lucataco / motif-video
Motif-Video-2B: a 2B-parameter text-to-video diffusion transformer

lucataco / glm-ocr
Compact 0.9B multimodal OCR model from Z.ai. State-of-the-art on OmniDocBench V1.5 (94.62, #1 overall). Four modes: text recognition, formula (LaTeX), table parsing, and JSON-schema information extraction. Fits on a single T4.

lucataco / sensenova-u1-8b-mot
SenseNova U1 8B MoT: unified multimodal model for native text-to-image generation

lucataco / gemma-4-31b-it
Gemma 4 31B Instruct - Google open-weight VLM (image + text in, text out)

lucataco / z-anime
Z-Anime is a fine-tune of Z-Image Base on anime aesthetics: natural-language prompts, full negative prompt support, and high-quality output across portraits, scenes, and characters.

lucataco / vibevoice-asr
Long-form speech recognition with speaker and timestamp segments using Microsoft's VibeVoice-ASR.

lucataco / privacy-filter
OpenAI Privacy Filter is a bidirectional token classifier for detecting and masking personally identifiable information (PII) in text
lucataco / sam3-video
A unified foundation model for prompt-based segmentation in images and videos

lucataco / next-scene
LoRA model by lovis93 that generate cinematic image sequences with natural visual progression from frame to frame for Qwen-Image-Edit-2509

lucataco / interactiveomni-8b
A unified omni-modal model that can simultaneously receive inputs such as images, audio, text, and video and directly generate coherent text and speech

lucataco / emu3.5-image
Native multimodal models are world learners

lucataco / gpt-oss-safeguard-120b
classify text content based on safety policies that you provide and perform a suite of foundational safety tasks
lucataco / longcat-video

lucataco / gpt-oss-safeguard-20b
classify text content based on safety policies that you provide and perform a suite of foundational safety tasks

lucataco / triblend
Simple tool to crop and merge three images together

lucataco / internvl3_5-30b
An advanced open-source multimodal large language model from the InternVL3.5 family, specializing in versatile vision-language tasks, and enhanced reasoning

lucataco / deepseek-ocr
Convert documents to markdown, extract raw text, and locate specific content

lucataco / qwen3-vl-8b-instruct
A powerful vision-language model in the Qwen series

lucataco / nemotron-nano-vl-8b-v1
a document intelligence vision language model (VLMs) that enables the ability to query and summarize images from the physical or virtual world
lucataco / featured-vid
Convert videos down to a web friendly size while maintaining video quality

lucataco / featured-img
Convert images down to a web friendly size while maintaining image quality

lucataco / consensus
Ask three LLMs the same question and find the consensus
lucataco / ugc-ad
AI workflow to create UGC ads with an image and a prompt

lucataco / neutts-air
super-realistic, TTS speech language model with instant voice cloning

lucataco / prompt-boost
a tool that enhances video prompts

lucataco / indextts-2
Emotionally Expressive and Duration-Controlled Text-to-Speech
lucataco / video-transition
Experimental short transition between two video clips using seedance-1-lite

lucataco / nano-banana-txt2img
Experimental wrapper of Nano Banana as a text2image model with aspect ratios
lucataco / wan-2.2-first-last-frame
Wan 2.2 First and Last Frame using 8-step inference w/ Lightning LoRA

lucataco / multi-image-qwen-edit
Experimental model with multiple image support for Qwen-Image-Edit

lucataco / video-caption
gpt-5 wrapper to caption a video

lucataco / qwen-davinci
Qwen-image fine-tuned on Drawings by Leonardo da Vinci
lucataco / stable-avatar
End-to-end video diffusion transformer, which synthesizes infinite-length high-quality audio-driven avatar videos without any post-processing

lucataco / audio-boost
Audio processing tool to help boost (or decrease) audio volume
lucataco / compare-img2vid-models
Forked from shridharathi/compare-video-models
lucataco / talking-avatar
A combination of Seedance, Kling Lipsync and Autocaption to create talking avatars

lucataco / minicpm-v-4
MiniCPM-V 4.0 has strong image and video understanding performance

lucataco / extract-audio
Simple tool to extract audio from a video file

lucataco / hunyuan-1.8b-instruct
Hunyuan is Tencent’s open-source efficient large language model series, designed for versatile deployment across diverse computational environments.

