

Readme
Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero-shot Cross-dataset Transfer
This repository contains code to compute depth from a single image. It accompanies our paper:
Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero-shot Cross-dataset Transfer
René Ranftl, Katrin Lasinger, David Hafner, Konrad Schindler, Vladlen Koltun
and our preprint:
Vision Transformers for Dense Prediction
René Ranftl, Alexey Bochkovskiy, Vladlen Koltun
MiDaS was trained on up to 12 datasets (ReDWeb, DIML, Movies, MegaDepth, WSVD, TartanAir, HRWSI, ApolloScape, BlendedMVS, IRS, KITTI, NYU Depth V2) with
multi-objective optimization.
The original model that was trained on 5 datasets (MIX 5 in the paper) can be found here.
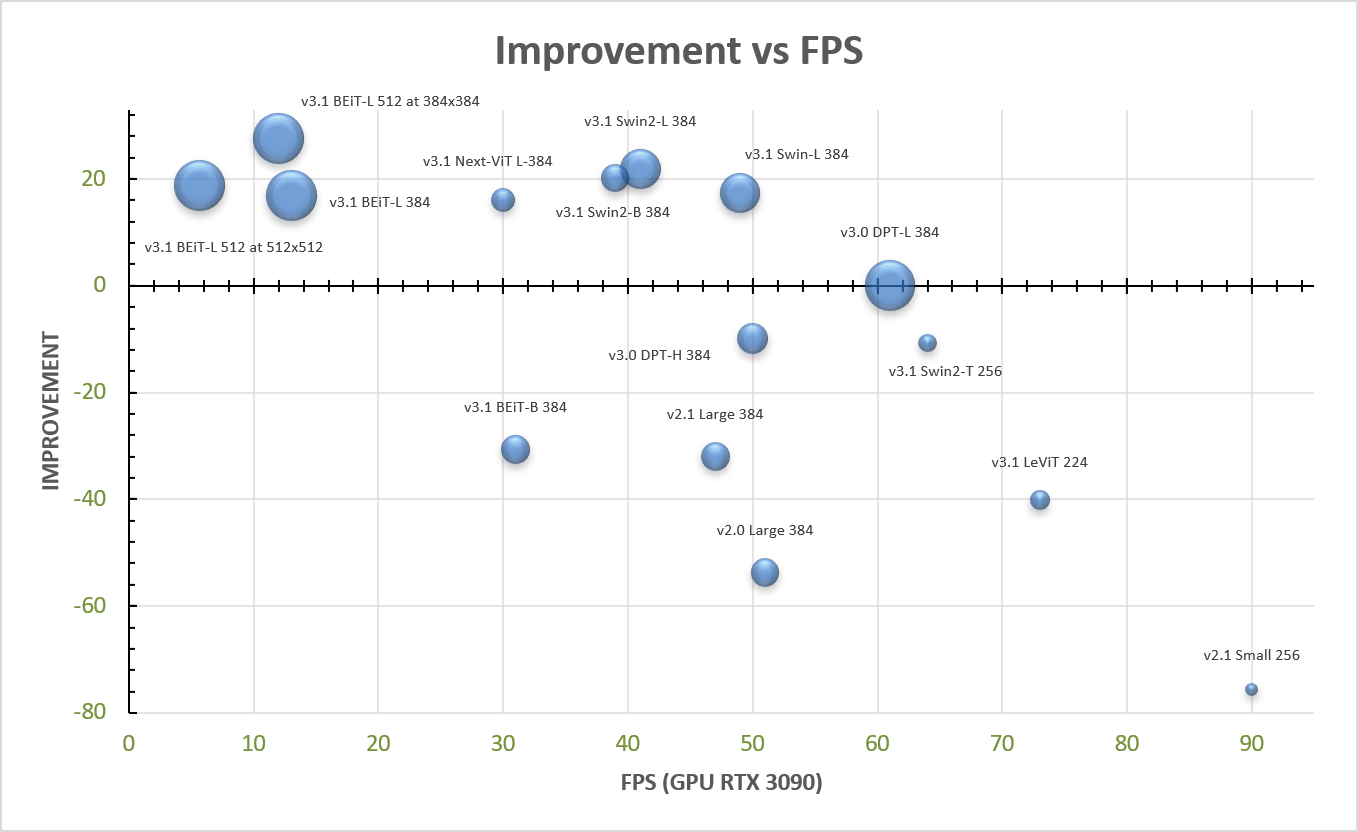
The figure below shows an overview of the different MiDaS models; the bubble size scales with number of parameters.
Citation
Please cite our paper if you use this code or any of the models:
@ARTICLE {Ranftl2022,
author = "Ren\'{e} Ranftl and Katrin Lasinger and David Hafner and Konrad Schindler and Vladlen Koltun",
title = "Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero-Shot Cross-Dataset Transfer",
journal = "IEEE Transactions on Pattern Analysis and Machine Intelligence",
year = "2022",
volume = "44",
number = "3"
}
If you use a DPT-based model, please also cite:
@article{Ranftl2021,
author = {Ren\'{e} Ranftl and Alexey Bochkovskiy and Vladlen Koltun},
title = {Vision Transformers for Dense Prediction},
journal = {ICCV},
year = {2021},
}
Acknowledgements
Our work builds on and uses code from timm and Next-ViT. We’d like to thank the authors for making these libraries available.
License
MIT License