Which image editing model should I use?
Replicate Playground
In the past few weeks, nearly every major AI lab has released an image editing model. The first was FLUX.1 Kontext from Black Forest Labs in May, which stood out for style transformations and simple image edits. Since then, we’ve seen a wave of models, each strong in its own way.
With so many options, it can be hard to figure out which one works best for your needs. In this post, we’re putting them head to head and evaluating each across a range of image editing tasks. By the end, you should have a clear sense of which one fits your workflow.
To start, here’s an overview of the cost and average inference time for each model we’re evaluating.
| Model | Lab | Price per Image | Inference Time |
|---|---|---|---|
| FLUX.1 Kontext [dev] | Black Forest Labs | $0.025 | 1.7 seconds |
| FLUX.1 Kontext [pro] | Black Forest Labs | $0.04 | 4.4 seconds |
| FLUX.1 Kontext [max] | Black Forest Labs | $0.08 | 4.9 seconds |
| Qwen Image Edit | Alibaba | $0.03 | 2.9 seconds |
| Qwen Image Edit Plus | Alibaba | $0.03 | 16 seconds |
| Nano Banana | $0.039 | 10 seconds | |
| SeedEdit 3.0 | ByteDance | $0.03 | 13 seconds |
| Seedream 4 | ByteDance | $0.03 | 14 seconds |
| GPT Image 1 | OpenAI | $0.01-$0.25 | 40 seconds |
The cheapest is GPT-image-1 from OpenAI which starts $0.01 per image, but it has the longest generation time (around 40 seconds). FLUX.1 Kontext [dev] (optimized by Pruna AI) is the fastest at 1.9s per generation and is also one of the cheaper options, but there is, of course, a trade off with image editing quality for hyper-optimized models.
For our tests, we’re evaluating the base model from each AI lab. Specifically, for FLUX.1 Kontext and Qwen, we’ll only show results from FLUX.1 Kontext [pro] and Qwen Image Edit.
Let’s put these models up to the test.
Object removal
The first task we’re looking at is object removal. This is a basic task that one should be able to do in Photoshop. In particular, if we remove objects that are in front of other elements of an image, how well is the model able to interpolate what is behind the removed object?
We tested this with an image of the Golden Gate Bridge.

Here’s how different image editing models perform when tasked with removing the bridge from the image:
Remove the bridge






Winners: SeedEdit 3.0 and Qwen Image Edit
Loser: FLUX.1 Kontext [pro]
The model that struggled the most was FLUX.1 Kontext [pro], which left the two towers in place. Nano Banana removed the entire bridge but failed to keep the background hills consistent. GPT-image-1 smoothed out the building in the bottom left corner but did successfully remove the bridge. The other models handled the task well.
Front view comparison
Another common image editing task is changing the viewing angles of the object in the image.

Let’s see which image models can give us the front-facing view of this character and her cat while maintaining character consistency.
Show the front view of the woman and the cat






Winner: Qwen Image Edit
Loser: SeedEdit 3.0
Only GPT-image-1 and Qwen Image Edit gave us the head-on view we were looking for, albeit GPT-image-1 did not seem to maintain character consistency. FLUX.1 Kontext [pro] and Nano Banana did fairly well at showing a front view of our character; both of them even managed to preserve the tattoo on the character’s arm. The ByteDance models struggled the most — SeedEdit did not turn the character at all and Seedream did not preserve our character.
Background editing
Background editing requires models to understand object boundaries and generate coherent environments. Here’s how different image editing models perform when tasked with editing or replacing backgrounds:

Make the background a jungle






Winner: SeedEdit 3.0 and Seedream 4
Loser: Nano Banana
Nano Banana performs the worst here, cutting out a small piece of the character and placing it on a generic jungle background. The ByteDance Seed models do the best, with strong character consistency, natural lighting, and believable placement. FLUX.1 Kontext [pro] comes close but doesn’t fully land it, while GPT-image-1 and Qwen generate characters that look noticeably different. Qwen also smooths out the textures, making the result feel less detailed.
Text editing
Text editing within images represents one of the most challenging and impressive capabilities of modern image editing models. The ability to understand, modify, and generate text while maintaining proper typography, perspective, and lighting is a remarkable technical achievement that was nearly impossible even a year ago.
In this evaluation, we are looking for which image models preserve the original font of the text and maintain the physical elements of the signage (i.e. sign texture/color, placement of the surrounding words, etc.)
Let’s see if we change the word “seven” to “eight” in the following image:

Change ‘seven’ to ‘eight’






Winners: FLUX.1 Kontext [pro] and Nano Banana
Losers: GPT-image-1 and Seedream 4
The favorites here are FLUX.1 Kontext [pro] and Nano Banana which were able to introduce the word “eight” naturally with consistent type and placement. Even the paper-like texture of the note is preserved in these edits. With Seededit and Qwen, the word “eight” is sticking out and clearly looks edited in. GPT-image-1 looks visually appealing but did not maintain the original note. Seedream’s typography looks fine but it did produce an artifact in the “to:” section of the note.
Style transfer
Style transfer showcases each model’s ability to understand artistic styles and apply them while preserving the original image’s content and composition. Some models excel at capturing fine artistic details while others focus on maintaining structural integrity.
Here’s how these models handle style transfer tasks, specifically converting images to an oil painting style:

