Painting with words: a history of text-to-image AI
With the recent release of Stable Diffusion XL fine-tuning on Replicate, and today being the 1-year anniversary of Stable Diffusion, now feels like the perfect opportunity to take a step back and reflect on how text-to-image AI has improved over the last few years.
We’ve seen AI generated images ascend from incomprehensible piles of eyeballs and noise, to high quality artistic images that are sometimes indistinguishable from the brush strokes of a painter, or the detail-oriented rendering of an illustrator.
In this post, we’ll take a whirlwind tour of the evolution of text-to-image AI, to get a sense of how far we’ve come over the last few years, from early GAN experiments to the latest diffusion models.
Before Diving In
To celebrate the 1 year anniversary of Stable Diffusion, we’ve updated our free text-to-image AI playground tool with the latest Stable Diffusion XL 1.0 model.
Zoo is an open source web app for comparing text-to-image generation models. Zoo lets you compare various image generation models side-by-side, so for example, you can visualize how Stable Diffusion and other text-to-image AI models have improved through time, by comparing the same prompt across multiple models at the same time. Zoo includes Stable Diffusion 1.5, Stable Diffusion 2.1, Stable Diffusion XL 1.0, Kandinski 2.2, DALL·E 2, Deepfloyd IF, and Material Diffusion.
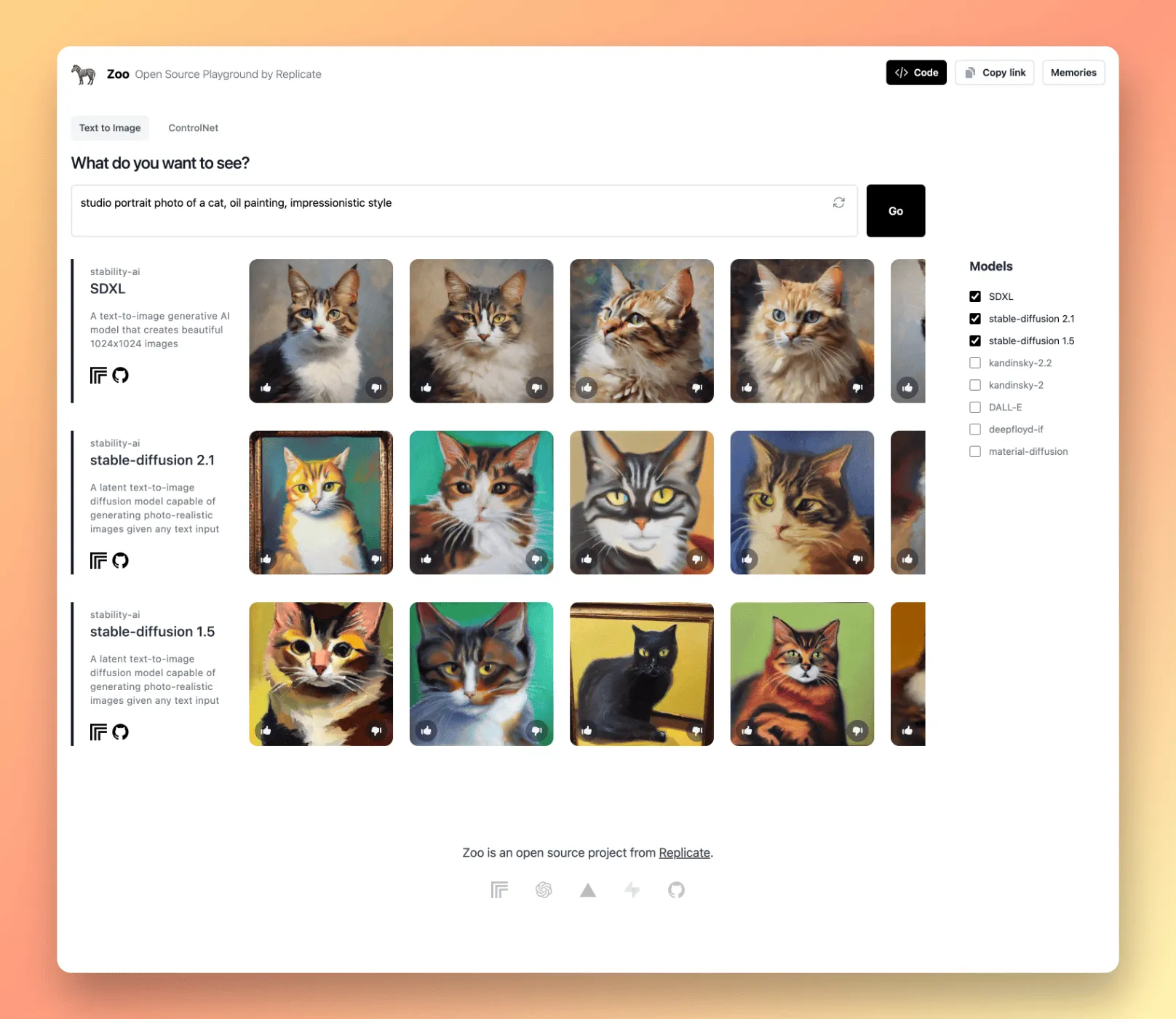
Replicate Zoo: text-to-image playground, where you can compare text-to-image AI models side-by-side.
Contents
Below is a list of the models we’ll be showing off in this post. You can click on any of the links below to jump to that section.
- CLIP + DALL·E
- Advadnoun’s DeepDaze
- Advadnoun’s The BigSleep
- VQGAN+CLIP
- Pixray
- DALL·E 2
- DALL·E Mini
- Stable Diffusion 1
- Stable Diffusion 2
- Stable Diffusion XL (SDXL)
- Fine-tuning
CLIP + DALL·E