lucataco / image-caption
simple gpt-5-mini wrapper to caption an image
lucataco / wan-2.2-i2v-audio
Wan 2.2 A14B image-to-video with MMaudio

lucataco / seed-x-ppo
Seed-X-PPO-7B by ByteDance-Seed, a powerful series of open-source multilingual translation language models

lucataco / higgs-audio-v2
Higgs Audio v2, a powerful text-to-speech audio foundation model that excels in expressive audio generation
lucataco / ltx-video-0.9.8-distilled
Generate native long-form video, with controllability
lucataco / image-to-video-slideshow
Transform a collection of images into a video slideshow

lucataco / kontext-meta-cars
Change your car into a CDMX Meta Car

lucataco / kontext-realearth
This Kontext LoRA turns basic satellite images into quality drone shots

lucataco / qwen3-embedding-8b
The Qwen3 Embedding model series is specifically designed for text embedding and ranking tasks
lucataco / video-audio-merge
merge a video and an audio file
lucataco / veo-3-fast-vertical
Veo-3-fast wrapper to generate vertical shorts
lucataco / ltx-video-iclora
LTX Video 0.9.7 Distilled with ICLoRAs
lucataco / seedance-1-lite-audio
Seedance-1-lite with audio

lucataco / trim-video
Simple tool to quickly trim a video or audio file

lucataco / vid2webp
Convert your video into webp format (with looping)
lucataco / wan2.1-4step
Wan 2.1 I2V (14B) 480p with CausVid LoRA
lucataco / split-screen-video
Combines two videos into a single split-screen layout

lucataco / flux-content-filter
Flux Content Filter - Check for public figures and copyright concerns

lucataco / flux-kontext-dev
Open-weight version of FLUX.1 Kontext via Hugging Face Diffusers

lucataco / omnigen2
OmniGen2: a powerful and efficient unified multimodal model

lucataco / vectorized-dot-grid
Vectorized dot grid - by Brett from Designjoy

lucataco / flux-jennai
Jennai: an AI Avatar trained via the replicate/fast-flux-trainer

lucataco / flux-3d-emojis
This LoRA was trained with the replicate/fast-flux-trainer

lucataco / flux-game-assets
This LoRA was trained with the replicate/fast-flux-trainer

lucataco / ace-step
A Step Towards Music Generation Foundation Model text2music

lucataco / qwen2.5-omni-7b
Qwen2.5-Omni is an end-to-end multimodal model designed to perceive diverse modalities, including text, images, audio, and video, while simultaneously generating text and natural speech responses in a streaming manner.

lucataco / frame-extractor
Extract the first or last frame from any video file as a high-quality image

lucataco / orpheus-3b-0.1-ft
Orpheus 3B - high quality, emotive Text to Speech

lucataco / csm-1b
CSM (Conversational Speech Model) is a speech generation model from Sesame that generates RVQ audio codes from text and audio inputs

lucataco / wan2.1-i2v-lora
Wan2.1 14B 480p LoRA inference via Diffusers (Work in progress)

lucataco / magma-8b
Microsoft Magma: A Foundation Model for Multimodal AI Agents

lucataco / cogview4-6b
CogView-4 model, which has 6B parameters, supports native Chinese input, and Chinese text-to-image generation.

lucataco / qwq-32b
QwQ is the reasoning model of the Qwen series. Compared with conventional instruction-tuned models, QwQ, which is capable of thinking and reasoning

lucataco / wan-2.1-1.3b-vid2vid
Wan 2.1 1.3b Video to Video. Wan is a powerful visual generation model developed by Tongyi Lab of Alibaba Group

lucataco / olmocr-7b
A release preview of the olmOCR model from Ai2 that's fine tuned from Qwen2-VL-7B-Instruct using the olmOCR-mix-0225 dataset

lucataco / flux-in-context
In-Context LoRA with Image-to-Image and Inpainting to apply your logo to anything

lucataco / r1-1776-70b
A version of the DeepSeek-R1 model that has been post trained to provide unbiased, accurate, and factual information by Perplexity

lucataco / step-audio-tts-3b
Step-Audio-TTS-3B represents the industry's first Text-to-Speech (TTS) model trained on a large-scale synthetic dataset utilizing the LLM-Chat paradigm

lucataco / videollama3-7b
VideoLLaMA 3: Frontier Multimodal Foundation Models for Video Understanding

lucataco / dotted-video
Converts a video into a black and white dotted video effect

lucataco / dotted-waveform-visualizer
Create a dotted waveform video from an audio file

lucataco / deepseek-r1-70b
DeepSeek's first generation reasoning models with comparable performance to OpenAI-o1

lucataco / hunyuan-heygen-woman-2
HunyuanVideo finetune of an AI avatar from Heygen

lucataco / video-merge
Simple tool to merge together separate video snippets

lucataco / hunyuan-heygen-woman
HunyuanVideo finetune of an AI avatar from Heygen
lucataco / hunyuan-steamboat-willie
HunyuanVideo finetune of Walt Disney's: 1928 Steamboat Willie

