





Readme
Stochastic Image-to-Video Synthesis using cINNs
Official PyTorch implementation of Stochastic Image-to-Video Synthesis using cINNs accepted to CVPR2021.
Arxiv | Project Page | Supplemental | Pretrained Models | BibTeX
Michael Dorkenwald,
Timo Milbich,
Andreas Blattmann,
Robin Rombach,
Kosta Derpanis*,
Björn Ommer*,
CVPR 2021
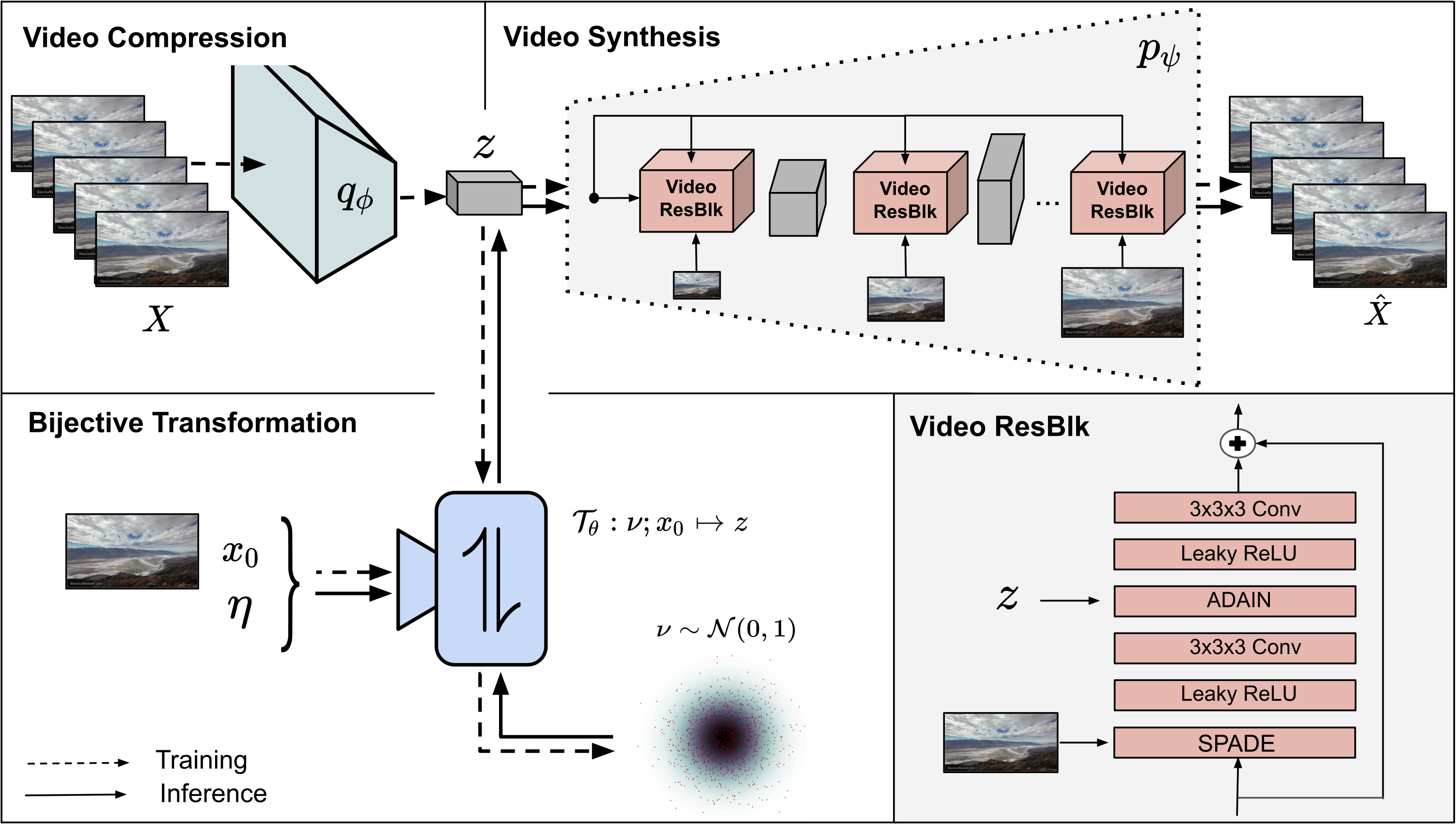
tl;dr We present a framework for both stochastic and controlled image-to-video synthesis. We bridge the gap between the image and video domain using conditional invertible neural networks and account for the inherent ambiguity with a learned, dedicated scene dynamics representation.
Shout-outs
Thanks to everyone who makes their code and models available. In particular,
- The decoder architecture is inspired by SPADE
- The great work and code of Stochastic Latent Residual Video Prediction SRVP
- The 3D encoder and discriminator are based on 3D-Resnet and spatial discriminator is adapted from PatchGAN
- The metrics which were used LPIPS PyTorch FID FVD
BibTeX
@InProceedings{Dorkenwald_2021_CVPR,
author = {Dorkenwald, Michael and Milbich, Timo and Blattmann, Andreas and Rombach, Robin and Derpanis, Konstantinos G. and Ommer, Bjorn},
title = {Stochastic Image-to-Video Synthesis Using cINNs},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2021},
pages = {3742-3753}
}
Model created