
Readme
Whisper
Whisper is a general-purpose speech recognition model. It is trained on a large dataset of diverse audio and is also a multi-task model that can perform multilingual speech recognition as well as speech translation and language identification.
Approach
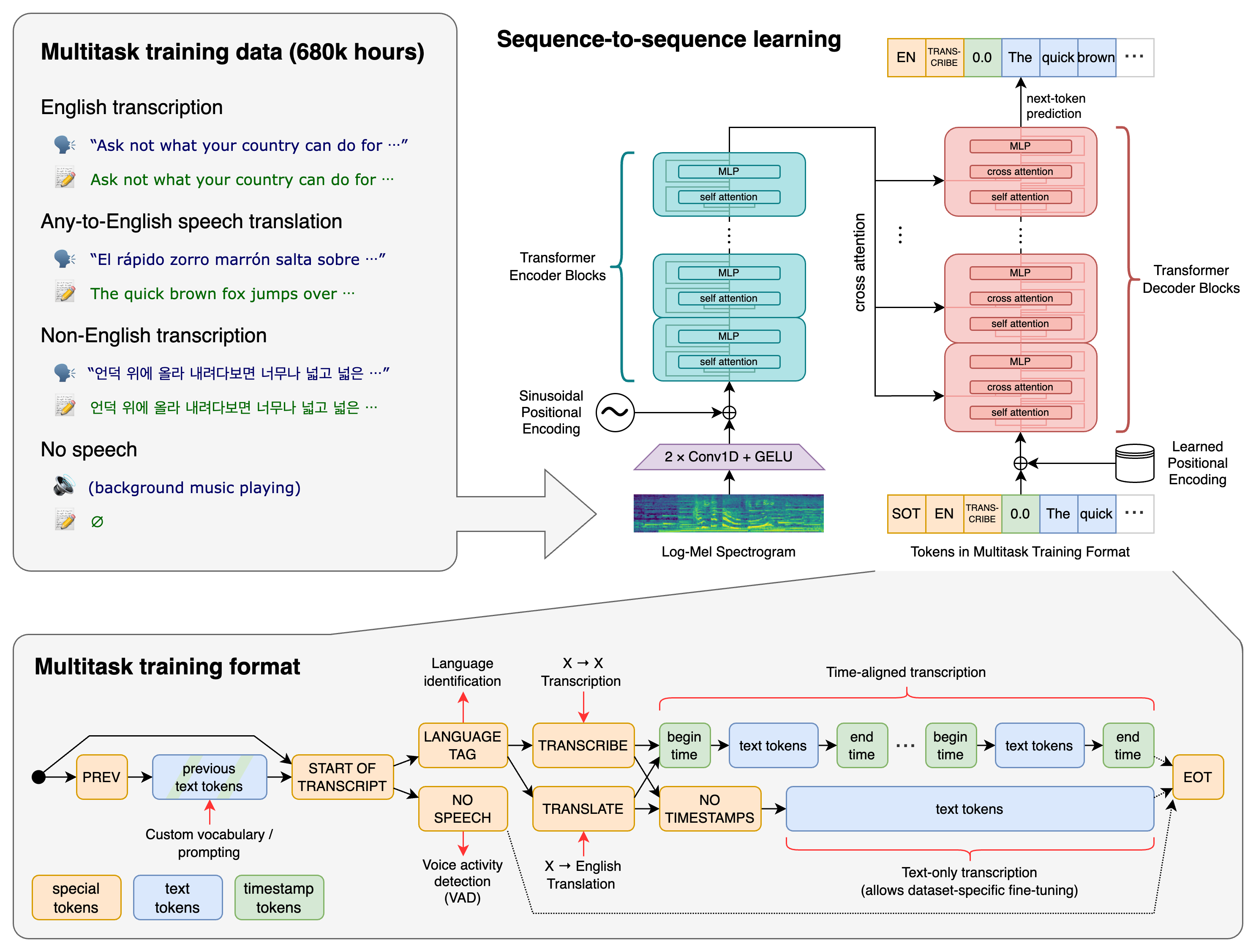
A Transformer sequence-to-sequence model is trained on various speech processing tasks, including multilingual speech recognition, speech translation, spoken language identification, and voice activity detection. All of these tasks are jointly represented as a sequence of tokens to be predicted by the decoder, allowing for a single model to replace many different stages of a traditional speech processing pipeline. The multitask training format uses a set of special tokens that serve as task specifiers or classification targets.
Setup
We used Python 3.9.9 and PyTorch 1.10.1 to train and test our models, but the codebase is expected to be compatible with Python 3.7 or later and recent PyTorch versions. The codebase also depends on a few Python packages, most notably HuggingFace Transformers for their fast tokenizer implementation and ffmpeg-python for reading audio files. It also requires the command-line tool ffmpeg.
Available models and languages
There are five model sizes, four with English-only versions, offering speed and accuracy tradeoffs. Below are the names of the available models and their approximate memory requirements and relative speed.
| Size | Parameters | English-only model | Multilingual model | Required VRAM | Relative speed |
|---|---|---|---|---|---|
| tiny | 39 M | tiny.en |
tiny |
~1 GB | ~32x |
| base | 74 M | base.en |
base |
~1 GB | ~16x |
| small | 244 M | small.en |
small |
~2 GB | ~6x |
| medium | 769 M | medium.en |
medium |
~5 GB | ~2x |
| large | 1550 M | N/A | large |
~10 GB | 1x |
For English-only applications, the .en models tend to perform better, especially for the tiny.en and base.en models. We observed that the difference becomes less significant for the small.en and medium.en models.
Whisper’s performance varies widely depending on the language. The figure below shows a WER breakdown by languages of Fleurs dataset, using the large model. More WER and BLEU scores corresponding to the other models and datasets can be found in Appendix D in the paper.

License
The code and the model weights of Whisper are released under the MIT License. See LICENSE for further details.