lucataco / hunyuan-heygen-joshua
HunyuanVideo finetune of an AI Avatar from Heygen

lucataco / merge-img
Simple tool to merge a foreground and background image

lucataco / musubi-tuner-lora-converter
Convert musubi-tuner LoRA to ComfyUI compatible format

lucataco / musubi-tuner
Finetune HunyuanVideo LoRAs with kohya-ss/musibi-tuner

lucataco / hunyuanvideo-lora-trainer
Fine-tune HunyuanVideo via a-r-r-o-w/finetrainers (Work In Progress)

lucataco / hunyuanvideo-community-lora
LoRA Inference for hunyuanvideo-community/HunyuanVideo finetunes

lucataco / flux-rf-inversion
Cog implementation of Diffusers Flux RFInversion Pipeline

lucataco / hunyuanvideo
Unofficial community fork and Diffusers formatted weights of tencent/HunyuanVideo

lucataco / flux-dalgona
Flux finetune of Dalgona cookies

lucataco / qvq-72b-preview
QVQ-72B-Preview by Qwen is an experimental research model focusing on enhancing visual reasoning capabilities

lucataco / modernbert-large
ModernBERT-large is a modernized bidirectional encoder-only Transformer model (BERT-style) pre-trained on 2 trillion tokens of English and code data

lucataco / modernbert-base
ModernBERT-base is a modernized bidirectional encoder-only Transformer model (BERT-style) pre-trained on 2 trillion tokens of English and code data

lucataco / qwen2-vl-7b-instruct
Latest model in the Qwen family for chatting with video and image models

lucataco / ollama-llama3.2-vision-90b
Ollama Llama 3.2 Vision 90B

lucataco / ollama-llama3.2-vision-11b
Ollama Llama 3.2 Vision 11B

lucataco / ollama-qwq
Ollama QwQ 32B

lucataco / apollo-7b
Apollo 7B - An Exploration of Video Understanding in Large Multimodal Models

lucataco / apollo-3b
Apollo 3B - An Exploration of Video Understanding in Large Multimodal Models

lucataco / ollama-llama3.3-70b
Ollama Llama 3.3 70B

lucataco / bulk-video-caption
Video Preprocessing tool for captioning multiple videos using GPT, Claude or Gemini

lucataco / moondream-0.5b
Moondream 0.5B, the world's smallest vision language model

lucataco / video-split
Simple tool to split apart a video into snippets
lucataco / smolvlm-instruct
SmolVLM-Instruct by HuggingFaceTB

lucataco / sd3.5-large-fine-tuner
Ostris AI-Toolkit for StableDiffusion3.5-Large LoRA Training

lucataco / stable-diffusion-3.5-large-lora-trainer
Fine-tune StableDiffusion3.5-Large with Hugging Face Diffusers

lucataco / stable-diffusion-3.5-large-lora
Stable Diffusion 3.5 Large - LoRA Explorer

lucataco / cogvideox-interpolation
CogvideoX Keyframe Interpolation by Zhengcong Fei

lucataco / ollama-nemotron-70b
Ollama Nemotron 70b

lucataco / flux.1-turbo-alpha
8-step distilled lora for FLUX.1-dev model released by the Alimama-Creative Team

lucataco / diffusers-dreambooth-lora-x2
FLUX.1-Dev LoRA Training (with 2x GPUs) by Huggingface Diffusers

lucataco / flux-rplctcpl
Flux LoRA Training Experiment - Training two people in one LoRA with two images

lucataco / flux-vlta-layer
Flux finetune of Violeta - specific layer training

lucataco / flux.1-controlnet-lineart-promeai
Controlnet trained on black-forest-labs/FLUX.1-dev with lineart condition

lucataco / ollama-qwen2.5-72b
Ollama Qwen2.5 72b

lucataco / joy-caption-pre-alpha
Image Caption model

lucataco / nsfw_video_detection
FalconAIs NSFW detection model, extended for videos

lucataco / flux-time100
Flux finetune of the style: TIMES 100 Most Influential People in AI

lucataco / ollama-reflection-70b
Ollama Reflection 70b

lucataco / flux-vlta
A Flux finetune of an AI character named: Violeta

lucataco / controlnet-union-pro
ControlNet for FLUX.1-dev model jointly released by InstantX and Shakker Labs

lucataco / flux-syd-mead
Flux finetune trained on Syd Mead concept art for Blade Runner

