









Readme
This is an implementation of PixArt-alpha/PixArt-XL-2-1024-MS.
About
Pixart-α consists of pure transformer blocks for latent diffusion: It can directly generate 1024px images from text prompts within a single sampling process.
Source code is available at https://github.com/PixArt-alpha/PixArt-alpha.
Model Description
- Developed by: Pixart-α
- Model type: Diffusion-Transformer-based text-to-image generative model
- License: CreativeML Open RAIL++-M License
- Model Description: This is a model that can be used to generate and modify images based on text prompts. It is a Transformer Latent Diffusion Model that uses one fixed, pretrained text encoders (T5)) and one latent feature encoder (VAE).
- Resources for more information: Check out our GitHub Repository and the Pixart-α report on arXiv.
Model Sources
For research purposes, we recommend our generative-models Github repository (https://github.com/PixArt-alpha/PixArt-alpha), which is more suitable for both training and inference and for which most advanced diffusion sampler like SA-Solver will be added over time. Hugging Face provides free Pixart-α inference.
Repository: https://github.com/PixArt-alpha/PixArt-alpha
Demo: https://huggingface.co/spaces/PixArt-alpha/PixArt-alpha
Training Efficiency
PixArt-α only takes 10.8% of Stable Diffusion v1.5’s training time (675 vs. 6,250 A100 GPU days), saving nearly $300,000 ($26,000 vs. $320,000) and reducing 90% CO2 emissions. Moreover, compared with a larger SOTA model, RAPHAEL, our training cost is merely 1%.

Evaluation
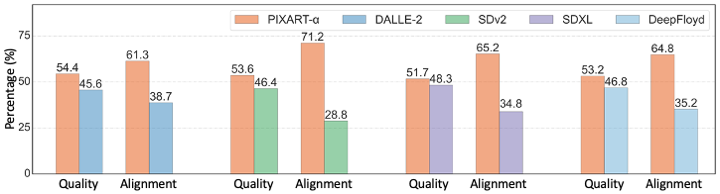
The chart above evaluates user preference for Pixart-α over SDXL 0.9, Stable Diffusion 2, DALLE-2 and DeepFloyd. The Pixart-α base model performs comparable or even better than the existing state-of-the-art models.