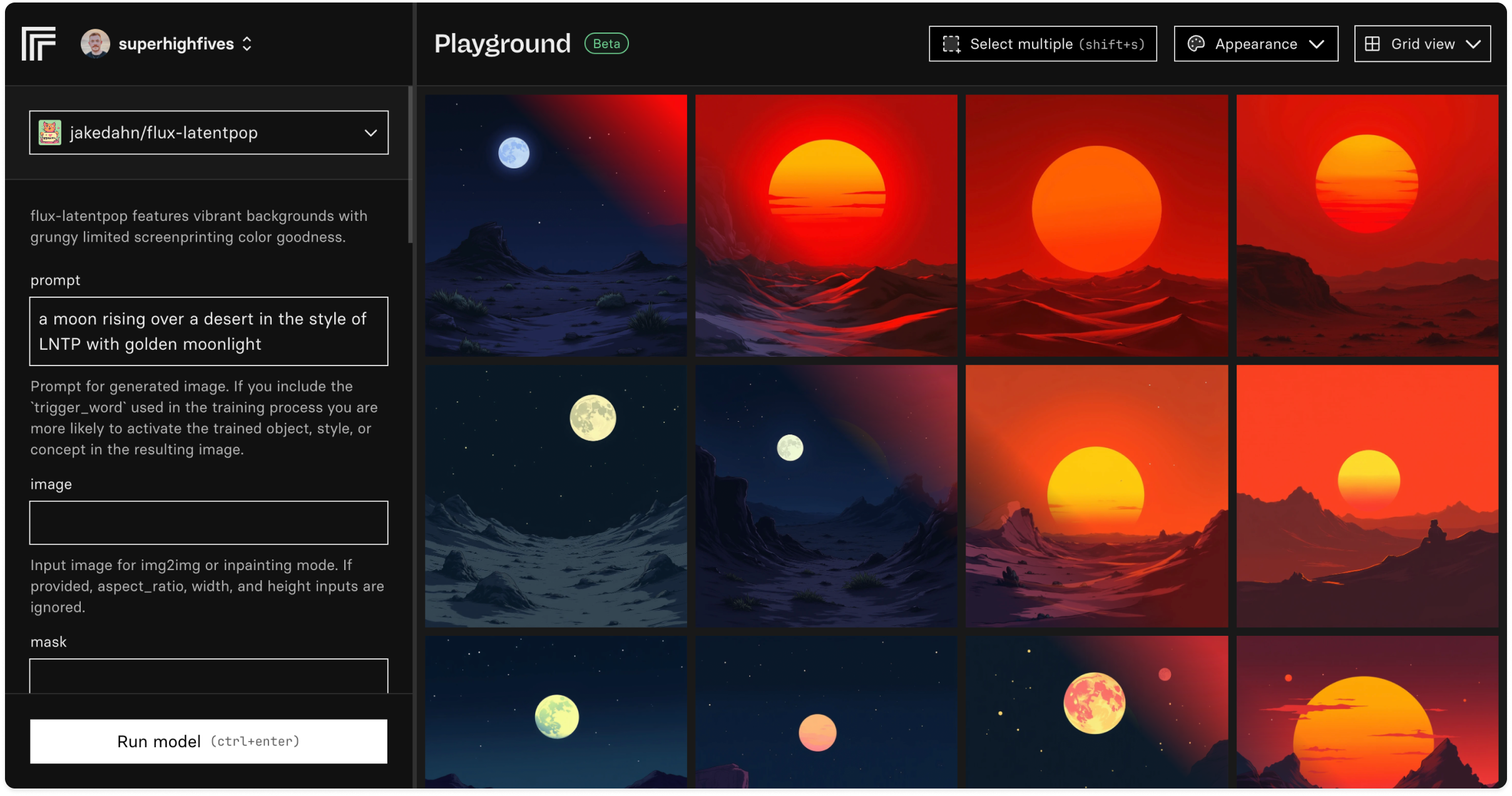
You can:
- Create grids of images and compare them
- Grab the code to generate the images with Replicate
- Test different models, prompts, and settings, side-by-side
- Keep a scrapbook and export images in bulk
Playground is currently in beta, and works with any FLUX and related fine-tunes. Try it out at replicate.com/playground.
We’d love to hear what you think. Send your feedback to playground@replicate.com.
-
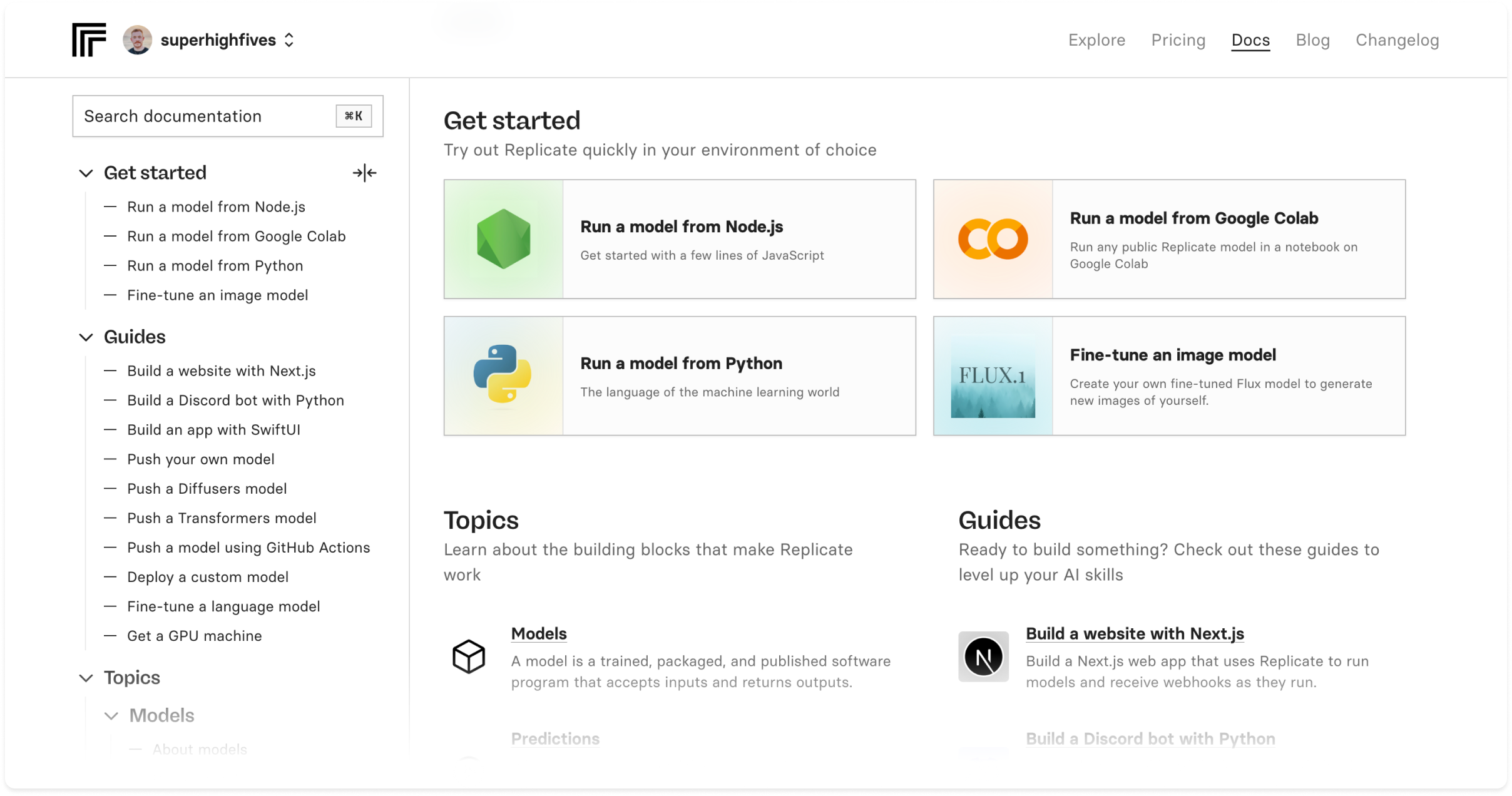
Documentation now has a cleaner design, better navigation, and lots of new content to help you build with Replicate.
