Publish a model
Best practices for publishing reliable, fast, and user-friendly models.
Table of contents
Whether you’re building a private model with your team, or a public model to share with the community, it’s important to document what your model does and how to use it.
This page has tips for improving your model to make it more discoverable, well-documented, and user-friendly.
If you’ve never created a model before, start by reading the guide to creating a model with Cog or the guide to fine-tuning Flux.
What are examples?
The best models include examples.
Examples are predictions on a model that are shared by the model author.
When you land on a Replicate model page, the first thing you see is the model playground, with inputs and outputs:
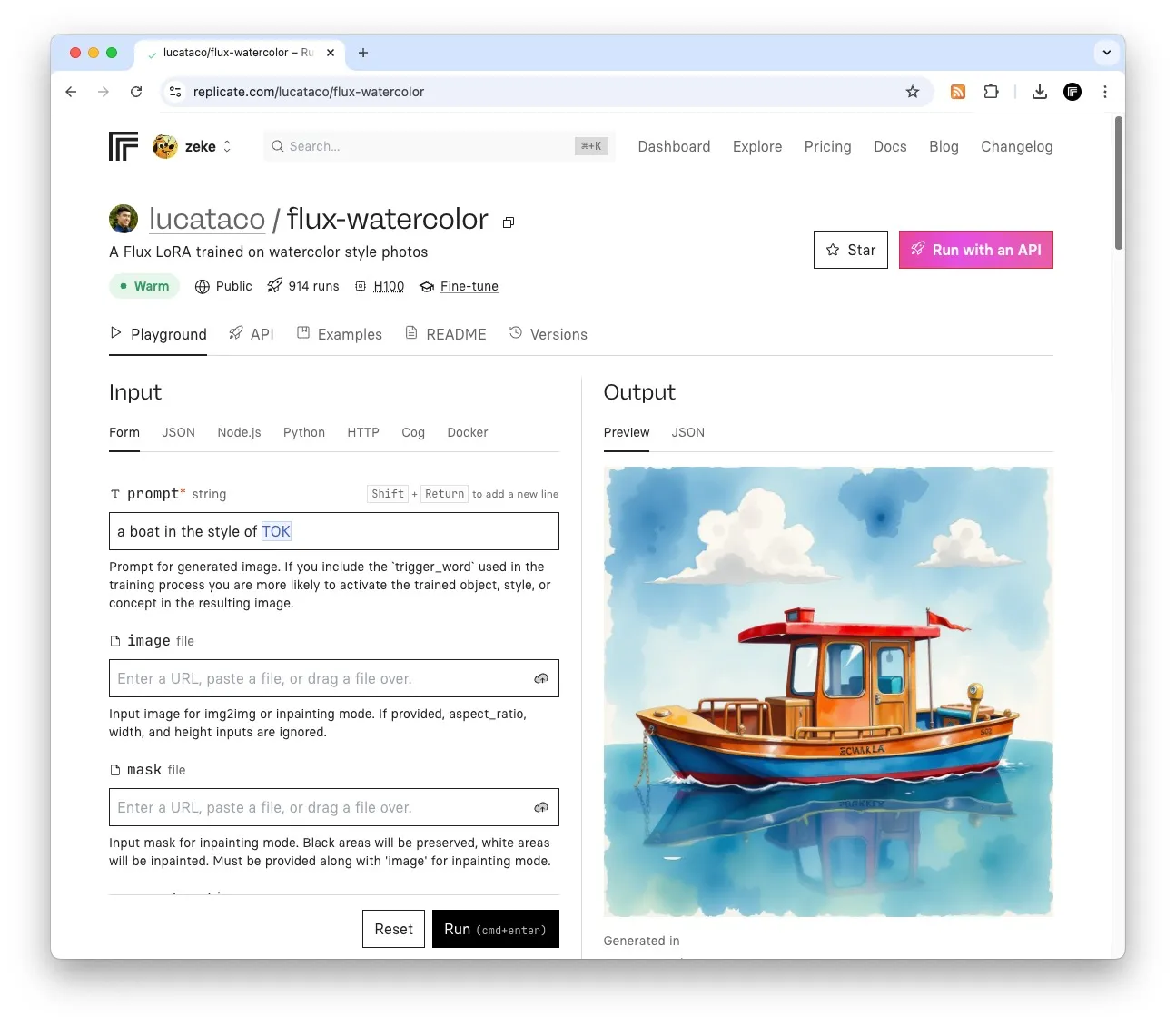
When your model has examples, the playground page is more useful and intuitive to new users or your model, as the input form and outputs are pre-populated with starting values that users can modify. This makes it easier to see at a glance what your model does and how to use it.
