How does Replicate work?
Replicate lets you run machine learning models with a cloud API, without having to understand the intricacies of machine learning or manage your own infrastructure.
Replicate lets you run machine learning models with a cloud API, without having to understand the intricacies of machine learning or manage your own infrastructure.
You can run open-source models that other people have published, or bring your own training data to create fine-tuned models, or build and publish custom models from scratch.
Terminology
Let’s start by defining some important terms that you’ll need to know:
Models
In the world of machine learning, the word “model” can mean many different things depending on context. It can be the source code, the trained weights, the architecture, or some combination thereof. At Replicate, when we say “model” we’re generally referring to a trained, packaged, and published software program that accepts inputs and returns outputs.
Versions
Just like normal software, machine learning models change and improve over time, and those changes are released as new versions. Whenever a model author retrains a model with new data, fixes a bug in the source code, or updates a dependency, those changes can influence the behavior of the model. The changes are published as new versions, so model authors can make improvements without disrupting the experience for people using older versions of the model. Versioning is essential to making machine learning reproducible: it helps guarantee that a model will behave consistently regardless of when or where it’s being run.
Predictions
Every time you run a model, you’re creating a prediction. A prediction is an object that represents a single result from running the model, including the inputs that you provided, the outputs that the model returned, as well as other metadata like the model version, the user who created it, the status of the prediction, and timestamps.
Running models in the browser
You can run models on Replicate using the cloud API or the web.
The web interface is a good place to start when trying out a model for the first time. It gives you a visual view of all the inputs to the model, and generates a form for running the model right from your browser:
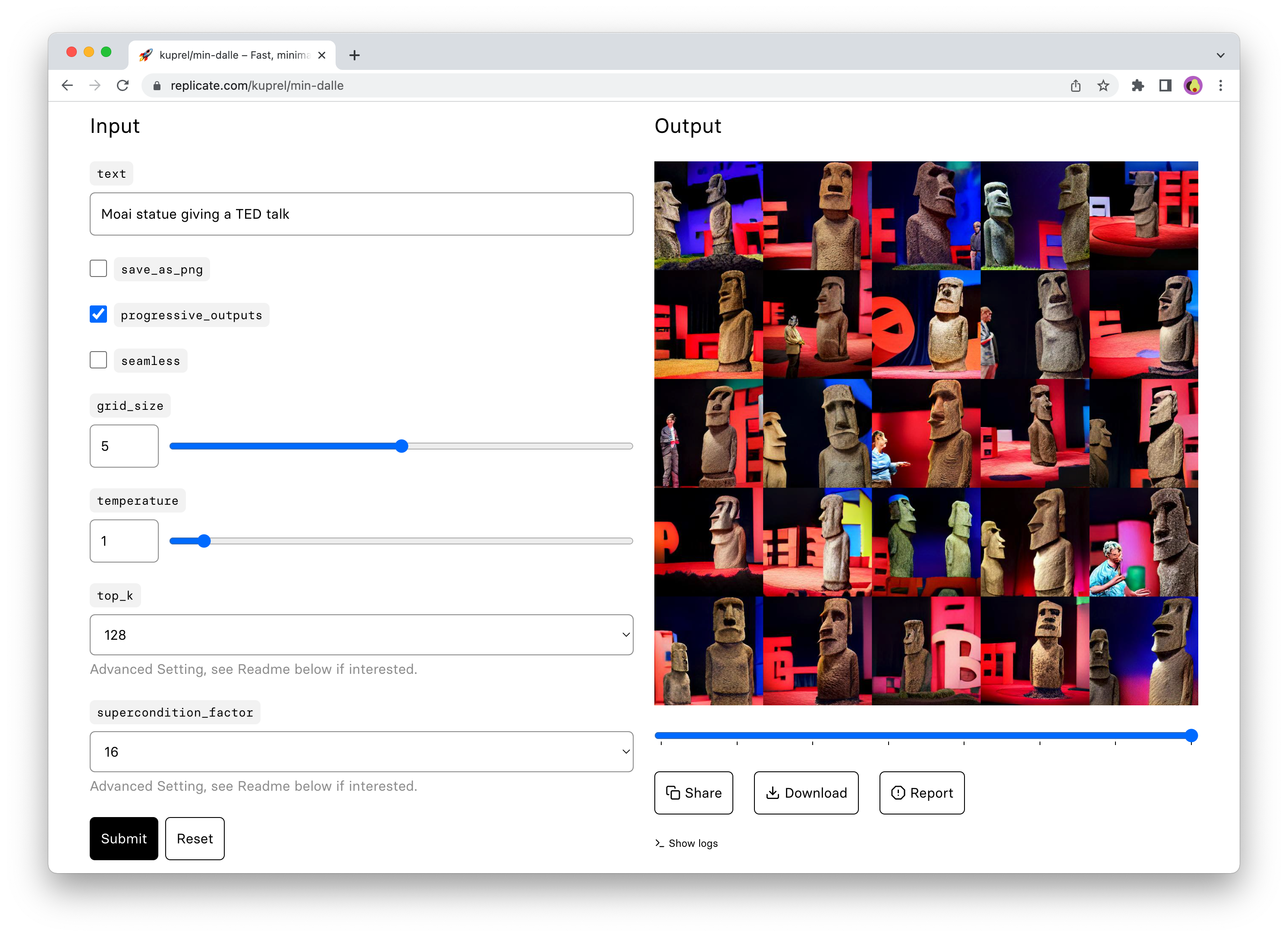
Running models with the API
The web interface is great for getting acquainted with a model, but when you’re ready to integrate a model into something like a chat bot, website, or mobile app, that’s when the API comes into play.
