

Readme
Model by Lyumin Zhang
Usage
Input an image, and prompt the model to generate an image as you would for Stable Diffusion. Openpose will detect the pose for you.
Model Description
This model is ControlNet adapting Stable Diffusion to use a pose map of humans in an input image in addition to a text input to generate an output image.
ControlNet is a neural network structure which allows control of pretrained large diffusion models to support additional input conditions beyond prompts. The ControlNet learns task-specific conditions in an end-to-end way, and the learning is robust even when the training dataset is small (< 50k samples). Moreover, training a ControlNet is as fast as fine-tuning a diffusion model, and the model can be trained on a personal device. Alternatively, if powerful computation clusters are available, the model can scale to large amounts of training data (millions to billions of rows). Large diffusion models like Stable Diffusion can be augmented with ControlNets to enable conditional inputs like edge maps, segmentation maps, keypoints, etc.
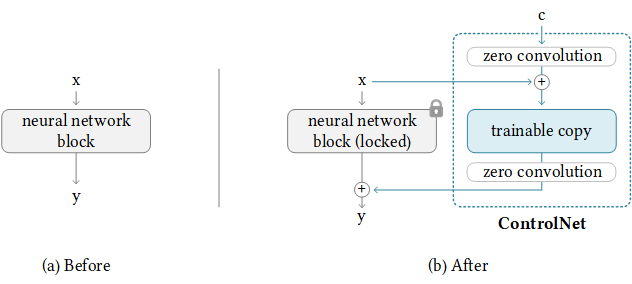
Original model & code on GitHub
Other ControlNets
There are many different ways to use a ControlNet to modify the output of Stable Diffusion. Here are a few different options, all of which use an input image in addition to a prompt to generate an output. The methods process the input in different ways; try them out to see which works best for a given application.
ControlNet for generating images from drawings Scribble: https://replicate.com/jagilley/controlnet-scribble
ControlNets for generating humans based on input image Human Pose Detection: https://replicate.com/jagilley/controlnet-pose
ControlNets for preserving general qualities about an input image Edge detection: https://replicate.com/jagilley/controlnet-canny HED maps: https://replicate.com/jagilley/controlnet-hed Depth map: https://replicate.com/jagilley/controlnet-depth2img Hough line detection: https://replicate.com/jagilley/controlnet-hough Normal map: https://replicate.com/jagilley/controlnet-normal
Citation
@misc{https://doi.org/10.48550/arxiv.2302.05543,
doi = {10.48550/ARXIV.2302.05543},
url = {https://arxiv.org/abs/2302.05543},
author = {Zhang, Lvmin and Agrawala, Maneesh},
keywords = {Computer Vision and Pattern Recognition (cs.CV), Artificial Intelligence (cs.AI), Graphics (cs.GR), Human-Computer Interaction (cs.HC), Multimedia (cs.MM), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Adding Conditional Control to Text-to-Image Diffusion Models},
publisher = {arXiv},
year = {2023},
copyright = {arXiv.org perpetual, non-exclusive license}
}