Torch compile caching for inference speed
We now cache torch.compile artifacts to reduce boot times for models that use PyTorch.
Models like black-forest-labs/flux-kontext-dev, prunaai/flux-schnell, and prunaai/flux.1-dev-lora now start 2-3x faster.
We’ve published a guide to improving model performance with torch.compile that covers more of the details.
What is torch.compile?
Many models, particularly those in the FLUX family, apply various torch.compile technique/tricks to improve inference speed.
The first call to a compiled function traces and compiles the code, which adds overhead. Subsequent calls run the optimized code and are significantly faster.
In our tests of inference speed with black-forest-labs/flux-kontext-dev, the compiled version runs over 30% faster than the uncompiled one.
Performance improvements
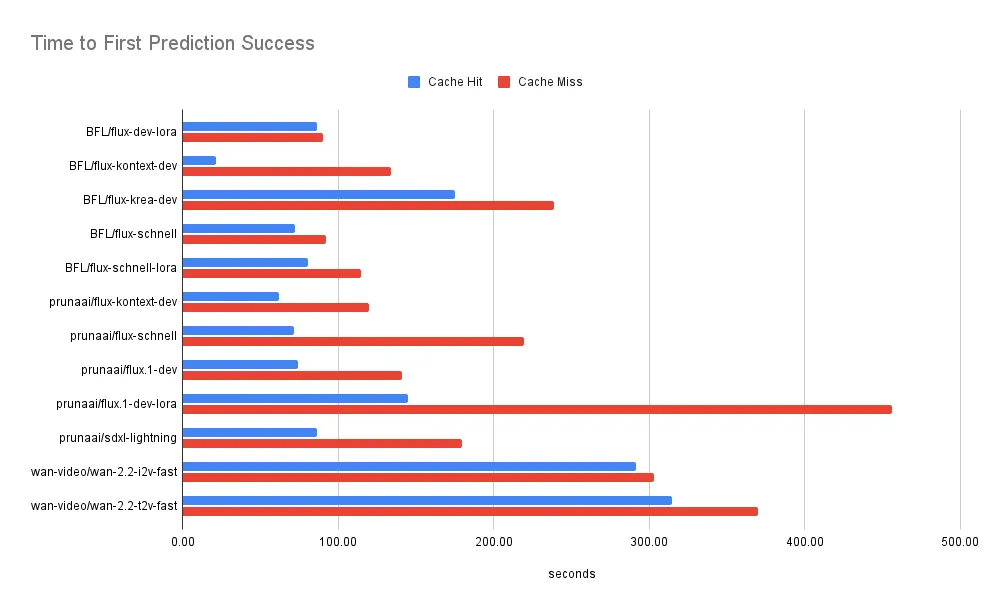
By caching the compiled artifacts across model container lifecycles, we’ve seen dramatic improvements in cold boot times:
- black-forest-labs/flux-kontext-dev: ~120s → ~60s (50% faster)
- prunaai/flux-schnell: ~150s → ~70s (53% faster)
- prunaai/flux.1-dev-lora: ~400s → ~150s (62% faster)
The cache also improves time from container startup to first prediction success across all models using torch.compile.
How it works
The caching system works like many CI/CD cache systems:
- When a model container starts, it looks for cached compiled artifacts
- If found, Torch reuses them instead of re-compiling from scratch
- When containers shut down gracefully, they update the cache if needed
- Cache files are keyed on model version and stored close to GPU nodes
Learn more
To learn more about how to use torch.compile, check out the our own
documentation and the
official PyTorch torch.compile tutorial.