The text-to-image generative AI scene as we know it started to take off back in January 2021, after OpenAI published their CLIP model.
CLIP is an open source model from OpenAI that’s trained on captioned images collected from the web, and it’s able to classify and project both images and text into the same embedding space. This means that it has a semantic understanding of what is happening in a given image. For example, if you feed CLIP a photo of a banana, it would be closely related to the text “yellow banana” in the embedding space.
This sort of multi-modal understanding of images and text is an important foundational element of text-to-image AI, because it can be used to nudge text-to-image AI generations to look like the given text prompt. For more details on how CLIP can be used as part of an image generation model, I suggest reading Jay Alammar’s excellent blog post: The Illustrated Stable Diffusion.
OpenAI also shared a paper detailing their approach for using CLIP to build a text-to-image model, named DALL·E.
While DALL·E was never fully open sourced, the paper and approach inspired a few open source implementations that would go on to shape the text-to-image AI scene as we know it.
Advadnoun’s DeepDaze
The first open source experiment of text-to-image AI was released by advadnoun in January 2021, just a few days after the DALL·E paper was released.
@advadnoun shared a colab notebook, eloquently named Deep Daze. It combined the use of OpenAI’s CLIP model, and the SIREN model to create imagery that was almost legible. You can see in the images below, the very beginnings of a resemblance to the prompt, but the images are all very abstract, never converging on realism or legible subjects.
Here are some of the first images generated with DeepDaze. My favorite is the poplars at sunset, which looks like it could almost be an abstract impressionistic painting.




