
Readme
CLIP Age Predictor 📸⏳
Welcome to the CLIP Age Predictor! 👋 This project is a reimagination of a prior implementation of clip-age-predictor by Andreas Jansson. Due to some compatibility issues, we’ve updated it to work ensuring it’s up-to-date with the latest libraries and frameworks. 👩💻
We no longer get the error:
“”“
😵 Uh oh! This model can’t be run on Replicate because it was built with a version of Cog that is no longer supported. Consider opening an issue on the model’s GitHub repository to see if it can be updated to use a recent version of Cog. If you need any help, please hop into our Discord channel or email us about it.
“”“
Just upload a picture and hit "Submit"! 📸
What Does This Code Do? 🧐
In essence, our code uses OpenAI’s CLIP model 🚀 to predict a person’s age based on a provided image, creating a novel and fun AI-powered age guessing game!
Here’s the breakdown:
-
Setting up Prompts: We first set up ‘prompts’, sentences like
"this person is {age} years old". We have 99 of these, ranging from 1 to 99 years old. -
Model Preparation: We load the CLIP model and preprocess these prompts, converting them into a format (a tensor of encoded text) that the model understands.
-
Image Processing: The input image is also preprocessed to ensure that the model can extract meaningful features from it.
-
Cosine Similarity Computation: The core of our age prediction lies in computing the cosine similarity between the processed image and each of our age prompts.
Cosine similarity measures the cosine of the angle between two vectors. This value can range from -1 to 1, indicating complete oppositeness and perfect similarity, respectively. We’re exploiting the fact that when vectors are similar (meaning they point in roughly the same direction), their cosine similarity approaches 1.
Applying this to our scenario, we’re comparing the ‘direction’ or ‘meaning’ captured by our image with the ‘directions’ or ‘meanings’ of our age prompts. If the image aligns more closely with the vector for “this person is 22 years old” than any other prompt, we get a high cosine similarity, indicating that the person in the image is likely around 22 years old!
Under the Hood: CLIP and Contrastive Losses 🧠🔧
OpenAI’s CLIP (Contrastive Language–Image Pretraining) is a groundbreaking model that excels at deciphering the interplay between images and text. But what sets it apart from other models is its usage of ‘contrastive losses’ – an innovative strategy that refines the model’s capability to generalize and understand data.
Let’s peel back the layers to understand what contrastive loss really entails.
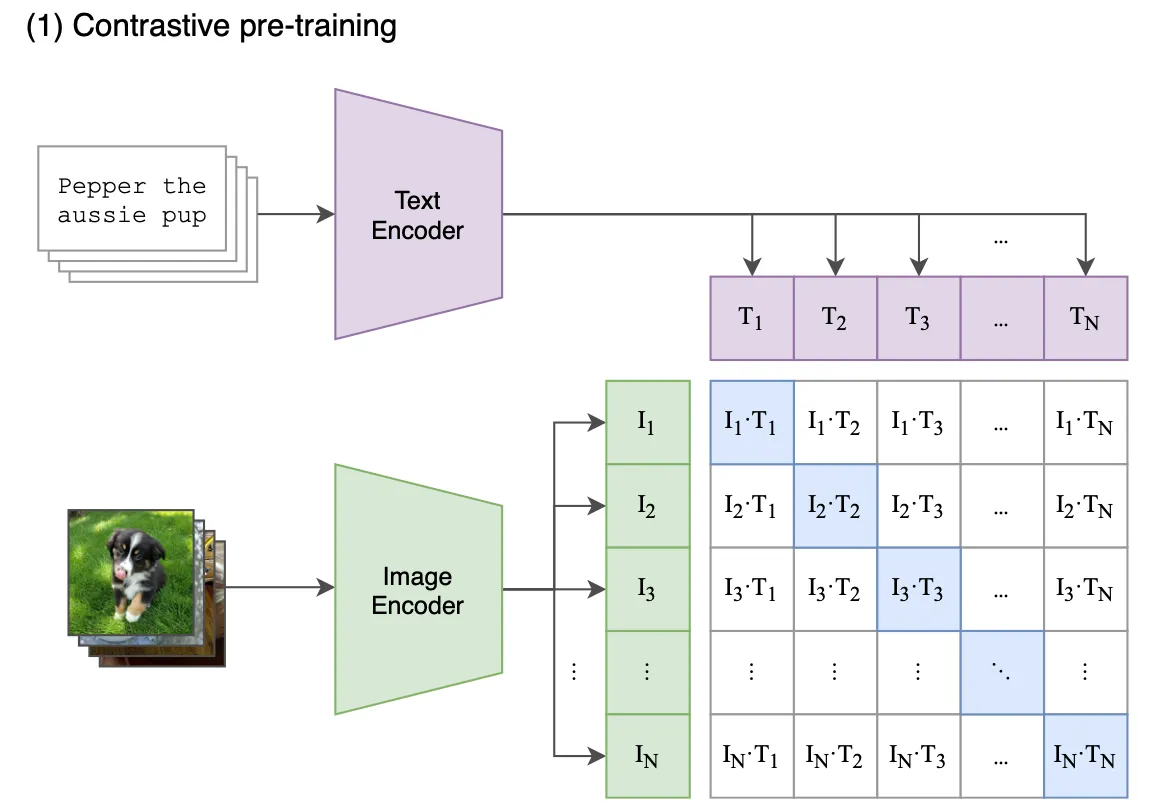
At its core, contrastive losses function like a compass for the model during its training journey. It’s a distinctive loss function that excels in representation and self-supervised learning tasks. The primary aim here is to learn representations that draw similar instances closer (an image and its relevant text) while driving dissimilar instances apart (like an image paired with a random unrelated text).
The above image essentially portrays a similarity matrix, with each cell signifying the degree of similarity or difference between two instances (image and text). These instances are represented as embeddings within a high-dimensional space.
