
Readme

Introduction
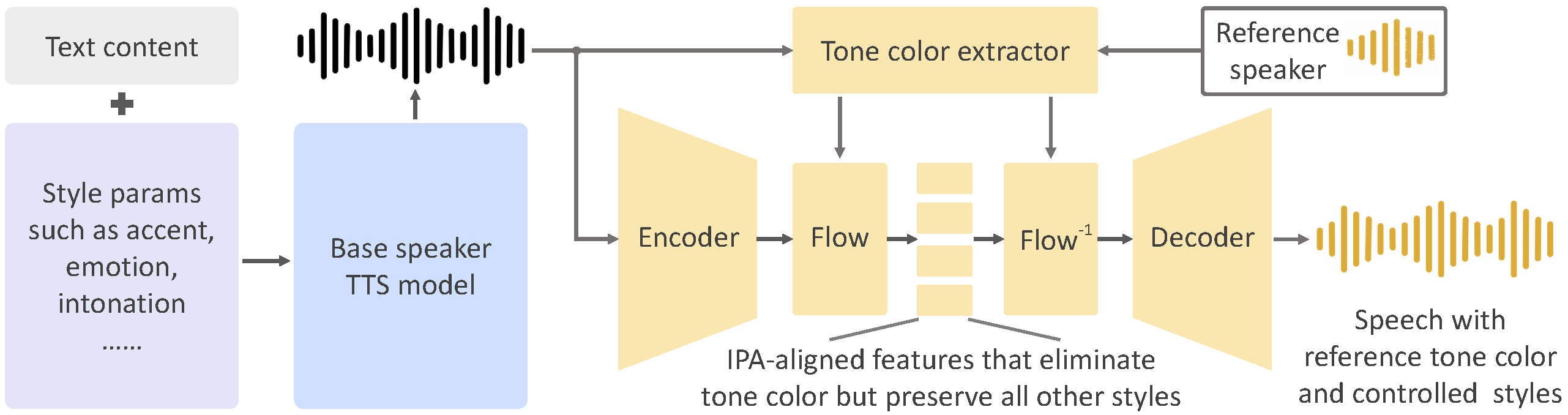
OpenVoice V1
As we detailed in our paper and website, the advantages of OpenVoice are three-fold:
1. Accurate Tone Color Cloning. OpenVoice can accurately clone the reference tone color and generate speech in multiple languages and accents.
2. Flexible Voice Style Control. OpenVoice enables granular control over voice styles, such as emotion and accent, as well as other style parameters including rhythm, pauses, and intonation.
3. Zero-shot Cross-lingual Voice Cloning. Neither of the language of the generated speech nor the language of the reference speech needs to be presented in the massive-speaker multi-lingual training dataset.
OpenVoice V2
In April 2024, we released OpenVoice V2, which includes all features in V1 and has:
1. Better Audio Quality. OpenVoice V2 adopts a different training strategy that delivers better audio quality.
2. Native Multi-lingual Support. English, Spanish, French, Chinese, Japanese and Korean are natively supported in OpenVoice V2.
3. Free Commercial Use. Starting from April 2024, both V2 and V1 are released under MIT License. Free for commercial use.
OpenVoice has been powering the instant voice cloning capability of myshell.ai since May 2023. Until Nov 2023, the voice cloning model has been used tens of millions of times by users worldwide, and witnessed the explosive user growth on the platform.
Citation
@article{qin2023openvoice,
title={OpenVoice: Versatile Instant Voice Cloning},
author={Qin, Zengyi and Zhao, Wenliang and Yu, Xumin and Sun, Xin},
journal={arXiv preprint arXiv:2312.01479},
year={2023}
}
Acknowledgements
This implementation is based on several excellent projects, TTS, VITS, and VITS2. Thanks for their awesome work!