It’s organized into four sections:
- Getting started: tutorials to help you get up and running quickly
- Guides: step-by-step instructions and deeper dives into specific topics
- Topics: detailed explanations of how Replicate works
- Reference: complete documentation for Replicate’s client libraries and API
We’ve added dozens of new code samples, detailed guides for common use cases, and an expanded API reference.
Take a look at replicate.com/docs.
-
Our client libraries and API are now much faster at running models, particularly if a file is being returned.
The API now returns the response immediately. Before, you would have to poll to get the result.
If you’re using the Node.js or Python client libraries, you don’t have to worry about this. Upgrade to the latest version and it gets faster. Also, instead of returning HTTP URLs, they now return file objects, which helps you write them to storage or pass to HTTP responses.
Node.js
Install the beta version of the client library:
npm install replicate@latestThen run the model:
import Replicate from "replicate"; import fs from "node:fs"; const replicate = new Replicate(); const [output] = await replicate.run("black-forest-labs/flux-schnell", { input: { prompt: "astronaut riding a rocket like a horse" }}); // It now returns a file object fs.writeFileSync("my-image.webp", output); // Or, you can still get an HTTP URL console.log(output.url())Python
Update the client library:
pip install --upgrade replicateThen run the model:
[output] = replicate.run( "black-forest-labs/flux-schnell", input={"prompt": "astronaut riding a rocket like a horse"} ); with open('output.webp', 'wb') as file: file.write(output.read()) print(output.url)The client libraries returning file objects is a breaking change so be careful when you upgrade your apps.
HTTP API
If you’re using the HTTP API for models or deployments, you can now pass the header
Prefer: wait, which will keep the connection open until the prediction has finished:curl -X POST <https://api.replicate.com/v1/models/black-forest-labs/flux-schnell/predictions> \\ -H "Authorization: Bearer $REPLICATE_API_TOKEN" \\ -H "Prefer: wait=10" \\ -d '{"input": {"prompt": "a cat riding a narwhal with rainbows"}}'Output:
{ "id": "dapztkbwgxrg20cfgsmrz2gm38", "status": "processing", "output": ["https://..."], }By default it will wait 60 seconds before returning the in-progress prediction. You can adjust that by passing a time, like
Prefer: wait=10to wait 10 seconds.Take a look at the docs on creating a prediction for more details.
-
Predictions or trainings that log particularly large volumes of information may now have their logs truncated. This helps us manage load on our platform and is a restriction we may lift in future.
For now, you’ll always get the first few lines of your logs — which might contain important information about inputs, seed values, etc. — and the most recent logs.
-
To improve API performance and speed up database queries, we are cleaning out old predictions.
From now on, you’ll only be able to share predictions made in the web playground for up to 60 days after they’re created.
If you’ve already shared a prediction, don’t worry - it will still be accessible to others even after 60 days.
-
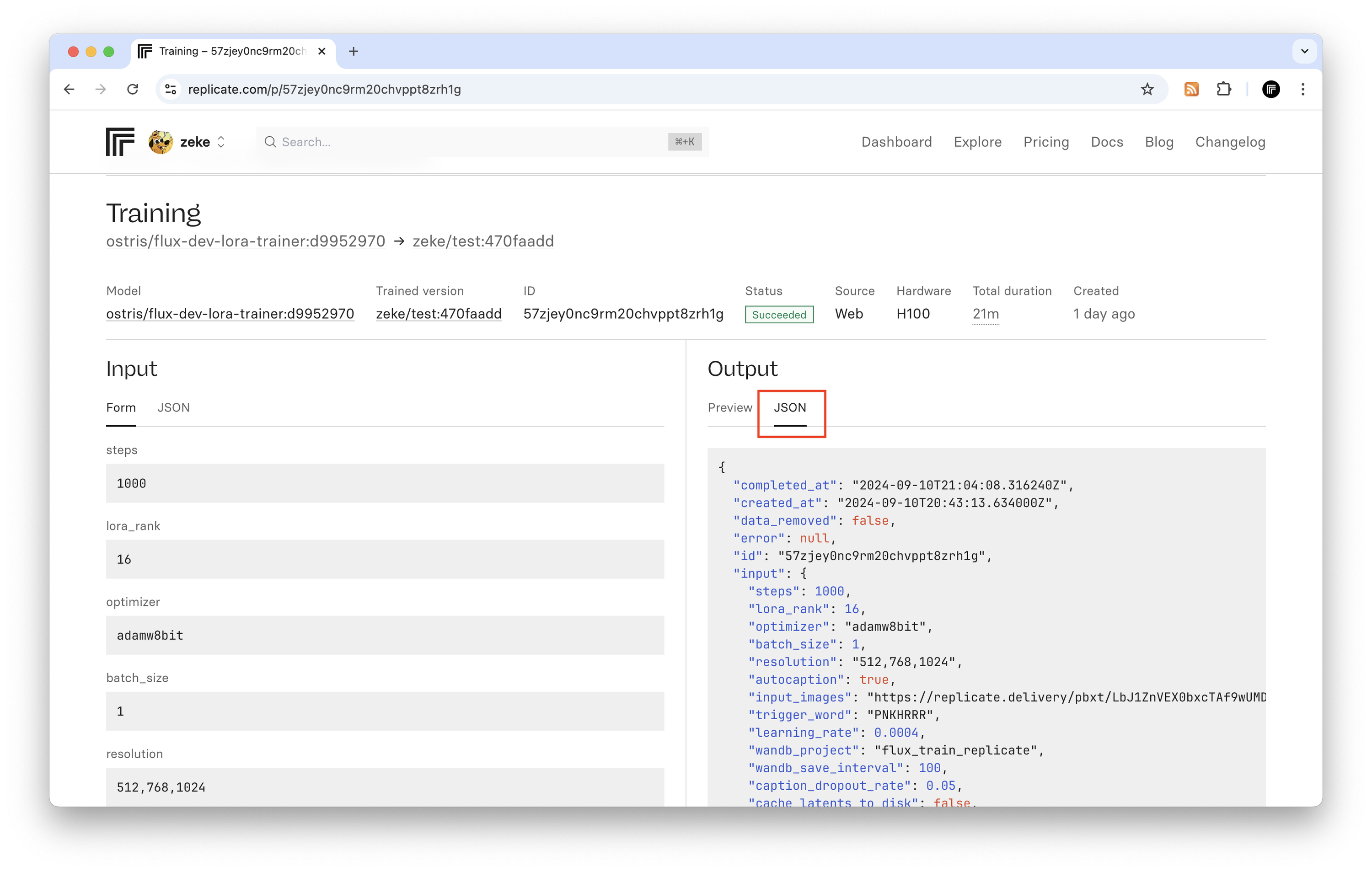
The training detail page on the website now has a JSON tab, so you can see all the metadata and outputs from your trainings, including the URL of your generated weights file.
To view all your trainings, go to replicate.com/trainings
-
Replicate’s API now has an endpoint for searching public models.