Let’s dive deeper:
-
The Matrix: The square matrix in the image signifies the relationships among diverse instances in our dataset. Every row and column equates to a unique instance in the dataset – images and sentences (alt tags from the internet).
-
Positive Pairs (Diagonal Elements): Diagonal elements of the matrix denote ‘positive pairs’. These are pairs of instances considered similar or related. For instance, in an image-caption dataset, a positive pair could be an image and its accurate caption. The objective is to minimize the distance between these pairs in the embedding space, thereby aligning similar items more closely.
-
Negative Pairs (Non-Diagonal Elements): Non-diagonal elements of the matrix signify the ‘negative pairs’. These pairs consist of instances considered dissimilar or unrelated. In an image-caption scenario, a negative pair could be an image and an unrelated caption. The goal here is to maximize the distance between these pairs in the embedding space, pushing dissimilar items further apart.
During the training phase, the model is fine-tuned to enhance the similarity of positive pairs while expanding the dissimilarity between negative pairs. This simultaneous push-and-pull dynamic, regulated by the contrastive loss function, facilitates the learning of more robust and discriminative representations.
Contrary to traditional ImageNet-style loss functions, which handle each classification problem independently, contrastive losses impart a more holistic understanding of data to the model. Instead of just processing individual images or texts, the model learns to comprehend the underlying relationships within the text-image data constellation. This ability to grasp the context, discern analogies, and understand abstract concepts positions CLIP as an ideal choice for tasks like age prediction!
The Art and Science of Predicting Age 🎨⚗️
Predicting age in this manner might seem a bit ‘hacky’, but it’s a testament to the flexibility of the CLIP model. CLIP is not explicitly trained to guess ages, yet it manages to perform this task by leveraging its understanding of the associations between images and prompts.
Remember, its predictions are educated guesses based on its training and the prompts provided, so the quality of input can influence the accuracy of its predictions. 📈🎯
Building with Cog 🛠️
Before you start, make sure you have Cog installed. Cog streamlines the process of building and deploying models, provided you have a CUDA-enabled GPU compatible with PyTorch > 1.8.
Just run the following command in your terminal:
cog build
This command will start the building process.
Executing a Prediction 🏃♀️
Executing a prediction is straightforward. After successfully building with Cog, you can run the predictor with the following command:
cog predict -i image=@image.jpg
For example, with an input image of a person, the script provides an age prediction like so:
Running prediction...
19
I’m actually 22 in the picture, so nice guess!
That’s the model’s best guess at the person’s age in the image. Remember, it’s an estimate, not an absolute fact. Enjoy the magic of artificial intelligence, brought to life by the wonders of CLIP and the ingenious use of contrastive losses!