lucataco / diffusers-dreambooth-lora
FLUX.1-Dev LoRA Training by Huggingface Diffusers

lucataco / flux-dev-multi-lora
FLUX.1-Dev Multi LoRA Explorer

lucataco / flux-watercolor
A Flux LoRA trained on watercolor style photos

lucataco / flux-queso
A Flux LoRA trained on photos of Jake's dog: Queso

lucataco / flux-schnell-lora
FLUX.1-Schnell LoRA Explorer

lucataco / ai-toolkit
Ostris AI-Toolkit for Flux LoRA Training (DEPRECATED. Please use: ostris/flux-dev-lora-trainer)

lucataco / flux-dev-lora
FLUX.1-Dev LoRA Explorer (DEPRECATED Please use: black-forest-labs/flux-dev-lora)

lucataco / flux-dev
Flux Dev diffusers implementation

lucataco / simpletuner-flux
FLUX.1-Dev LoRA trainer via SimpleTuner (Work in Progress)

lucataco / dis-background-removal
ECCV2022 Quick background removal

lucataco / segment-anything-2
Segment Anything 2 (SAM2) by Meta - Automatic mask generation
lucataco / train-text-to-image-lora
Huggingface Diffusers: SDv1.4/1.5/2.0/2.1 finetuner

lucataco / aura-flow-v0.2
A fully open-sourced, large flow-based text-to-image generation model

lucataco / prompt-guard-86m
LLM-powered applications are susceptible to prompt attacks, which are prompts intentionally designed to subvert the developer’s intended behavior of the LLM

lucataco / pixart-sigma-900m
PixArt Sigma 900M is a text-to-image generation model based on the PixArt Sigma architecture

lucataco / numinamath-7b-tir
NuminaMath is a series of language models that are trained to solve math problems using tool-integrated reasoning (TIR)

lucataco / ollama-llama3-70b
Cog wrapper for Ollama llama3:70b

lucataco / ollama-llama3-8b
Cog wrapper for Ollama llama3:8b
lucataco / internlm2_5-7b-chat
InternLM2.5 has open-sourced a 7 billion parameter base model and a chat model tailored for practical scenarios.

lucataco / qwen2-57b-a14b-instruct
Qwen2 57 billion parameter language model from Alibaba Cloud, fine tuned for chat completions

lucataco / dolphin-2.9-llama3-8b
Dolphin-2.9 has a variety of instruction, conversational, and coding skills. It also has initial agentic abilities and supports function calling

lucataco / hermes-2-theta-llama-3-8b
Hermes-2 Θ (Theta) is the first experimental merged model released by Nous Research

lucataco / hermes-2-pro-llama-3-70b
Hermes 2 Pro is an updated and cleaned version of the OpenHermes 2.5 Dataset, as well as a newly introduced Function Calling and JSON Mode dataset developed in-house

lucataco / florence-2-large
Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks

lucataco / florence-2-base
Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks

lucataco / mobius
Mobius, a diffusion model that pushes the boundaries of domain-agnostic debiasing and representation realignment

lucataco / paligemma-3b-pt-224
PaliGemma 3B, an open VLM by Google, pre-trained with 224*224 input images and 128 token input/output text sequences
lucataco / yi-1.5-6b
Yi-1.5 is continuously pre-trained on Yi with a high-quality corpus of 500B tokens and fine-tuned on 3M diverse fine-tuning samples

lucataco / blip3-phi3-mini-instruct-r-v1
BLIP3(XGen-MM) is a series of foundational Large Multimodal Models (LMMs) developed by Salesforce AI Research

lucataco / hermes-2-pro-llama-3-8b
Hermes 2 Pro is an updated and cleaned version of the OpenHermes 2.5 Dataset, as well as a newly introduced Function Calling and JSON Mode dataset developed in-house

lucataco / llama-3-vision-alpha
Projection module trained to add vision capabilties to Llama 3 using SigLIP

lucataco / qwen1.5-110b
Qwen1.5 is the beta version of Qwen2, a transformer-based decoder-only language model pretrained on a large amount of data

lucataco / idefics-8b
Idefics2 is an open multimodal model that accepts arbitrary sequences of image and text inputs and produces text outputs

lucataco / snowflake-arctic-embed-l
snowflake-arctic-embed is a suite of text embedding models that focuses on creating high-quality retrieval models optimized for performance

lucataco / sdxs-512-0.9
sdxs-512-0.9 can generate high-resolution images in real-time based on prompt texts, trained using score distillation and feature matching
lucataco / mvsep-mdx23-music-separation
Model for Sound demixing challenge 2023: Music Demixing Track - MDX'23

