OCR to extract text from images
These models perform optical character recognition, extracting text from images. They can help digitize text from scanned documents, photos, and other visual media.
Best for image to text extraction: abiruyt/text-extract-ocr
For most OCR tasks, we recommend the abiruyt/text-extract-ocr model. This versatile tool makes it simple to extract plain text from a wide variety of images.
Best for document extraction: cuuupid/marker
To get clean markdown or JSON from PDF, epub, or other document formats, use Marker. It's a pipeline of models that supports all languages, removes headers and footers, formats equations and code blocks, and more. It can also OCR text from PDFs saved in image format.
Other utilities
Some other useful models for your text extraction pipeline:
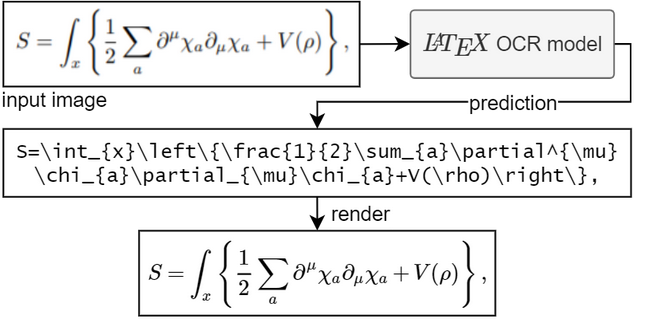
- mickeybeurskens/latex-ocr specializes in recognizing LaTeX equations from images and converting them into usable LaTeX code
- cjwbw/docentr cleans up degraded images, removing bleed-through, artifacts and smudging
- willywongi/donut extracts structured JSON data from receipts
- pbevan1/llama-3.1-8b-ocr-correction fixes OCR errors in digitized text by reconstructing the original content using LLaMA 3.1
Featured models

Recommended Models
Frequently asked questions
Which models are the fastest?
If you want to extract text from images as quickly as possible, abiruyt/text-extract-ocr is a great starting point. It handles a wide range of image types—from clean scans to photos—and delivers text output in seconds.
For document-level extraction, cuuupid/marker is optimized for batch processing and converts files rapidly to structured formats like Markdown or JSON.
Which models offer the best balance of cost and quality?
abiruyt/text-extract-ocr provides a strong balance between speed, accuracy, and simplicity. It’s a reliable default for most OCR pipelines.
If you need higher precision and structured results (like clean markdown output or proper formatting of code blocks), cuuupid/marker is a step up in quality and formatting control.
What works best for digitizing documents and PDFs?
When you’re working with scanned PDFs, books, or reports, cuuupid/marker and lucataco/deepseek-ocr excel. They handle multi-column layouts, headings, and embedded media while removing unwanted artifacts like headers and footers.
These models also support non-Latin scripts and preserve structured information, making them suitable for academic or archival work.
What works best for extracting equations or structured content?
If your goal is to recover LaTeX or math expressions, mickeybeurskens/latex-ocr specializes in converting equation images directly into LaTeX code.
For receipts, forms, or invoices, willywongi/donut extracts structured JSON with fields like item names, prices, and totals—perfect for automation or data pipelines.
What's the difference between key subtypes or approaches in this collection?
OCR models here generally fall into two groups:
- Plain-text OCR models (like abiruyt/text-extract-ocr): Designed for quick and simple text extraction without formatting.
- Document-understanding models (like cuuupid/marker or willywongi/donut): Combine OCR with layout analysis and structured output, ideal for formatted documents or multi-language data.
If you need layout or structure, use a document-understanding model; if you only need raw text, use a plain-text OCR model.
What kinds of outputs can I expect from these models?
Most models output plain text or structured text files (Markdown, JSON, or LaTeX).
For instance, cuuupid/marker outputs Markdown or JSON with headings and code blocks preserved, while willywongi/donut returns structured data fields extracted from images.
How can I self-host or push a model to Replicate?
Many OCR models are open source and can be self-hosted with Cog or Docker.
To publish your own version, include a replicate.yaml file defining inputs (like image or pdf_file) and outputs (text or json_output), then push it to your Replicate account to run on managed GPUs.
Can I use these models for commercial work?
Yes—most OCR models are approved for commercial use. Always review the License section on the model’s page, since some models (especially those trained on academic datasets) may restrict redistribution or require attribution.
How do I use or run these models?
Go to a model’s page on Replicate, upload your image or PDF, and run it.
For example, abiruyt/text-extract-ocr will return plain text immediately, while cuuupid/marker lets you choose between output types like Markdown or JSON. Some models also support batch uploads for larger jobs.
What should I know before running a job in this collection?
- Higher-quality inputs yield better results—avoid blurry or low-contrast images.
- If text is rotated or partially visible, pre-process the image (e.g., deskew or crop) before running OCR.
- For handwritten or stylized text, expect occasional errors; correction models like pbevan1/llama-3.1-8b-ocr-correction can help refine outputs.
- When working with sensitive documents, ensure your data handling complies with privacy and security policies.
Any other collection-specific tips or considerations?
- For large-scale document digitization, combine cuuupid/marker for formatting and abiruyt/text-extract-ocr for bulk processing.
- If your workflow includes equations or code, run mickeybeurskens/latex-ocr or willywongi/donut in parallel to capture structured content.
- To enhance degraded scans before extraction, try cjwbw/docentr for image cleanup.
- Always verify OCR outputs—models can misread stylized fonts, small print, or heavily compressed images.