Transform this into an oil painting






Winner: Nano Banana
Loser: FLUX.1 Kontext [pro]
This task yielded interesting results across all the models as each have different ideas on what an oil painting should look like. Nano Banana and Seedream look closest to the original image, offering an air-brushed, well-blended look. GPT-image also has the short strokes but also has its signature yellow tint. Qwen and FLUX.1 Kontext [pro] are quite similar, with more of a painterly, unblended look (yet both of these also have the yellow tint).
Takeaways
After evaluating these six image editing models across five distinct tasks — object removal, perspective transformation, background editing, text manipulation, and style transfer — there are some clear winners that can guide your choice based on specific needs and priorities.
- Object removal: Most models succeeded, but FLUX.1 Kontext [pro] struggled
- Perspective changes: GPT Image 1 and Qwen Image Edit best achieved the requested front-facing views with character consistency
- Background editing: The ByteDance models (SeedEdit and Seedream) clearly dominated with natural integration of the character with the jungle landscape
- Text editing: FLUX.1 Kontext and Nano Banana preserved typography and texture most effectively
- Style transfer: Nano Banana and Seedream maintained closest resemblance to originals while achieving nice artistic effects
Keep in mind that these were all surface-level experimentations and the above recommendations might not be enough to justify your choice of model.
Need to experiment some more? Check out Replicate’s playground to parallely test and compare image editing models (or any model):
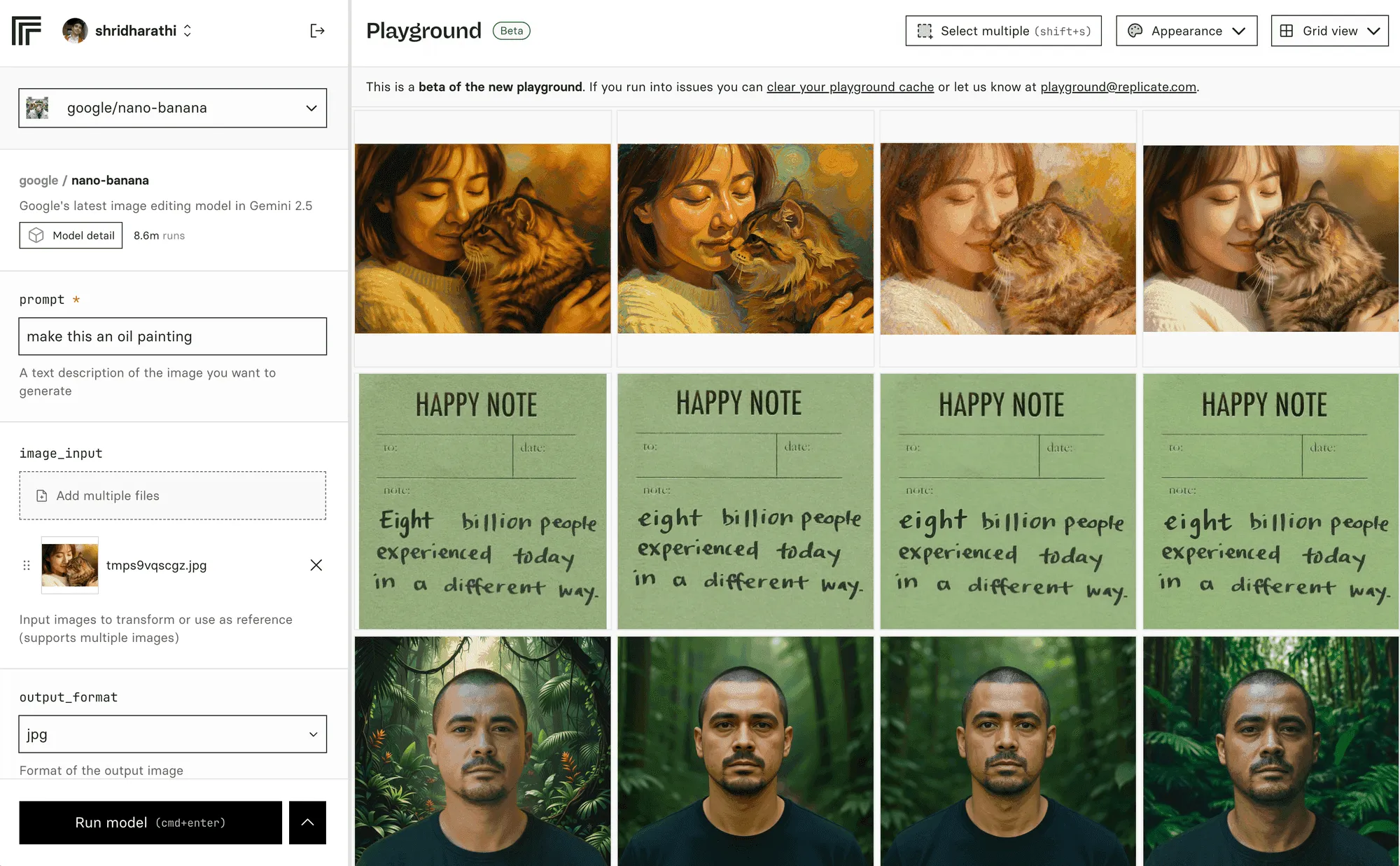
It’s what we used to create this post!
As always, chat with us on Discord and follow us on X to keep up with the latest.