lucataco / rembg-video
Video Background Removal

lucataco / clip-vit-base-patch32
openai/clip-vit-large-patch32

lucataco / moondream2
moondream2 is a small vision language model designed to run efficiently on edge devices

lucataco / zeta-editing
Zero-Shot Text-Based Audio Editing Using DDPM Inversion

lucataco / sdxl-lightning-multi-controlnet
SDXL lightning mult-controlnet, img2img & inpainting

lucataco / dreamshaper-xl-lightning
dreamshaper-xl-lightning is a Stable Diffusion model that has been fine-tuned on SDXL

lucataco / animate-diff-vid2vid
AnimateDiff video to video

lucataco / depth-anything-video-sbs
POC implementation of Depth-anything to produce a 3D SBS video

lucataco / rgb2grayscale-cuda
CUDA implementation of an rgb2grayscale function

lucataco / deep3d
Deep3D: Real-Time end-to-end 2D-to-3D Video Conversion, based on deep learning

lucataco / glpn-nyu
Global-Local Path Networks (GLPN) model trained on NYUv2 for Monocular Depth Estimation

lucataco / nomic-embed-text-v1
nomic-embed-text-v1 is 8192 context length text encoder that surpasses OpenAI text-embedding-ada-002 and text-embedding-3-small performance on short and long context tasks

lucataco / depth-anything-video
Depth Anything on full video files

lucataco / phixtral-2x2_8
phixtral-2x2_8 is the first Mixure of Experts (MoE) made with two microsoft/phi-2 models, inspired by the mistralai/Mixtral-8x7B-v0.1 architecture

lucataco / bge-m3
BGE-M3, the first embedding model which supports multiple retrieval mode, multilingual and multi-granularity retrieval.

lucataco / qwen1.5-72b
Qwen1.5 is the beta version of Qwen2, a transformer-based decoder-only language model pretrained on a large amount of data

lucataco / qwen1.5-7b
Qwen1.5 is the beta version of Qwen2, a transformer-based decoder-only language model pretrained on a large amount of data

lucataco / qwen1.5-4b
Qwen1.5 is the beta version of Qwen2, a transformer-based decoder-only language model pretrained on a large amount of data

lucataco / qwen1.5-1.8b
Qwen1.5 is the beta version of Qwen2, a transformer-based decoder-only language model pretrained on a large amount of data

lucataco / qwen1.5-0.5b
Qwen1.5 is the beta version of Qwen2, a transformer-based decoder-only language model pretrained on a large amount of data

lucataco / diffusionlight
DiffusionLight: Light Probes by Painting a Chrome Ball

lucataco / img-and-audio2video
Take an image and an audio file and create a video clip

lucataco / watermark_detector
amrul-hzz's fine-tuned version of vit-base-patch16-224-in21k for watermark image detection

lucataco / moondream1
(Research only) Moondream1 is a vision language model that performs on par with models twice its size

lucataco / siglip
SigLIP proposes to replace the loss function used in CLIP by a simple pairwise sigmoid loss

lucataco / wizardcoder-33b-v1.1-gguf
WizardCoder: Empowering Code Large Language Models with Evol-Instruct

lucataco / whisperspeech-small
An Open Source text-to-speech system built by inverting Whisper

lucataco / magnet
MAGNeT: Masked Audio Generation using a Single Non-Autoregressive Transformer

lucataco / pheme
Pheme generates a variety of conversational voices in 16 kHz for phone-call applications

lucataco / pasd-magnify
(Academic and Non-commercial use only) Pixel-Aware Stable Diffusion for Realistic Image Super-resolution and Personalized Stylization

lucataco / sdxl-deepcache
SDXL using DeepCache

lucataco / tinyllama-1.1b-chat-v1.0
This is the chat model finetuned on top of TinyLlama/TinyLlama-1.1B-intermediate-step-1431k-3T

lucataco / open-dalle-v1.1
A unique fusion that showcases exceptional prompt adherence and semantic understanding, it seems to be a step above base SDXL and a step closer to DALLE-3 in terms of prompt comprehension

lucataco / diffusion-motion-transfer
Space-Time Diffusion Features for Zero-Shot Text-Driven Motion Transfer

lucataco / singing_voice_conversion
Amphion Singing Voice Conversion: DiffWaveNetSVC

lucataco / ip-adapter-faceid
(Research only) IP-Adapter-FaceID can generate various style images conditioned on a face with only text prompts

lucataco / dreamshaper-xl-turbo
DreamShaper is a general purpose SD model that aims at doing everything well, photos, art, anime, manga. It's designed to match Midjourney and DALL-E.

