Run a model
Learn how to run a machine learning model in a web playground or with an API that uses Replicate.
Table of contents
You can run models on Replicate using the web or the API.
Run a model on the web
Every model on Replicate has its own “playground” page with a web form for running the model. The playground is a good place to start when trying out a model for the first time. It gives you a visual view of all the inputs to the model, and generates a form for running the model right from your browser:
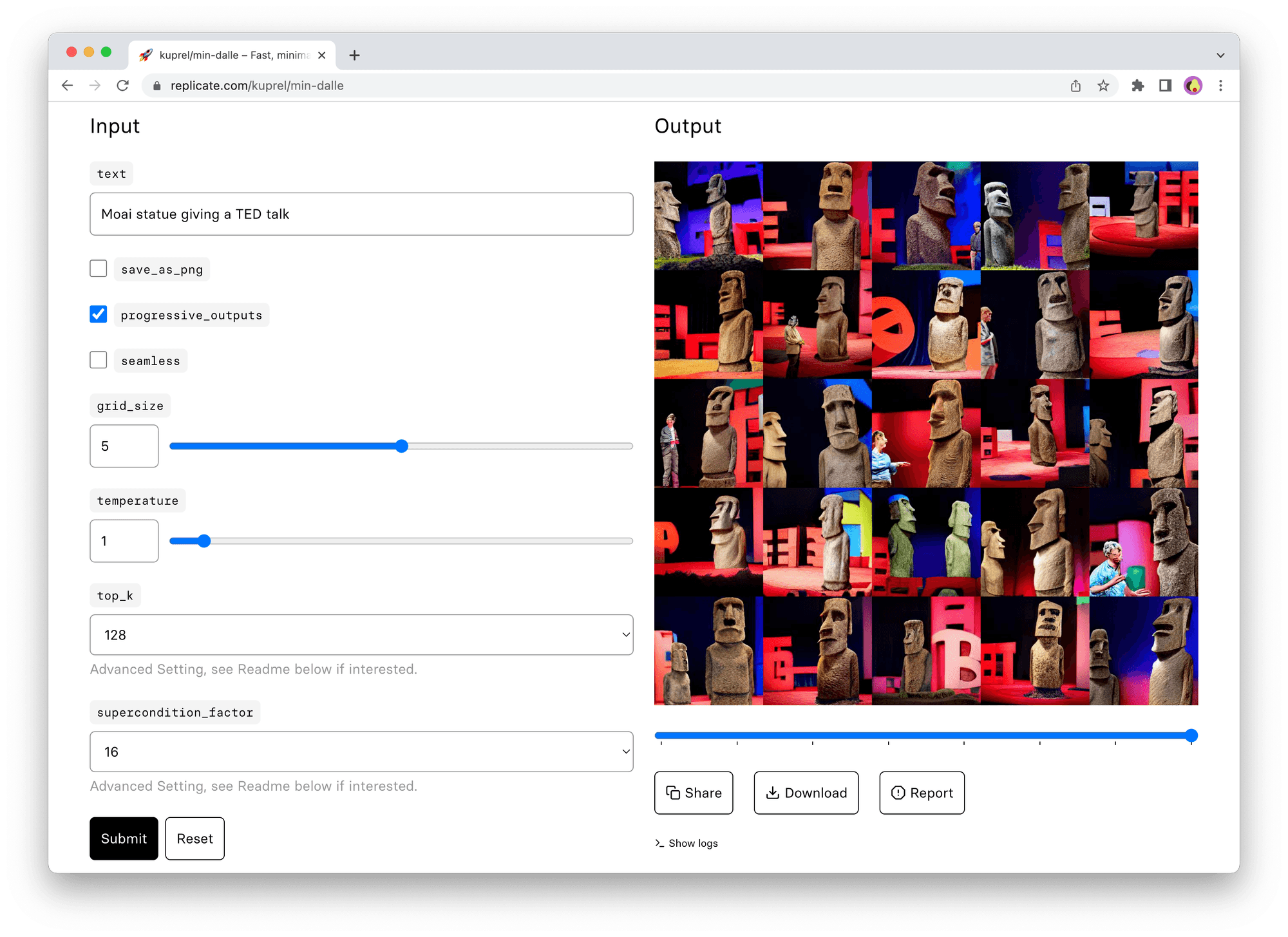
Once you’ve tried out a model in the playground, you can easily run the model from your own code using the API.
Run a model with the API
The web playground is great for getting acquainted with a model, but when you’re ready to integrate a model into something like a chat bot, website, or mobile app, you’ll want to use the API.
Our HTTP API can be used with any programming language, but there are also client libraries for Python, JavaScript, and other languages that make it easier to use the API.
Using the Python client, you can create predictions with just a few lines of code:
import replicate
output = replicate.run(
"black-forest-labs/flux-schnell",
input={"prompt": "an astronaut riding a horse"}
)
# Save the output image
with open('output.png', 'wb') as f:
f.write(output[0].read())The JavaScript client works similarly:
import Replicate from "replicate";
const replicate = new Replicate({ auth: process.env.REPLICATE_API_TOKEN });
const model = "black-forest-labs/flux-schnell";
const input = {
prompt: "a 19th century portrait of a raccoon gentleman wearing a suit",
};
const output = await replicate.run(model, { input });
// Save the output image
fs.writeFileSync("output.png", output[0]);For more details on how to run models with the API, including how to handle output files, see Create a prediction and Output files.
Warm models
We have a huge catalogue of models. To make good use of resources, we only run the models that are actually being used. When a model hasn’t been used for a little while, we turn it off.
When you make a request to run a prediction on a model, you’ll get a fast response if the model is “warm” (already running), and a slower response if the model is “cold” (starting up). Machine learning models are often very large and resource intensive, and we have to fetch and load several gigabytes of code for some models. In some cases this process can take several minutes.
Cold boots can also happen when there’s a big spike in demand. We autoscale by running multiple copies of a model on different machines, but the model can take a while to become ready.
For popular public models, cold boots are uncommon because the model is kept “warm” from all the activity. For less-frequently used models, cold boots are more frequent.
If you’re using the API to create predictions in the background, then cold boots probably aren’t a big deal: we only charge for the time that your prediction is actually running, so it doesn’t affect your costs.
Environment variables
We expose the following metadata as environment variables in a running container.
They can be used to identify the image, version, deployment, when debugging or instrumenting your model.
REPLICATE_USERNAME- username, e.g.my-unicorn-ai-startupREPLICATE_MODEL_NAME- model name, e.g.pony-generatorREPLICATE_DOCKER_IMAGE_URI- Docker image URI, e.g.r8.im/<username>/<model_name>@<image_hash>REPLICATE_VERSION_ID- model version, usually the same as image hashREPLICATE_DEPLOYMENT_NAME- deployment name, if running as a deployment
These environment variables are accessible to your code in public models, private models, and deployments.