To use it, make a QUERY HTTP request using your search query as the plaintext body of the request:
curl -s -X QUERY \ -H "Authorization: Bearer $REPLICATE_API_TOKEN" \ -H "Content-Type: text/plain" \ -d "face" \ https://api.replicate.com/v1/modelsThe response will be a paginated JSON object containing an array of model objects:
{ "next": null, "previous": null, "results": [ { "url": "https://replicate.com/acme/hello-world", "owner": "acme", "name": "hello-world", "description": "A tiny model that says hello", "visibility": "public", "github_url": "https://github.com/replicate/cog-examples", "paper_url": null, "license_url": null, "run_count": 5681081, "cover_image_url": "...", "default_example": {...}, "latest_version": {...} } ] }For more details, check out the HTTP API reference docs.
You can also the download metadata for all public models on Replicate using the list public models API if you need more fine-grained control or want to build your own implementation of model search.
-
We’ve made streaming a tiny bit easier and simplified our API.
When we first launched streaming for language models you had to pass
"stream": truewith your request to enable it. Adoption of streaming has been great, with about one third of requests to compatible models requesting a stream, and our streaming infrastructure is more robust now than it was when we first launched it. This means we’re now in the position to just stream everything by default if the model supports it.So you no longer need to pass
"stream": truewith your prediction request to get back a stream URL – if the model supports streaming, you’ll always get one back.We’ve deprecated the field, but it’s still valid to pass it. If you do continue to pass
"stream": truethen if the model supports streaming it has no effect. And if the model doesn’t support streaming we’ll keep the current behaviour of responding with a 422. -
We’ve added a way to securely pass sensitive values to models.
In Cog v0.9.7 and later, you can annotate an input with the
Secrettype to signify that an input holds sensitive information, like a password or API token.from cog import BasePredictor, Secret class Predictor(BasePredictor): def predict(self, api_token: Secret) -> None: # Prints '**********' print(api_token) # Use get_secret_value method to see the secret's content. print(api_token.get_secret_value())Replicate treats secret inputs differently throughout its system. When you create a prediction on Replicate, any value passed to a
Secretinput is redacted after being sent to the model.Before

After
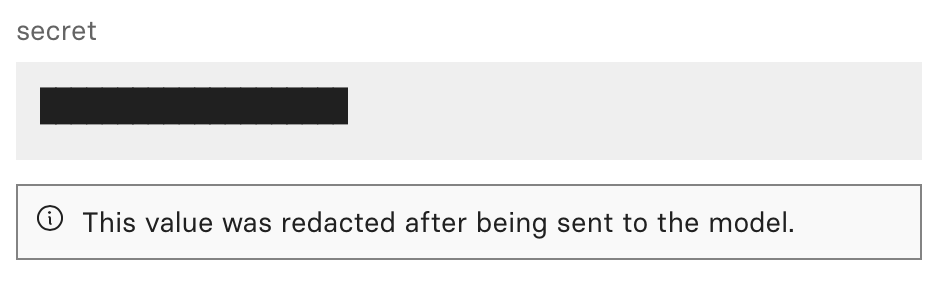
Caution: Passing secret values to untrusted models can result in unintended disclosure, exfiltration, or misuse of sensitive data.
-
You can now disable API tokens from the web. This is useful if you accidentally leaked your token and want to prevent unauthorized use of the token.
To view and manage your tokens, go to replicate.com/account/api-tokens.

-
We now publish RSS and Atom feeds for our blog, changelog, and platform status site. You can subscribe to these feeds to get updates about new product features, as well as platform incidents
- https://replicatestatus.com/feed
- https://replicate.com/changelog/rss
- https://replicate.com/changelog/atom
- https://replicate.com/blog/rss
- https://replicate.com/blog/atom
If you’re using Slack, you can use Slack’s RSS app to subscribe to these feeds and get notifications right in your team’s Slack workspace.
-
You can now delete models, versions, and deployments using the web or the HTTP API.
Deleting models
You can delete a model directly from the web on the model settings page. You can also delete a model programmatically using the
models.deleteHTTP API.There are some restrictions on which models you can delete:
- You can only delete models you own.
- You can only delete private models.
- You can only delete models that have no versions associated with them. You’ll need to delete any versions first before deleting the model.
Deleting model versions
You can delete a model version directly from the web using the nav in the header of the model versions page. You can also delete a model version programmatically using the
versions.deleteHTTP API.The following restrictions apply to deleting versions:
- You can only delete versions from models you own.
- You can only delete versions from private models.
- You cannot delete a version if someone other than you has run predictions with it.
- You cannot delete a version if it is being used as the base model for a fine tune/training.
- You cannot delete a version if it has an associated deployment.
- You cannot delete a version if another model version is overridden to use it.
Deleting deployments
You can delete a deployment directly from the web on the deployment settings page. You can also delete a deployment programmatically using the
deployments.deleteHTTP API.The following restriction applies to deleting deployments:
- You can only delete deployments that have been offline and unused for at least 15 minutes.
-
A webhook is an HTTP POST from an unknown source. Attackers can impersonate services by sending a fake webhook to an endpoint. Replicate protects you from this attack by signing every webhook and its metadata with a unique key for each user or organization. You can use this signature to verify that incoming webhooks are coming from Replicate before you process them.
Today we improved our documentation and client library support for webhooks, so you can securely verify webhooks in your existing application without having to write your own validation logic:
-
The Replicate website has a search bar at the top of every screen that lets you fuzzy search for models, collections, and pages.
We’ve now added deployments to the search results, so you can quickly jump right to one of your deployments with fewer clicks.
Press
cmd-k(orctrl-kon Windows) to open the search and search for your deployment by name:
-
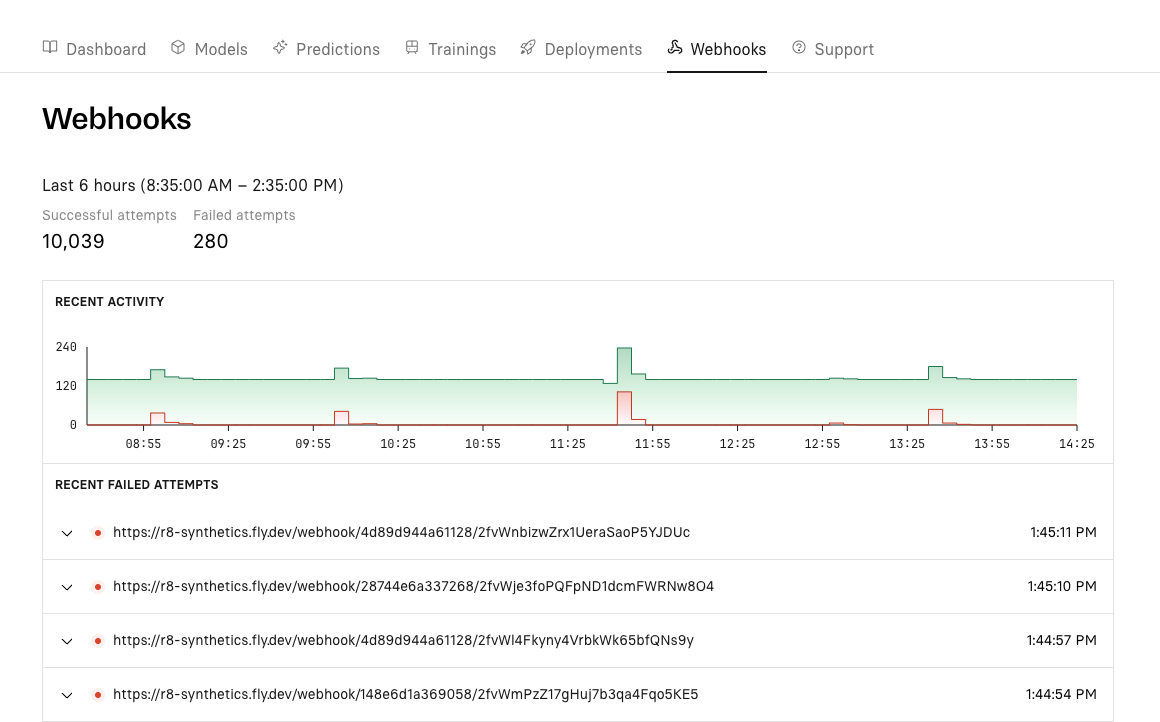
We’ve added two new UI features to make your experience with webhooks better on Replicate.