lucataco / dpo-sdxl
Direct Preference Optimization (DPO) is a method to align diffusion models to text human preferences by directly optimizing on human comparison data

lucataco / seamless_communication
FacebookResearch/SeamlessM4T v2 - Massively Multilingual & Multimodal Machine Translation

lucataco / stable-diffusion-x4-upscaler
Stable Diffusion x4 upscaler model

lucataco / phi-2
Phi-2 by Microsoft

lucataco / segmind-vega
Segmind-Vega Model is a distilled version of SDXL, offering a 70% reduction in size and an 100% speedup

lucataco / demofusion-enhance
Image to Image enhancer using DemoFusion
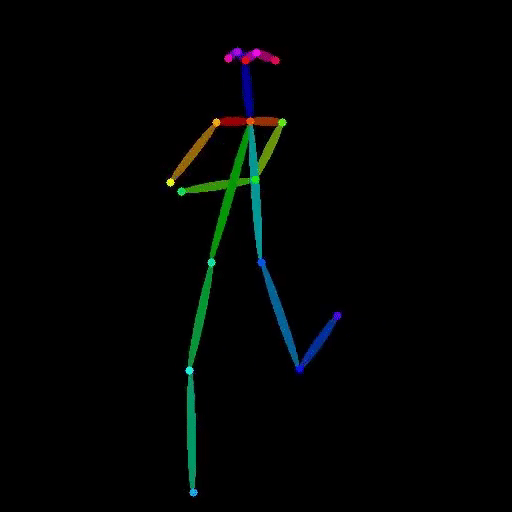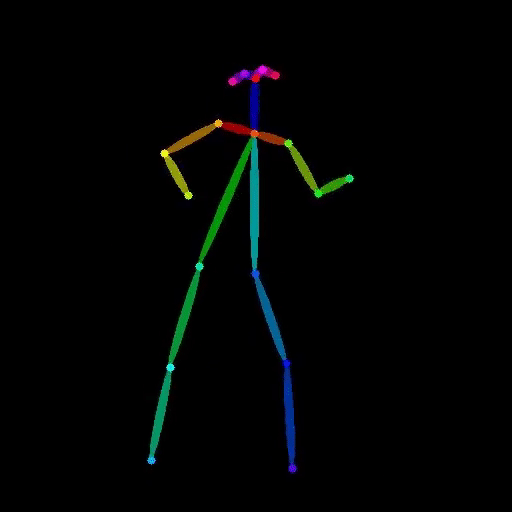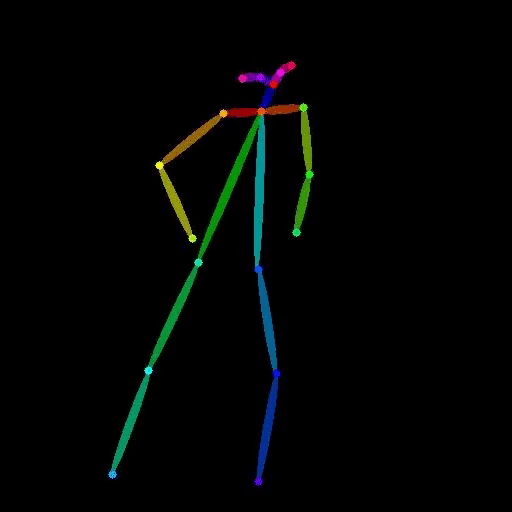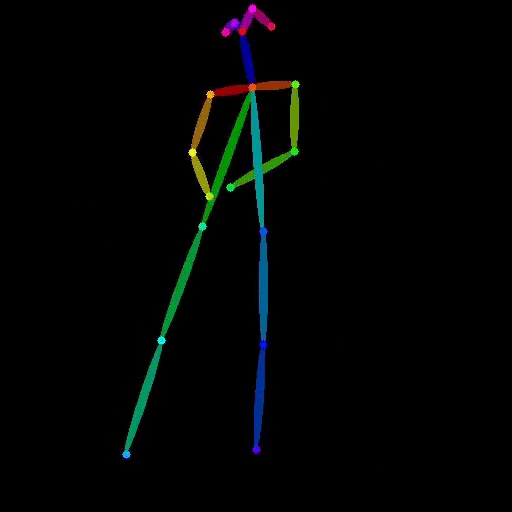
lucataco / vid2openpose
Video to OpenPose

lucataco / magic-animate-openpose
MagicAnimate using an OpenPose input video

lucataco / vid2densepose
Convert your videos to DensePose and use it with MagicAnimate

lucataco / style-aligned
GoogleAI: Style Aligned Image Generation via Shared Attention