Add examples
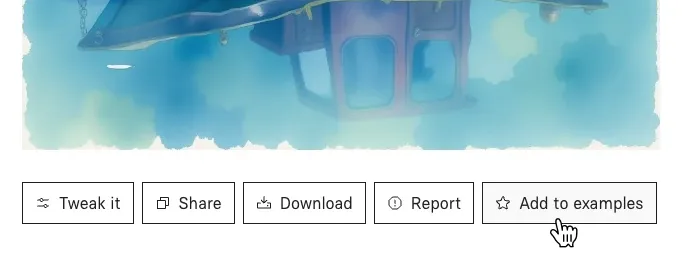
To add examples to your model, run the model in the playground and look for the Add to Examples button below the prediction output:
Write a model description
Keep your model descriptions concise and clear.
Avoid technical terms and abbreviations in your description.
Here are some examples that are vague, confusing, or overly technical:
- “Arbitrary Neural Style Transfer”
- “Generating Conditional 3D Implicit Functions”
- “Zeroscope V2 XL & 576w”
Here are some better examples that are more clear and descriptive:
- “Add captions to a video”
- “A language model from Meta, fine tuned for chat completions”
- “Use Stable Diffusion and aesthetic CLIP embeddings to guide boring outputs to be more aesthetically pleasing.”
To edit the description of your model:
- Go to the model page
- Click the Settings tab
- Edit the description
- Click Save
Write helpful input descriptions
Every model has inputs, and every input has a description.
Input descriptions are displayed below each form field in the web playground, as well as the API reference docs for each model.
It’s very important to write good descriptions for your inputs, because they’ll make or break the experience for people using your model.

Inputs are defined in the Cog model’s source code in a Python file, typically named predict.py. See Predictor API docs for more details.
Here’s an example of a bad input description:
guidance_scale: float = Input(
description="Scale for classifier-free guidance.",
ge=1,
le=50,
default=7.5
),If you’re a machine learning expert, maybe this description is enough to understand what the input does. But for most people, that’s not enough information.
Here’s an example of a good input description that explains what the input does, how to use it, and what effect different values might have on the output:
guidance_scale: float = Input(
description="""Scale for classifier-free guidance. This value determines how
much the image generation follows the prompt. Higher values
make the output more closely aligned with the prompt but may
reduce image quality. Values typically range from 7 to 15,
where 7 is a good starting point. Lower values allow more
creative freedom but may stray from the prompt.""",
ge=1,
le=50,
default=7.5
),Don’t be afraid to write long descriptions for your inputs. Use triple quotes to allow for multiple lines of text, and use line breaks to make the description more readable. Your users will thank you for it.
Add a README
GitHub popularized the README file as a way to describe what a project is and how to use it. In the AI community, this concept has evolved into AI model cards, which provide structured information about machine learning models.
Include the following information in your README, which can also serve as a model card:
- A description of what the model does
- How to use the model
- Common use cases
- Limitations and ethical considerations
- Model details (e.g., architecture, training data, performance metrics)
- Intended uses and out-of-scope uses
- Troubleshooting tips
- Citations and acknowledgments
Providing this information in your README helps users understand and use your model, and also promotes transparency and responsible AI development.
Displayworthy models
We have some requirements that models must meet to be considered “displayworthy”.
In order for a model to be featured on the explore page, or to show up in search results, or to be returned by the “List models” API, it must meet these criteria:
- The model must have at least one version.
- The model must have at least one example prediction.
- The model must be public.
If you’re building a model that you want others in the community to be able to discover and use, make sure it meets these criteria.
Iterate and build new versions
Cog models are versioned just like normal software projects, which means you can create the model once and then continually make improvements to it, and publish those improvements as new versions.
For more details, see model versions.