Our HTTP API can be used with any programming language, but there are also client libraries for Python, JavaScript, and other languages that make it easier to use the API.
Using the Python client, you can create predictions with just a few lines of code:
import replicate
output = replicate.run(
"black-forest-labs/flux-schnell",
input={"prompt": "an astronaut riding a horse"}
)
# Save the output image
with open('output.png', 'wb') as f:
f.write(output[0].read())The JavaScript client works similarly:
import Replicate from "replicate";
const replicate = new Replicate({auth: process.env.REPLICATE_API_TOKEN});
const model = "black-forest-labs/flux-schnell";
const input = {prompt: "a 19th century portrait of a raccoon gentleman wearing a suit"};
const output = await replicate.run(model, { input });
// Save the output image
fs.writeFileSync("output.png", output[0]);How predictions work
Whenever you run a model, you’re creating a prediction.
Some models run very quickly and can return a result within a few milliseconds. Other models can take longer to run, especially generative models, like the kind which produce images from text prompts.
For these long-running models, you need to poll the API to check the status of a prediction. Predictions can have any of the following statuses:
starting: the prediction is starting up. If this status lasts longer than a few seconds, then it’s typically because a new worker is being started to run the prediction. Refer to Cold boots.processing: thepredict()method of the model is currently running.succeeded: the prediction completed successfully.failed: the prediction encountered an error during processing.canceled: the prediction was canceled by the user.
Predictions timeout after running for 30 minutes. If you require more than 30 minute timeouts for predictions, contact us.
When you’re logged in, you can view a list of your predictions on the dashboard, with summaries of status, run time, etc:

Share predictions
Every prediction that you create is associated with your user account, and only you can see the predictions that you create. If you’re using the web interface, then you can click the “Share” button to make the prediction public, so that others can view it.
Delete predictions
Input and output (including any files) are automatically deleted after an hour for any predictions created through the API, so you must save a copy of any files in the output if you’d like to continue using them. For more details on how to store prediction data, see the guide to webhooks.
Predictions created through the web interface are kept indefinitely, unless you delete them manually.
To manually delete a prediction on the website, go to your dashboard, find the prediction, and look for a “Delete” button on the prediction page. Clicking this button completely removes the prediction from the site, including any output data and output files associated with it.
Prediction output files
When models generate files (like images, audio, or video), they return FileOutput objects that provide direct access to the file data. This makes it easy to save or process the files in your code.
The FileOutput interface differs slightly between Python and JavaScript. Let’s look at each:
Python
In Python, the FileOutput is based on httpx.Response and provides:
- Direct access to the file data through
read()or asyncaread() - A
urlattribute that points to where the file is hosted (see Working with URLs) - Streaming capabilities as the
FileOutputis both an Iterator and AsyncIterator
Here’s how to work with output files in Python:
import replicate
output = replicate.run(
"black-forest-labs/flux-schnell",
input={"prompt": "an astronaut riding a horse"}
)
# Save the output image
with open('output.png', 'wb') as f:
f.write(output[0].read())JavaScript
In JavaScript, the FileOutput is based on the Response object and provides:
- Direct access to the file data via
.blob() - A
url()method that returns a URL to the file (see Working with URLs) - Streaming capabilities as the
FileOutputis aReadableStream.