lucataco / magic-animate
MagicAnimate: Temporally Consistent Human Image Animation using Diffusion Model

lucataco / pixart-xl-2
PixArt-Alpha 1024px is a transformer-based text-to-image diffusion system trained on text embeddings from T5

lucataco / demofusion
DemoFusion: Democratising High-Resolution Image Generation With No 💰

lucataco / sdxl-img-blend
SDXL Image Blending

lucataco / interpany-clearer
InterpAny-Clearer: Clearer anytime frame interpolation & Manipulated interpolation

lucataco / controlnet-tile
Controlnet v1.1 - Tile Version

lucataco / real-esrgan-video
Real-ESRGAN Video Upscaler

lucataco / seine
Image-to-video - SEINE: Short-to-Long Video Diffusion Model for Generative Transition and Prediction

lucataco / animate-diff-sdxl-lcm
Animate Your Personalized Text-to-Image Diffusion Models with SDXL and LCM

lucataco / dreamshaper7-img2img-lcm
Dreamshaper-7 img2img with LCM LoRA for faster inference

lucataco / vseq2vseq
Text to video diffusion model with variable length frame conditioning for infinite length video

lucataco / realvisxl2-lcm
RealvisXL-v2.0 with LCM LoRA - requires fewer steps (4 to 8 instead of the original 40 to 50)

lucataco / modelscope-facefusion
Auto fuse a user's face onto the template image, with a similar appearance to the user

lucataco / ip_adapter-face-inpaint
A combination of ip_adapter SDv1.5 and mediapipe-face to inpaint a face

lucataco / sdxl-niji-se
SDXL_Niji_Special Edition

lucataco / sdxl-lcm-zeke
A fine-tuned SDXL-LCM LoRA based on the photos of Zeke

lucataco / sdxl-lcm
Latent Consistency Model (LCM): SDXL, distills the original model into a version that requires fewer steps (4 to 8 instead of the original 25 to 50)

lucataco / sdxl-lcm-loras
POC of SDXL-LCM LoRA combined with a Replicate LoRA for 4 second inference time

lucataco / xtts-v2
Coqui XTTS-v2: Multilingual Text To Speech Voice Cloning

lucataco / lcm-ssd-1b
Latent Consistency Model (LCM): SSD-1B, is a LCM distilled version that reduces the number of inference steps needed to only 2 - 8 steps

lucataco / ip_adapter-sdxl-face
The image prompt adapter is designed to enable a pretrained text-to-image diffusion model to generate SDXL images with an image prompt

lucataco / ip_adapter-face
The image prompt adapter is designed to enable a pretrained text-to-image diffusion model to generate SDv1.5 images with an image prompt

lucataco / realvisxl2-lora-inference
POC to run inference on Realvisxl2 LoRAs

lucataco / realvisxl2-lora-training
POC to train Realvisxl2 LoRAs

lucataco / ssd-1b-txt2img_batch
Batch mode for Segmind Stable Diffusion Model (SSD-1B) txt2img

lucataco / realvisxl-v2-img2img
Implementation of SDXL RealVisXL_V2.0 img2img

lucataco / thinkdiffusionxl
ThinkDiffusionXL is a go-to model capable of amazing photorealism that's also versatile enough to generate high-quality images across a variety of styles and subjects without needing to be a prompting genius

lucataco / ssd-lora-training
POC to train SSD-1B LoRAs for cheaper & faster training

lucataco / ssd-lora-inference
POC to run inference on SSD-1B LoRAs

lucataco / ssd-1b-img2img
Segmind Stable Diffusion Model (SSD-1B) img2img
lucataco / kosmos-2
Grounding Multimodal Large Language Models to the World

lucataco / realvisxl-v1-img2img
Implementation of SDXL RealVisXL_V1.0 img2img

lucataco / realvisxl-v2.0
Implementation of SDXL RealVisXL_V2.0

lucataco / dolphin-2.2.1-mistral-7b
Mistral-7B-v0.1 fine tuned for chat with the Dolphin dataset (an open-source implementation of Microsoft's Orca)

lucataco / dolphin-2.1-mistral-7b
Mistral-7B-v0.1 fine tuned for chat with the Dolphin dataset (an open-source implementation of Microsoft's Orca)

lucataco / mistrallite
MistralLiteA is a fine-tuned Mistral-7B-v0.1 language model, with enhanced capabilities of processing long context (up to 32K tokens)

lucataco / ssd-1b
Segmind Stable Diffusion Model (SSD-1B) is a distilled 50% smaller version of SDXL, offering a 60% speedup while maintaining high-quality text-to-image generation capabilities
lucataco / bakllava
BakLLaVA-1 is a Mistral 7B base augmented with the LLaVA 1.5 architecture