On the prediction detail screen, if your prediction was made with webhooks, you’ll see an indicator that opens a sliding panel with the details and status of those webhooks.
There’s also a new “Webhooks” tab on the Dashboard where you’ll find a chart detailing 6 hours of recent webhook activity, as well as any failures that have occurred in that time period.
-
If you typo a field in the JSON request body when creating a prediction with the API, we will now tell you about it rather than silently accepting it.
Here’s an example showing the response you’ll get if you misspell
inputasinptu:$ curl -s -X POST \ -H "Authorization: Bearer $REPLICATE_API_TOKEN" \ -H 'Content-Type: application/json' \ -d '{ "version": "5c7d5dc6dd8bf75c1acaa8565735e7986bc5b66206b55cca93cb72c9bf15ccaa", "inptu": {"text": "Alice"} }' \ https://api.replicate.com/v1/predictions | jq .invalid_fields[ { "type": "required", "field": "", "description": "input is required" }, { "type": "additional_property_not_allowed", "field": "", "description": "Additional property inptu is not allowed" } ]Note that this validation only applies to top-level properties in the payload like
input,version,stream,webhook,webhook_events_filter, etc. -
Until recently, models running on T4 GPUs would get 4 CPUs, 8 GB of RAM and 16 GB of GPU RAM. We got feedback from model authors that this caused issues with loading more than 8GB of weights into the GPU - it’s possible, but it requires writing more intricate code to stream weights from disk to GPU RAM without loading the whole weights into main RAM at once.
Starting today, T4 models can now use up to 16 GB of RAM. This should make it easier to make use of all of the GPU RAM on T4 GPUs. There is no pricing change for this upgrade.
You can see the resources available for each hardware type on our pricing page.
-
When working with secrets like API tokens, you should always store them in your app configuration (like environment variables) rather than directly in your codebase. Keeping sensitive information separate from your source code prevents accidental exposure.
This is a common and well-known security practice, but sometimes you slip up and accidentally include a secret in your codebase. That’s where GitHub security scanning comes in.
We’ve partnered with GitHub and are now members of their Secret scanning partner program, helping to keep your account safe. Whenever GitHub finds a Replicate API token in a public repository, they notify us so we can take proper steps to protect your account from unwanted use.
-
When using an HTTP API, a Bearer token is like a password that you specify in the
Authorizationheader of your HTTP requests to access protected resources.We’ve updated our API to support a standard
Bearerauthorization scheme rather than a custom/non-standard Token scheme. We’ve also updated our API docs and OpenAPI specification to use the new format:curl -H "Authorization: Bearer r8_...." https://api.replicate.com/v1/models/replicate/hello-worldThe old
Authorization: Token r8...format is still supported, so your existing API integrations will continue to work without any code changes. -
Deployments give you more control over how your models run. You can scale them up and down based on demand, customize their hardware, and monitor performance and predictions without editing your code.
Managing deployments was previously only possible on the web, but you can now also create, read, and update deployments using Replicate’s HTTP API.
Here’s an example API request that updates the number of min and max instances for an existing deployment:
curl -s \ -X PATCH \ -H "Authorization: Token $REPLICATE_API_TOKEN" \ -H "Content-Type: application/json" \ -d '{"min_instances": 3, "max_instances": 10}' \ https://api.replicate.com/v1/deployments/acme/my-app-image-generatorCheck out the API docs for deployments:
If you’re new to deployments, check out the getting started guide.
-
Models like adirik/imagedream that output GLB files now have a web-based viewer, so you can explore the 3D output right in your browser.
The GLB format encapsulates textures, models, and animations into a single file which can be shared and used across platforms and devices. This makes it useful in web development, augmented reality projects, and game development.
If you’re working with AI models that produce PLY outputs, you can use a model like camenduru/lgm-ply-to-glb to convert PLY files to GLB.
There’s also a collection of models for making 3D stuff.
-
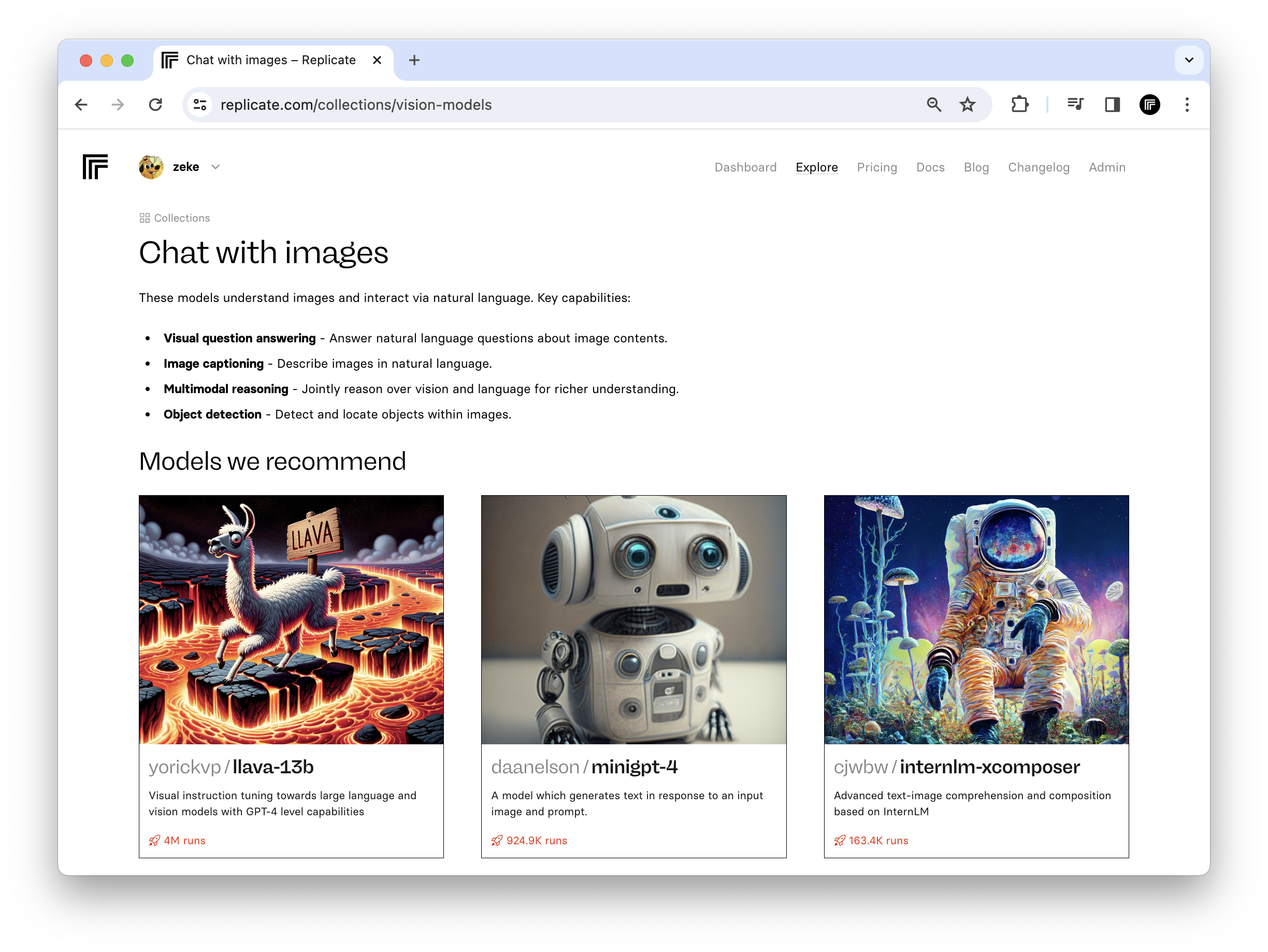
We’ve updated our curated model collections to be more oriented around tasks like upscaling images, generating embeddings, or getting structured data from language models. This should make it easier to find the right models for the problems you’re trying to solve.