Advadnoun’s The BigSleep
Then about one week later @advadnoun shared another colab notebook, named The BigSleep. This new notebook demonstrated the combination of the CLIP model and the BigGAN model.
The BigSleep represented a clear improvement toward creating legible scenes, but the images were still frequently difficult to comprehend; full of weird artifacts and error.
My favorite of these images is the A scene with vibrant colors — the clouds are realistic, and the vibrant colors look like fall foliage.



VQGAN+CLIP
In April 2021, @RiversHaveWings shared a series of colab notebooks which combined VQGAN and CLIP. A paper was published later, which included several interesting examples, and a full description of how they combined VQGAN with CLIP.
VQGAN+CLIP felt like a major step forward in terms of recreating an artistic look and feel. You’ll notice that the images below are starting to resemble their prompts, and artistic textures like brush strokes and pencil marks are beginning to appear. VQGAN+CLIP was used to create the first AI generated images that left me speechless.
👉🏼 Run VQGAN+CLIP on ReplicateHere are a few of my favorite VQGAN+CLIP images:


the Tower of Babel by J.M.W. Turner, VQGAN+CLIP, April 2021 - K Crowson, S Biderman et al.

A colored pencil drawing of a waterfall, VQGAN+CLIP, April 2021 - K Crowson, S Biderman et al.

Pixray
Pixray was an important image generation model in the history of Replicate. Originally released in June 2021, Pixray became the first text-to-image model on Replicate that reached tens of thousands of runs by early 2022. Today it’s been run a total of 1.3 million times.
Dribnet was the first Replicate user to formally request that we build an API as an alternative to the web-based prediction form. The rest is history! 😅
👉🏼 Run Pixray on Replicate



DALL·E 2
In April 2022, the entire scene started turning toward diffusion models.
OpenAI announced DALL·E 2 and published a new paper detailing their improvements and demonstrating how the use of diffusion models improved overall image quality and consistency. DALL·E 2 was released as a closed source product, initially only available to a small set of beta users.
Finally, the dream was coming true! You could prompt DALL·E 2 with something like a painting of a cat wearing a red hat, and it would give you an image of a cat wearing a red hat. 🤯

cat wearing a suit and tie, at the 24th st. bart station, DALL·E 2

cat wearing a red hat, DALL·E 2
DALL·E Mini
The next popular text-to-image AI model to drop was DALL·E Mini, in July 2021, an open source text-to-image model by Boris Dayma, et al.
Boris has published a wonderful deep-dive into how they were able to combine a variety of models, including VQGAN, CLIP, and Bert, to create legible images from text prompts.
👉🏼 Run DALL·E Mini on Replicate



Stable Diffusion 1
On August 22, 2022, Stable Diffusion 1.4 made its debut. The model weights, along with all of the code were released, open source.
I saw some examples scroll by on Hackernews, and was impressed by some of the results folks were sharing in the comments. When I decided to give it a try, I was very skeptical. The model weights were only 4GB on disk, how good could it be?
I somehow managed to get everything up and running on my gaming computer, with an NVIDIA RTX 2080 GPU with 8GB of VRAM. I was blown away. I was able to generate anything and everything I could think of, locally on my own computer 🤯. It took about 50 seconds to generate a single image, but I couldn’t believe it. I probably spent 4 hours generating silly images that night.
This was my very first Stable Diffusion generation, on August 30, 2022. It’s wild to think that it hasn’t even been a year yet.

Here are some other images I generated with Stable Diffusion 1.4 and 1.5. Looking back at these, I’m still impressed with the quality jump from from VQGAN and DALL·E Mini.
👉🏼 Run Stable Diffusion 1.5 on Replicate
a photograph of an astronaut riding a horse on mars, Stable Diffusion v1.4

A high tech solarpunk utopia in the Amazon rainforest, Stable Diffusion 1.4

an astronaut riding a horse on mars, hd, dramatic lighting, Stable Diffusion 1.5

colorful bird posing with extreme glowing rainbow colors, Stable Diffusion 1.5

A golden retriever dog sitting in the middle of sunny meadow, oil painting, Stable Diffusion 1.5

ancient space ship, ice fish shape, desert planet, cinematic, highly detailed, scifi, intricate digital painting, sunset, red glow, illustration, artstation, Stable Diffusion 1.5
Stable Diffusion 2
Stable Diffusion 2, first released in October 2022, was sort of like the awkward second album. Good, just… different.
Version 2 had several changes and improvements like negative prompts, OpenCLIP for a text encoder, larger image outputs, and more.
The migration to OpenClip caused significant changes to the image output and composition, when compared to prior versions of Stable Diffusion. To many, this felt like a “breaking change”. Most notably, this migration caused many artist’s names to be removed from the text encoder, which to this day drives a subset of users to use 1.5 over 2.1.
You could no longer use the prompt in the style of ARTIST_NAME_HERE, and get the specifically stylized results you used to get in Stable Diffusion v1.x.
I was a fan of Stable Diffusion 2. I thought the new OpenCLIP changes nudged me toward using more descriptive prompts, describing the details of the image I wanted to generate rather than copying entire styles.
👉🏼 Run Stable Diffusion 2.1 on ReplicateBelow are a few Stable Diffusion 2.1 images I generated.