lucataco / fuyu-8b
Fuyu-8B is a multi-modal text and image transformer trained by Adept AI

lucataco / video-crafter
Open diffusion model for high-quality video generation

lucataco / sdxl-inpainting
SDXL Inpainting by the HF Diffusers team

lucataco / comfyui-sdxl-txt2img
Using a ComfyUI workflow to run SDXL text2img

lucataco / sadtalker
Stylized Audio-Driven Single Image Talking Face Animation

lucataco / hotshot-xl
😊 Hotshot-XL is an AI text-to-GIF model trained to work alongside Stable Diffusion XL

lucataco / illusion-diffusion-hq
Monster Labs QrCode ControlNet on top of SD Realistic Vision v5.1

lucataco / remove-bg
Remove background from an image

lucataco / realvisxl-v1.0
Implementation of SDXL RealVisXL_V1.0

lucataco / sdxl-panoramic
360 Panorama SDXL image with inpainted wrapping seam
lucataco / codeformer
Robust face restoration algorithm for old photos/AI-generated faces
lucataco / blueprint
An SDXL fine-tune based on blueprints

lucataco / qwen-vl-chat
A multimodal LLM-based AI assistant, which is trained with alignment techniques. Qwen-VL-Chat supports more flexible interaction, such as multi-round question answering, and creative capabilities.

lucataco / ms-img2vid
Turn any image into a video

lucataco / wizardcoder-python-34b-v1.0
Empowering Code Large Language Models with Evol-Instruct

lucataco / idefics-9b
IDEFICS 9b Quantized

lucataco / realistic-vision-v5-openpose
Realistic Vision V5 with OpenPose

lucataco / spider-gwen-style
SDXL fine tune on Spider-Gwen style

lucataco / realistic-vision-v5
Realistic Vision v5.0 with VAE

lucataco / sdxl-controlnet-openpose
SDXL ControlNet - OpenPose

lucataco / realistic-vision-v5-inpainting
Realistic Vision v5.0 Inpainting

lucataco / realistic-vision-v5-img2img
Realistic Vision v5.0 Image 2 Image

lucataco / sdxl-clip-interrogator
CLIP Interrogator for SDXL optimizes text prompts to match a given image

lucataco / sdxl-controlnet-depth
SDXL ControlNet - Depth

lucataco / sdxl-controlnet
SDXL ControlNet - Canny

lucataco / upstage-llama-2-70b-instruct-v2
Upstage/Llama-2-70B-instruct-v2 - GPTQ

lucataco / glaive-function-calling-v1
2.7B param open source chat model trained on Glaive’s synthetic data generation platform

lucataco / sdxl
SDXL v1.0 - A text-to-image generative AI model that creates beautiful images

lucataco / gfpgan
Practical face restoration algorithm for *old photos* or *AI-generated faces* (for larger images)

lucataco / realistic-vision-v5.1
Implementation of Realistic Vision v5.1 with VAE

lucataco / freewilly2
Stability AI's FreeWilly2

lucataco / llama-2-13b-chat
Meta's Llama 2 13b Chat - GPTQ

lucataco / llama-2-7b-chat
Meta's Llama 2 7b Chat - GPTQ
lucataco / speaker-diarization
Segments an audio recording based on who is speaking (on A100)
lucataco / animate-diff
Animate Your Personalized Text-to-Image Diffusion Models

lucataco / real-esrgan
Real-ESRGAN with optional face correction and adjustable upscale (for larger images)

lucataco / rivers-stable-diffusion-upscaler
RiversHaveWings Stable Diffusion Upscaler
lucataco / wsrglow
A working wsrglow model

lucataco / clip-interrogator
CLIP Interrogator (for faster inference)

lucataco / realistic-vision-v4.0
Realistic Vision V4.0

lucataco / realistic-vision-v3.0
Realistic Vision V3.0 with VAE

lucataco / instruct-glaive
sahil2801/replit-code-instruct-glaive

lucataco / sandbox
SANDBOX Environment

lucataco / xgen-7b-8k-base
Salesforce/xgen-7b-8k-base

lucataco / codegen2-1b
Salesforce/codegen2-1B

lucataco / vicuna-7b-v1.3
lmsys/vicuna-7b-v1.3

lucataco / vicuna-13b-v1.3
lmsys/vicuna-13b-v1.3

lucataco / tiny-starcoder-py
bigcode/tiny_starcoder_py

lucataco / shiba-diffusion
Shiba stable diffusion model