Each collection now also includes a more detailed summary of the kinds of tasks you can perform with models in that collection. For example, vision models can be used for all sorts of tasks like captioning images, answering questions about images, or detecting objects:
-
Webhooks provide real-time updates about your predictions. You can specify an endpoint when you create a prediction, and Replicate will send HTTP POST requests to that URL when the prediction is created, updated, and finished.
Starting today, we now sign every webhook and its metadata with a unique key for each user or organization. This allows you to confirm the authenticity of incoming webhooks and protect against unauthorized access and replay attacks.
Learn how to verify incoming webhooks on our webhooks guide
-
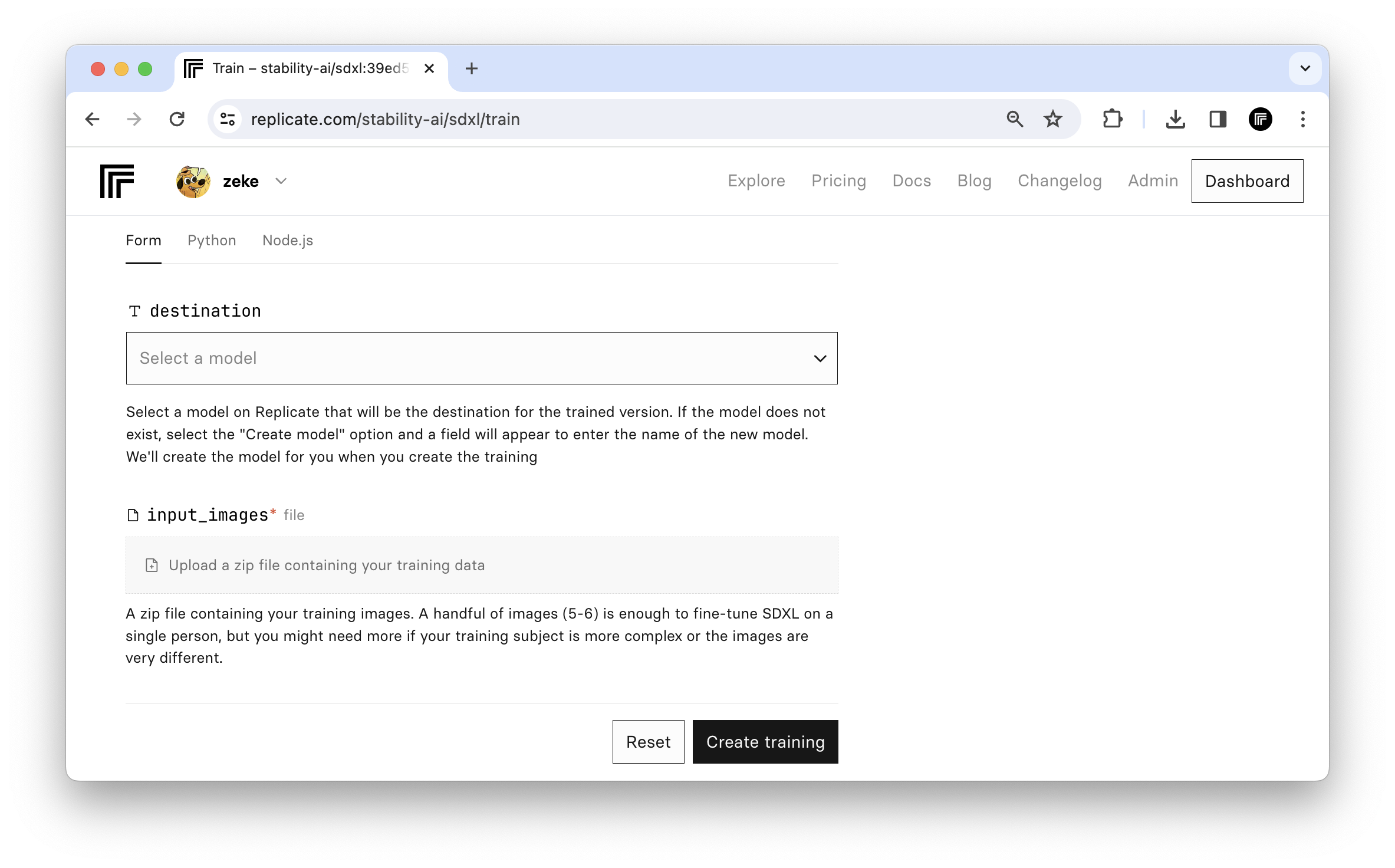
In August 2023, we added an API for fine-tuning SDXL, Stability AI’s most powerful open-source image generation model. We made it possible to create your own custom models with a handful of training images and a few lines of code, then generate new images in your own style. In the last few months, people have created lots of interesting SDXL fine-tunes.
You can now create SDXL fine-tunes from the web. Choose a name for your model, drag and drop a zip file of images, and kick off the training process, without writing any code.
To get started, visit replicate.com/stability-ai/sdxl/train
-
We’ve added a new slider component that makes it easier to compare image inputs to outputs. Drag the slider to the left and right to compare the “before and after” images.
This feature works for all models that take an input image and produce an output image, like image restoration models and upscalers.

-
Every prediction on the web now includes code snippets for Node.js, Python, and other languages. This lets you tinker with a model on the web, then grab some useable code and run with it.
To view these code snippets, click the language tabs under the Input heading on any model or prediction page:
Clicking one of these language tabs changes the page URL, which means you can also deep link to language-specific snippets for any model:
Here’s a five-minute video showing off how to use this new feature to run a model in the browser, then grab the code to run the model in your own project using Replicate’s API:
-
Replicate’s API now has an endpoint for creating models.
You can use it to automate the creation of models, including fine-tunes of SDXL and Llama 2.
cURL usage
Here’s an example that uses cURL to create a model with a given owner, name, visibility, and hardware:
curl -s -X POST -H "Authorization: Token $REPLICATE_API_TOKEN" \ -d '{"owner": "my-username", "name": "my-new-model", "visibility": "public", "hardware": "gpu-a40-large"}' \ https://api.replicate.com/v1/modelsThe response is a JSON object of the created model:
{ "url": "https://replicate.com/my-username/my-new-model", "owner": "my-username", "name": "my-new-model", "description": null, "visibility": "public", "github_url": null, "paper_url": null, "license_url": null, "run_count": 0, "cover_image_url": null, "default_example": null, "latest_version": null }To see all the hardware available for your model to run, consult our endpoint for listing hardware.
curl -s -H "Authorization: Token $REPLICATE_API_TOKEN" \ https://api.replicate.com/v1/hardware[ { "name": "CPU", "sku": "cpu" }, { "name": "Nvidia T4 GPU", "sku": "gpu-t4" }, { "name": "Nvidia A40 GPU", "sku": "gpu-a40-small" }, { "name": "Nvidia A40 (Large) GPU", "sku": "gpu-a40-large" } ]To compare the price and specifications of these hardware types, check out the pricing page.