flatirons, Chautauqua park, flatirons vista, green, boulder colorado, plein air oil painting, Stable Diffusion 2.1

Act as if you are the artist Picasso and you are emulating Vincent Van Gogh and his painting style, painting a portrait of a woman in blue…, Stable Diffusion 2.1

retro sci-fi 1950’s astronaut in-front of a futuristic glass city, reflection of a female shadow silhouette on glass helmet, under stars and moon, art deco, 1950’s, glowing highlights, teal palette, modern, Stable Diffusion 2.1

A mysterious dark wood, 4k, a lot of fern, a lot of fog, Stable Diffusion 2.1
Stable Diffusion XL (SDXL)
That brings us to the latest and greatest text-to-image AI model, Stable Diffusion XL, released on July 26, 2023.
SDXL delivers higher quality images, with fewer artifacts, and more consistent results. SDXL supports in-painting, image-to-image generation, refinement, ensemble of experts generation, fine-tuning, and more.
After playing with it for a few weeks, the results from the base model are stunningly good. Don’t take my word for it, try it out for yourself.
👉🏼 Run SDXL on ReplicateBelow are a few examples of SDXL images. I encourage you to right-click and open the image in a new tab, so you can see the full resolution. The minute detail is stunning.




These images are amazing, but it still feels like we’re only just getting started. At the current speed of development, the open source community is bound to deliver better models, tools, and workflows in the coming months and years. It’s an exciting time to get started in this space, as we’ve got a basic set of tools, and a solid foundation to build atop.
Looking forward, I think we’re going to see much more in the way of fine-tuning, compositional control, and creative enablement. These things each exist today for Stable diffusion, but I can only imagine they’re going to get better, faster, and easier to use.
Fine-tuning
Fine-tuning is the process of taking a pre-trained foundation model, like Stable Diffusion, and further training it on a specific dataset. In the context of a text-to-image AI model, this means you can train Stable Diffusion to generate images of your dog, your favorite anime character, or the style of your favorite artist. Some of today’s popular fine-tuning methods today are DreamBooth, LoRA, and Textual Inversion.
This is where open source models shine over private models like Midjourney or DALL·E 2; by allowing you to train on and generate subjects/objects from your everyday life.
Replicate recently released fine-tuning for SDXL. If you’re interested in trying to fine-tune your own SDXL model, I recommend reading our guide on how to fine-tune SDXL with your own images.
Here is a side-by-side comparison of fine-tuned models of my dog Queso. Each image is using the same prompt. The left is Stable Diffusion 2.1 Dreambooth, while the right is SDXL fine-tuned by following the directions in the blog post mentioned above.


Photo of my dog Queso, generated with a Dreambooth fine-tuned SDXL 1.0
To showcase some of the cool fine-tunes we’ve been seeing, we created a Fine-Tune Collection on Replicate. If you’re interested in adding your fine-tuned models to this collection, join us on discord to share your creations or @ us on twitter X, we would love to see what you’ve made!
Here are a few of my favorites:




Looking Ahead
With the release of SDXL, and the continued development of open source fine-tuning and compositional control (ControlNet) models, we’re getting close to the promised land of creative freedom and control, where you can generate anything you can imagine.
If you’re interested in starting to dabble in this space, I’d recommend getting started by playing with these free text-to-image AI tools we’ve built at Replicate.






Keep in touch
Follow us on Twitter X for more SDXL updates.
Join us in Discord to share your creations, and get help from the community.
Happy hacking! ✨
Bloopers
👋 Hello, friend! Congratulations on making it to the end of this post. To reward you, here are some additional “prompts gone wrong” bloopers that may make you chuckle.
While text-to-image AI has come a long way, it’s still far from perfect 😅
 salmon in the river, Stable Diffusion 2.1
salmon in the river, Stable Diffusion 2.1 salmon in the river, Stable Diffusion 2.1
salmon in the river, Stable Diffusion 2.1 illustration of a man, waving at the camera, pencil drawing, SDXL 1.0
illustration of a man, waving at the camera, pencil drawing, SDXL 1.0 illustration of a woman, waving at the camera, pencil drawing, SDXL 1.0
illustration of a woman, waving at the camera, pencil drawing, SDXL 1.0