Here’s how to work with output files in JavaScript:
import Replicate from "replicate";
const replicate = new Replicate();
const output = await replicate.run(
"black-forest-labs/flux-schnell",
{ input: { prompt: "an astronaut riding a horse" }}
);
// Save the output image
await fs.writeFile("output.png", output[0]);For both Python and JavaScript, the url property (or url() method in JavaScript) will return
the URL pointing to the underlying data source.
Output files are served via replicate.delivery and its subdomains. If you use an allow list of external domains for your assets, add replicate.delivery and *.replicate.delivery to it.
For example, if you’re building a Next.js app that displays output files from Replicate, update your Next.js config as follows:
const nextConfig = {
images: {
remotePatterns: [
{
protocol: "https",
hostname: "replicate.delivery",
},
{
protocol: "https",
hostname: "*.replicate.delivery",
}
]
}
}To stream file data back from a Next.js handler, you can do this:
export async function GET(request: Request) {
const output = await replicate.run(...);
return new Response(output);
}For more details about working with output files, see the Output files documentation.
Which models can you run?
You can use the API or the web interface to run any public model on Replicate from your own code. It can be an open-source model created by someone else, like meta/meta-llama-3-70b-instruct or stability-ai/sdxl, or you can publish and run your own models.
You can also push your own model to Replicate. Refer to Pushing your own models.
Finding models
You can find models to run by exploring popular and featured models or searching for something specific.
The search returns models that meet the following criteria:
- The model is public.
- The model has at least one published version.
- The model has at least one example prediction. To add an example, create a prediction using the web interface then click the “Add to examples” button below the prediction output.
If you’re pushing your own models and want others to be able to discover them, make sure they meet the above criteria.
Pricing
Take a look at the page on how billing works.
Commercial use
The models on Replicate have been built and contributed by different people and organizations, and the licenses vary for each model. Here are a few examples:
For Stable Diffusion, neither Replicate nor the authors of the model claim any ownership over the output. For details, see the Stable Diffusion license, and Replicate’s terms of service.
Other models like Pixray have some restrictions on commercial use.
You can view the license for a model by clicking the button at the top right of the model page:

Safety
Image generation models like Stability AI’s SDXL include a safety checker to prevent the model from generating images that portray nudity, violence, and other unsafe content.
To protect users from generating unsafe content, we enable the safety checker for web predictions on the SDXL base model and all derivative fine-tunes of SDXL.
The safety checker is intended to protect users, but it can sometimes be too restrictive or generate false positives, incorrectly flagging safe content as unsafe. For those cases, you can disable the safety checker when running the model with the API. This gives you the flexibility to use a custom safety-checking model or a third-party service as part of your workflow.
For more details on allowed use, see the terms of service.
Cold boots
We have a huge catalogue of models. To make good use of resources, we only run the models that are actually being used. When a model hasn’t been used for a little while, we turn it off.
When you make a request to run a prediction on a model, you’ll get a fast response if the model is “warm” (already running), and a slower response if the model is “cold” (starting up). Machine learning models are often very large and resource intensive, and we have to fetch and load several gigabytes of code for some models. In some cases this process can take several minutes.
Cold boots can also happen when there’s a big spike in demand. We autoscale by running multiple copies of a model on different machines, but the model can take a while to become ready.
For popular public models, cold boots are uncommon because the model is kept “warm” from all the activity. For less-frequently used models, cold boots are more frequent.
If you’re using the API to create predictions in the background, then cold boots probably aren’t a big deal: we only charge for the time that your prediction is actually running, so it doesn’t affect your costs.
If you are running a model that you need to keep warm, you can create a deployment for it. Deployments allow you to customize the hardware and scaling configuration of a model. You can create a deployment with minimum instances set to 1 or more to ensure that it is always running and ready to respond to requests.
Rate limits
We limit the number of API requests that can be made to Replicate.
See the HTTP API reference docs for more details.
Organizations
You can use an organization to collaborate with other people on Replicate.
Organizations let you share access to models, API tokens, billing, dashboards, and more. When you run models as the organization, it gets billed to your shared credit card instead of your personal account.
You can also use organizations to create private models that are only visible to people on your team.
To get started, use the account menu to create your organization:
Push your own models
In addition to running other people’s models, you can push your own models to Replicate. You can make your model public so that other people can run it, or you can make it private so that only you can run it.
To learn more, check out Push a model to Replicate.
Private models
When creating a model on Replicate, you can choose whether to make it public or private.
You can create a private model on your personal account, and it will only be visible to you.
You can also create a private model in an organization to share it with members of your team.
To create a private model, go to replicate.com/create and select the “Private” option:
To learn more, check out the guide to deploying a custom model.
Get support
Stuck on something? Our community’s here to help. Find us in Discord.