JavaScript usage
We’ve added this new operation to the Replicate JavaScript client:
npm install replicate@latestThen:
import Replicate from "replicate"; const replicate = new Replicate(); // create a new model const model = await replicate.models.create( "my-username", "my-new-model", { visibility: "public", hardware: "gpu-a40-large" } ); console.log(model)Python usage
We’ve added this new operation to the Replicate Python client:
pip install --upgrade replicateThen:
import replicate model = replicate.models.create( owner="my-username", name="my-new-model", visibility="public", hardware="gpu-a40-large", ) print(model)Elixir usage
We’ve added this new operation to the Replicate Elixir client:
mix deps.update replicateThen:
iex> {:ok, model} = Replicate.Models.create( owner: "your-username", name: "my-model", visibility: "public", hardware: "gpu-a40-large" )API docs
Check out the HTTP API reference for more detailed documentation about this new endpoint.
-
When you kick off a training process to fine-tune your own model, there’s a page you can visit to view the status of the training, as well as the inputs and outputs. We’ve made some recent improvements to those pages:
- The header now shows the base model and destination model you used when fine-tuning.
- Metadata about the training job is now diplayed above the inputs and outputs to make it easier to see the important details without having to scroll down the page.
- We’ve added code snippets you can copy and paste to run your new fine-tuned model.
-
You can now view prediction parameters as JSON from the prediction detail page.
This improves the workflow for experimenting in the web interface and then transitioning to making predictions from the API, using code.
-
Replicate’s API now has an endpoint for listing public models.
You can use it to discover newly published models, and to build your own tools for exploring Replicate’s ecosystem of thousands of open-source models.
cURL usage
Here’s an example that uses cURL and jq to fetch the URLs of the 25 most recently updated public models:
curl -s -H "Authorization: Token $REPLICATE_API_TOKEN" \ https://api.replicate.com/v1/models | jq ".results[].url"The response is a paginated JSON array of model objects:
{ "next": null, "previous": null, "results": [ { "url": "https://replicate.com/replicate/hello-world", "owner": "replicate", "name": "hello-world", "description": "A tiny model that says hello", "visibility": "public", "github_url": "https://github.com/replicate/cog-examples", "paper_url": null, "license_url": null, "run_count": 5681081, "cover_image_url": "...", "default_example": {...}, "latest_version": {...} } ] }JavaScript usage
We’ve added this new operation to the Replicate JavaScript client:
npm install replicate@latestThen:
import Replicate from "replicate"; const replicate = new Replicate(); // get recently published models const latestModels = await replicate.models.list(); console.log(latestModels) // paginate and get all models const allModels = [] for await (const batch of replicate.paginate(replicate.models.list)) { allModels.push(...batch); } console.log(allModels)Python usage
We’ve added this new operation to the Replicate Python client:
pip install --upgrade replicateThen:
import replicate models = replicate.models.list() print(models)Making your own models discoverable
If you’re deploying your own public models to Replicate and want others to be able to discover them, make sure they meet the following criteria:
- The model is public.
- The model has at least one published version.
- The model has at least one example prediction. To add an example, create a prediction using the web interface then click the “Add to examples” button below the prediction output.
-
You can now create a deployment to get more control over how your models run. Deployments allow you to run a model with a private, fixed API endpoint. You can configure the version of the model, the hardware it runs on, and how it scales.
Using deployments, you can:
- Roll out new versions of your model without having to edit your code.
- Keep instances always on to avoid cold boots.
- Customize what hardware your models run on.
- Monitor whether instances are booting up, running, or processing predictions.
- View predictions that are flowing through your models.
Deployments work with both public models and your own private models.
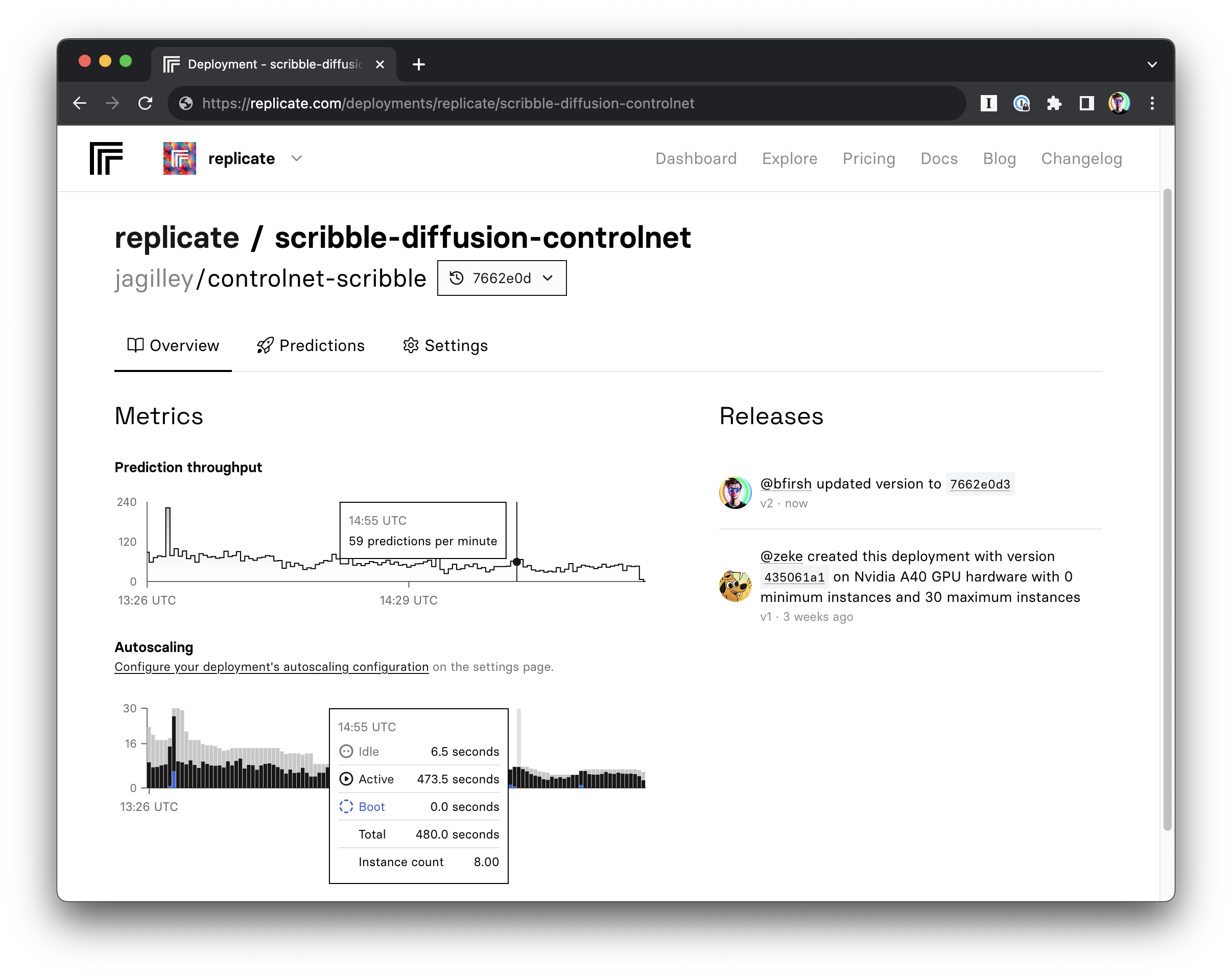
🚀 Check out the deployments guide to learn more and get started.
