
Readme
Cog implementation of collabora/WhisperSpeech
Note At this time, voice cloning only supports ogg files
About
An Open Source text-to-speech system built by inverting Whisper. Previously known as spear-tts-pytorch.
We want this model to be like Stable Diffusion but for speech – both powerful and easily customizable.
We are working only with properly licensed speech recordings and all the code is Open Source so the model will be always safe to use for commercial applications.
Currently the models are trained on the English LibreLight dataset. In the next release we want to target multiple languages (Whisper and EnCodec are both multilanguage).
If you have questions or you want to help you can find us in the #audio-generation channel on the LAION Discord server.
Architecture
The general architecture is similar to AudioLM, SPEAR TTS from Google and MusicGen from Meta. We avoided the NIH syndrome and built it on top of powerful Open Source models: Whisper from OpenAI to generate semantic tokens and perform transcription, EnCodec from Meta for acoustic modeling and Vocos from Charactr Inc as the high-quality vocoder.
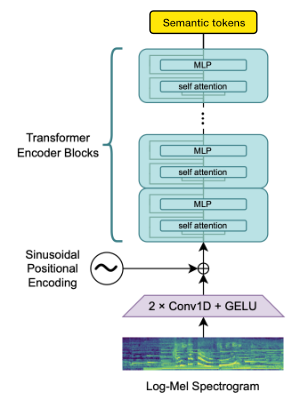
Whisper for modeling semantic tokens
We utilize the OpenAI Whisper encoder block to generate embeddings which we then quantize to get semantic tokens.
If the language is already supported by Whisper then this process requires only audio files (without ground truth transcriptions).
EnCodec for modeling acoustic tokens
We use EnCodec to model the audio waveform. Out of the box it delivers reasonable quality at 1.5kbps and we can bring this to high-quality by using Vocos – a vocoder pretrained on EnCodec tokens.

Appreciation
This work would not be possible without the generous sponsorships from:
Collabora – code development and model training
LAION – community building and datasets
Jülich Supercomputing Centre - JUWELS Booster supercomputer
We gratefully acknowledge the Gauss Centre for Supercomputing e.V. (www.gauss-centre.eu) for funding part of this work by providing computing time through the John von Neumann Institute for Computing (NIC) on the GCS Supercomputer JUWELS Booster at Jülich Supercomputing Centre (JSC), with access to compute provided via LAION cooperation on foundation models research.
We’d like to also thank individual contributors for their great help in building this model:
inevitable-2031 (qwerty_qwer on Discord) for dataset curation
Citations
@article{SpearTTS,
title = {Speak, Read and Prompt: High-Fidelity Text-to-Speech with Minimal Supervision},
url = {https://arxiv.org/abs/2302.03540},
author = {Kharitonov, Eugene and Vincent, Damien and Borsos, Zalán and Marinier, Raphaël and Girgin, Sertan and Pietquin, Olivier and Sharifi, Matt and Tagliasacchi, Marco and Zeghidour, Neil},
publisher = {arXiv},
year = {2023},
}
@article{MusicGen,
title={Simple and Controllable Music Generation},
url = {https://arxiv.org/abs/2306.05284},
author={Jade Copet and Felix Kreuk and Itai Gat and Tal Remez and David Kant and Gabriel Synnaeve and Yossi Adi and Alexandre Défossez},
publisher={arXiv},
year={2023},
}
@article{Whisper
title = {Robust Speech Recognition via Large-Scale Weak Supervision},
url = {https://arxiv.org/abs/2212.04356},
author = {Radford, Alec and Kim, Jong Wook and Xu, Tao and Brockman, Greg and McLeavey, Christine and Sutskever, Ilya},
publisher = {arXiv},
year = {2022},
}
@article{EnCodec
title = {High Fidelity Neural Audio Compression},
url = {https://arxiv.org/abs/2210.13438},
author = {Défossez, Alexandre and Copet, Jade and Synnaeve, Gabriel and Adi, Yossi},
publisher = {arXiv},
year = {2022},
}
@article{Vocos
title={Vocos: Closing the gap between time-domain and Fourier-based neural vocoders for high-quality audio synthesis},
url = {https://arxiv.org/abs/2306.00814},
author={Hubert Siuzdak},
publisher={arXiv},
year={2023},
}