-
When you create a prediction on the web, we now append a query parameter
?prediction=<uuid>, so that if you refresh the page, you see that prediction instead of the form prefilled with the default inputs. Previously, if you created a prediction on the web and refreshed, you’d lose the prediction and have to go spelunking for it on your dashboard. -
You can now expand your training logs and view them full-screen.
---
-
✅ We’ve added a new feature to show the prediction status in the favicon of the browser tab. This makes it easier to know when your running predictions have completed without having to switch tabs.
-
Replicate’s API now supports server-sent event (SSE) streams for language models, giving you live output as the model is running. See the announcement blog post and our streaming guide for more details about how to use streaming output.
-
You can now create multiple personal API tokens at https://replicate.com/account/api-tokens
They’re just like organization tokens, but they’re only for your personal user account. You can name your tokens to make them distinguishable, and reset them if needed.
-
You can now run Replicate models on NVIDIA A40 GPUs. In terms of price and performance, the A40 sits between our T4 and A100 hardware. For many models, the A40 Large can be 80-90% as fast as A100s but almost half the price.
The A40 GPU is currently available in two configurations, each with the same GPU but attached to a machine with different amounts of CPU and RAM:
Hardware Price GPU CPU GPU RAM RAM Nvidia A40 GPU $0.0013 per second ($0.078 per minute) 1x 4x 48GB 16GB Nvidia A40 (Large) GPU $0.0016 per second ($0.096 per minute) 1x 10x 48GB 72GB To choose which GPU type is used to run your model, see the Hardware dropdown on your model’s settings page:
To compare price and performance of all available GPUs, see our pricing page.
-
Trainable model pages now have a section that indicates training hardware type and cost.
See https://replicate.com/a16z-infra/llama7b-v2-chat#training
-
We built a training API for fine-tuning language models, and today we’re making it available to all Replicate users.
You can fine-tune language models to make them better at a particular task, like classifying text, answering questions about your private data, being a chatbot, or extracting structured data from text.
You can train models like LLaMA 2, Flan T5, GPT-J and others. Check out the trainable language models collection to see what models can be fine-tuned, and stay tuned as we add support for more.
To get started, check out our guide to fine tuning a language model.
training = replicate.trainings.create( version="a16z-infra/llama7b-v2-chat:a845a72bb3fa3ae298143d13efa8873a2987dbf3d49c293513cd8abf4b845a83", input={ "train_data": "https://example.com/my-training-data.jsonl", }, destination="zeke/my-custom-llama-2" ) -
You can now see the Git commit and tag used to create new versions of a model. Run
brew upgrade cogto upgrade to the latest release.The next time you run
cog push, the current Git commit and tag for your model will automatically be included in the resulting Docker image, and it’ll show up on Replicate under the model page’s Versions tab. -
We’ve made a few improvements to the download mechanism on the website:
- If you ran a model that produces multiple outputs, you can download them all as a zip file.
- If you’re downloading a single output, it will now actually download instead of linking to the file’s URL.
Happy downloading!
-
You can now view a detailed summary of your invoices with a breakdown of cost, prediction time, and hardware for each model you ran.
Check out your billing settings at https://replicate.com/account/billing
-
Replicate now has a client library for Swift. It’s got everything you need to build an AI-powered app for iOS and macOS using Replicate’s HTTP API.
Add it as a package dependency to your project:
let package = Package( // name, platforms, products, etc. dependencies: [ // other dependencies .package(url: "https://github.com/replicate/replicate-swift", from: "0.12.1"), ], targets: [ .target(name: "<target>", dependencies: [ // other dependencies .product(name: "Replicate", package: "replicate-swift"), ]), // other targets ] )Then, you can run predictions:
import Replicate // Get your API token at https://replicate.com/account private let replicate = Replicate.Client(token: <#token#>) let output = try await replicate.run( "stability-ai/stable-diffusion:db21e45d3f7023abc2a46ee38a23973f6dce16bb082a930b0c49861f96d1e5bf", ["prompt": "a 19th century portrait of a wombat gentleman"] ) print(output) // ["https://replicate.com/api/models/stability-ai/stable-diffusion/files/50fcac81-865d-499e-81ac-49de0cb79264/out-0.png"]Follow our guide to building a SwiftUI app or read the full documentation on GitHub.
-
You can now use an organization to collaborate with other people on Replicate.
Organizations let you share access to models, API tokens, billing, dashboards, and more. When you run models as the organization, it gets billed to your shared credit card instead of your personal account.
To get started, use the new account menu to create your organization:
-
Replicate now has a client library for Node.js. You can use it to run models and everything else you can do with the HTTP API.
Install it from npm:
npm install replicateThen, you can run predictions:
import Replicate from "replicate"; const replicate = new Replicate({ auth: process.env.REPLICATE_API_TOKEN, }); const model = "stability-ai/stable-diffusion:27b93a2413e7f36cd83da926f3656280b2931564ff050bf9575f1fdf9bcd7478"; const input = { prompt: "a 19th century portrait of a raccoon gentleman wearing a suit" }; const output = await replicate.run(model, { input }); // ['https://replicate.delivery/pbxt/GtQb3Sgve42ZZyVnt8xjquFk9EX5LP0fF68NTIWlgBMUpguQA/out-0.png']Follow our guide to running a model from Node.js or read the full documentation on GitHub.
-
The “get a model” API operation now returns more metadata about the model:
run_count: an integer indicating how many times the model has been run.default_example: a prediction object created with this model, and selected by the model owner as an example of the model’s inputs and outputs.cover_image_url: an HTTPS URL string for an image file. This is an image uploaded by the model author, or an output file or input file from the model’s default example prediction.
Here’s an example using cURL and jq to get the Salesforce blip-2 model as a JSON object and pluck out some of its properties:
curl -s \ -H "Authorization: Token $REPLICATE_API_TOKEN" \ -H 'Content-Type: application/json' \ "https://api.replicate.com/v1/models/salesforce/blip-2" \ | jq "{owner, name, run_count, cover_image_url, default_example}"Here’s what the response looks like:
{ "owner": "salesforce", "name": "blip-2", "run_count": 270306, "cover_image_url": "https://replicate.delivery/pbxt/IJEPmgAlL2zNBNDoRRKFegTEcxnlRhoQxlNjPHSZEy0pSIKn/gg_bridge.jpeg", "default_example": { "completed_at": "2023-02-13T22:26:49.396028Z", "createdAt": "2023-02-13T22:26:48.385476Z", "error": null, "id": "uhd4lhedtvdlbnm2cyhzx65zpe", "input": { "image": "https://replicate.delivery/pbxt/IJEPmgAlL2zNBNDoRRKFegTEcxnlRhoQxlNjPHSZEy0pSIKn/gg_bridge.jpeg", "caption": false, "question": "what body of water does this bridge cross?", "temperature": 1 }, "logs": "...", "metrics": { "predict_time": 0.949567 }, "output": "san francisco bay", "started_at": "2023-02-13T22:26:48.446461Z", "status": "succeeded", "version": "4b32258c42e9efd4288bb9910bc532a69727f9acd26aa08e175713a0a857a608", } }See the “get a model” API docs for more details.
-
Every model on Replicate describes its inputs and outputs with OpenAPI Schema Objects in the
openapi_schemaproperty. This is a structured JSON object that includes the name, description, type, and allowed values for each input or output parameter.Today we’ve improved our API reference documentation to clarify how to get a model’s input and output schema.
See the updated docs at https://replicate.com/docs/reference/http#models.versions.get
Here’s an example of how to get the input schema for Stable Diffusion using cURL:
curl -s \ -H "Authorization: Token $REPLICATE_API_TOKEN" \ -H 'Content-Type: application/json' \ "https://api.replicate.com/v1/models/stability-ai/stable-diffusion/versions/db21e45d3f7023abc2a46ee38a23973f6dce16bb082a930b0c49861f96d1e5bf" | jq ".openapi_schema.components.schemas.Input.properties"Using this command, we can see all the inputs to Stable Diffusion, including their types, description, min and max values, etc:
{ "seed": { "type": "integer", "title": "Seed", "x-order": 7, "description": "Random seed. Leave blank to randomize the seed" }, "prompt": { "type": "string", "title": "Prompt", "default": "a vision of paradise. unreal engine", "x-order": 0, "description": "Input prompt" }, "scheduler": { "allOf": [ { "$ref": "#/components/schemas/scheduler" } ], "default": "DPMSolverMultistep", "x-order": 6, "description": "Choose a scheduler." }, "num_outputs": { "type": "integer", "title": "Num Outputs", "default": 1, "maximum": 4, "minimum": 1, "x-order": 3, "description": "Number of images to output." }, "guidance_scale": { "type": "number", "title": "Guidance Scale", "default": 7.5, "maximum": 20, "minimum": 1, "x-order": 5, "description": "Scale for classifier-free guidance" }, "negative_prompt": { "type": "string", "title": "Negative Prompt", "x-order": 2, "description": "Specify things to not see in the output" }, "image_dimensions": { "allOf": [ { "$ref": "#/components/schemas/image_dimensions" } ], "default": "768x768", "x-order": 1, "description": "pixel dimensions of output image" }, "num_inference_steps": { "type": "integer", "title": "Num Inference Steps", "default": 50, "maximum": 500, "minimum": 1, "x-order": 4, "description": "Number of denoising steps" } }And here’s a command to the get the output schema:
curl -s \ -H "Authorization: Token $REPLICATE_API_TOKEN" \ -H 'Content-Type: application/json' \ "https://api.replicate.com/v1/models/stability-ai/stable-diffusion/versions/db21e45d3f7023abc2a46ee38a23973f6dce16bb082a930b0c49861f96d1e5bf" | jq ".openapi_schema.components.schemas.Output"From this command, we can see that Stable Diffusion output format is a list of URL strings:
{ "type": "array", "items": { "type": "string", "format": "uri" }, "title": "Output" } -
OpenAPI (formerly known as Swagger) is a specification for describing HTTP APIs with structured data, including the available endpoints, their HTTP methods, expected request and response formats, and other metadata.
You can use this schema as a reference document, or to auto-generate your own API client code, or to mock and test your existing use of Replicate’s API.
All of the documentation you see on the HTTP API reference page is also available as a structured OpenAPI JSON schema.
Download the schema at api.replicate.com/openapi.json
-
You can now browse through all the models on Replicate. Check them out on the Explore page!

-
When you create a prediction with the API, you can provide a webhook URL for us to call when your prediction is complete.
Starting today, we now send more webhook events at different stages of the prediction lifecycle. We send requests to your webhook URL whenever there are new logs, new outputs, or the prediction has finished.
You can change which events trigger webhook requests by specifying
webhook_events_filterin the prediction request.start: Emitted immediately on prediction start. This event is always sent.output: Emitted each time a prediction generates an output (note that predictions can generate multiple outputs).logs: Emitted each time log output is generated by a prediction.completed: Emitted when the prediction reaches a terminal state (succeeded/canceled/failed). This event is always sent.
For example, if you only wanted requests to be sent at the start and end of the prediction, you would provide:
{ "version": "5c7d5dc6dd8bf75c1acaa8565735e7986bc5b66206b55cca93cb72c9bf15ccaa", "input": { "text": "Alice" }, "webhook": "https://example.com/my-webhook", "webhook_events_filter": ["start", "completed"] }Requests for event types
outputandlogswill be sent at most once every 500ms.Requests for event types
startandcompletedwill always be sent.If you’re using the old
webhook_completed, you’ll still get the same webhooks as before, but we recommend updating to use the newwebhookandwebhook_completedproperties.Docs: https://replicate.com/docs/reference/http#create-prediction—webhook
-
We’ve made it even easier to start building with Replicate’s API. When you click on the API tab for a model, the Python example code now has everything you need to run a prediction, including code for all of the model’s inputs and outputs. These new code snippets include documentation and defaults for each input, so you can focus on coding, with less context switching between the API docs and your editor.
To learn more about how to get started, check out our “Run a model from Python” guide.

-
Have you ever kicked off a prediction, then, after thinking about it, realized you got one of the settings wrong or wanted to tweak the prompt? Well, now you can cancel that prediction, even if you’ve navigated away from the page you were on or made it through the API. On the website, go to your dashboard, find the running prediction, and you’ll now see it live-updating with a handy “Cancel” button.

-
🍏 Hey macOS users! There’s now a Homebrew formula for Cog. Use
brew install cogto install it, andbrew upgrade cogto upgrade to the latest version. See https://github.com/replicate/cog#install -
We’ve added img2img support to models created with our DreamBooth API.
This means you can optionally send both a
promptand initialimageto generate new images (in addition to the other parameters specified in your DreamBooth model’s API page).Input:
prompt: photo of zeke playing guitar on stage at concertimage: https://www.pexels.com/photo/man-playing-red-and-black-electric-guitar-on-stage-167382/
Output:

To get started building and pushing your own DreamBooth model, check out the blog post.
-
You can now manually delete a prediction on the website. You’ll find a “Delete” button on the prediction detail page, e.g.
https://replicate.com/p/{prediction_id}. Clicking this link will completely remove the prediction from the site, including any output data and output files associated with it.
-
By popular request, we no longer store data for predictions made using the API.
User data is automatically removed from predictions an hour after they finish. The prediction itself is not deleted, but the
inputandoutputdata for the prediction is removed. This only applies to predictions created with the API, but not predictions created on the website.This is enabled for new accounts starting today, but we know that some users may be relying on prediction data to exist for more than an hour, so we’ve not enabled this for any existing accounts.
-
We now have a changelog for product updates at replicate.com/changelog. We used to use a single tweet thread as our makeshift changelog, but decided it was time to make something a bit more flexible. Stay tuned for more frequent updates here!
-
Stable Diffusion now has release notes so you can see what’s changed: replicate.com/stability-ai/stable-diffusion/versions. It only works on Stable Diffusion at the moment. Coming soon to all models so you can set release notes on your own models and see what has changed on other people’s models.
-
We’ve also increased our default rate limits. You can create 10 predictions a second, bursting up to 600 predictions a second. https://replicate.com/docs/reference/http#rate-limits
We can support higher rates too – email us: team@replicate.com
-
Over the past few weeks, we’ve made some major improvements to our infrastructure to make it more reliable and perform better. Nothing’s changed from your point of view, but you’ll be seeing faster response times! 🚀
-
You can now run your own models on Nvidia A100s. Click the settings tab on your model and select the hardware option to upgrade. 🚀
-
You can now set a monthly spend limit on your account to avoid getting a surprising bill. 🦆
To set a limit, visit https://replicate.com/account#limits
-
🪝 Our API now supports webhooks, as an alternative to polling. Specify your webhook URL when creating a prediction and we’ll POST to that URL when your prediction has completed! See the API docs here: https://replicate.com/docs/reference/http#create-prediction
-
“We’ve started curating collections of models that perform similar tasks. First up is an assortment of ✨style transfer✨ models that take a content image and a style reference to produce a new image, like this starry night cat. https://replicate.com/collections/style-transfer
-
“When you run a model that changes over time, you can scrub back and forth to see the previous output. We’ve now added that scrubber to predictions in the example gallery, so you can see how they morphed into being: https://replicate.com/pixray/text2image/examples