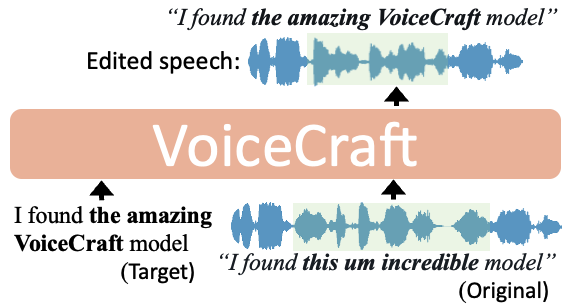
Generate speech
Generate natural-sounding speech from text. Clone voices, control emotions, and produce audio in dozens of languages.
Models we recommend
Most expressive: Inworld Realtime TTS 2.0
Inworld Realtime TTS 2.0 is the most expressive TTS model on Replicate. Direct any voice with bracketed natural-language cues like [say excitedly], [whisper in a hushed style], or [speak as if barely holding back rage] — no preset list, just write your directions like you're directing a voice actor. Real-time latency, 15 production languages plus experimental support for 90+ more, and inline non-verbals like [laugh], [sigh], and [breathe].
Best quality: MiniMax Speech 2.8 HD
MiniMax Speech 2.8 HD ranks #1 on TTS benchmarks, outperforming both OpenAI and ElevenLabs in blind evaluations. Studio-grade voice synthesis with 17+ preset voices, emotion control, voice cloning from just 5 seconds of audio, and support for 32+ languages. The best choice for voiceovers, audiobooks, and polished content.
Audio tags and effects: ElevenLabs v3
ElevenLabs v3 supports audio tags like [excited], [whispers], and [sighs] for fine-grained delivery control. Supports 70+ languages and 26 voices. Great for film, audiobooks, and creative media when you want a curated set of expressive tags rather than free-form direction.
Style-prompted: Gemini 3.1 Flash TTS
Gemini 3.1 Flash TTS from Google gives you fine-grained control over delivery through inline tags and style prompting. Set a scene, define a character, and direct the performance — "you must hear the grin in the audio." 30 voices, 70+ languages, and natural-sounding output with rich expressiveness.
Best for real-time: MiniMax Speech 2.8 Turbo
MiniMax Speech 2.8 Turbo is optimized for low-latency applications like voice agents, chatbots, and interactive experiences. Supports 40+ languages with the same voice cloning and emotion control as the HD version.
Ultra-low latency: Inworld Realtime TTS 1.5 Mini
Inworld Realtime TTS 1.5 Mini achieves ~120ms latency — the fastest in this collection. Supports 15 languages with emotion markups and SSML break tags. Inworld Realtime TTS 1.5 Max trades a bit of speed for higher quality at <200ms latency.
For voice cloning: Chatterbox
Chatterbox from Resemble AI excels at voice cloning with emotional control — generate distinct character voices from just a few seconds of reference audio. Great for games, animations, and storytelling.
Multilingual: ElevenLabs v2 Multilingual
ElevenLabs v2 Multilingual generates speech in 29 languages while maintaining consistent voice quality across all of them. Good for localization workflows where the same voice needs to work in multiple languages.
Open source: Tortoise TTS
Tortoise TTS is an open-source option that produces high-quality speech. Slower than the commercial models but fully self-hostable.
Featured models

 google/gemini-3.1-flash-tts
google/gemini-3.1-flash-ttsGoogle's fast, expressive text-to-speech model with 30 voices and 70+ language support
Updated 1 month, 2 weeks ago
387.8K runs

Most expressive text-to-speech model from Inworld, with natural-language steering, real-time latency, and multilingual support across 100+ languages.
Updated 2 months, 4 weeks ago
36K runs

 minimax/speech-2.8-hd
minimax/speech-2.8-hdMinimax Speech 2.8 HD focuses on high-fidelity audio generation with features like studio-grade quality, flexible emotion control, multilingual support, and voice cloning capabilities
Updated 3 months, 1 week ago
181.7K runs
 minimax/speech-2.8-turbo
minimax/speech-2.8-turboMinimax Speech 2.8 Turbo: Turn text into natural, expressive speech with voice cloning, emotion control, and support for 40+ languages
Updated 3 months, 1 week ago
617.6K runs

Highest-quality realtime text-to-speech with <200ms latency, emotion control, and 15-language support
Updated 3 months, 2 weeks ago
174.6K runs

Ultra-fast, cost-efficient realtime text-to-speech with ~120ms latency and 15-language support
Updated 3 months, 2 weeks ago
129.4K runs

The fastest open source TTS model without sacrificing quality.
Updated 7 months, 2 weeks ago
606.8K runs

 elevenlabs/v3
elevenlabs/v3The most expressive Text to Speech model
Updated 9 months, 1 week ago
76.7K runs

Generate expressive, natural speech. Features unique emotion control, instant voice cloning from short audio, and built-in watermarking.
Updated 1 year, 1 month ago
411.5K runs
Recommended Models
Frequently asked questions
Which model should I start with?
For maximum expressiveness and control, try inworld/realtime-tts-2 — you can direct the voice with natural-language cues like [say excitedly] or [whisper in a hushed style]. For polished, studio-grade audio, minimax/speech-2.8-hd ranks #1 on benchmarks and supports 32+ languages with voice cloning and emotion control.
Which model is the most expressive?
inworld/realtime-tts-2 supports free-form natural-language steering — you write directions like you're directing a voice actor. For example: [overwhelmed with excitement and barely able to contain yourself] We just hit a million users. elevenlabs/v3 takes a different approach with curated audio tags like [excited], [whispers], and [sighs].
Which models are the fastest?
inworld/realtime-tts-1.5-mini achieves ~120ms latency — the fastest in this collection. inworld/realtime-tts-2 and minimax/speech-2.8-turbo are also designed for low-latency real-time use. Great for chatbots, voice agents, and interactive apps.
How do I clone a voice?
minimax/speech-2.8-hd and minimax/speech-2.8-turbo both support voice cloning from just 5 seconds of reference audio. resemble-ai/chatterbox is another option with emotional control, especially good for character voices in games and animation. The Inworld models also support custom cloned voice IDs created on the Inworld platform.
Which models support the most languages?
elevenlabs/v3 supports 70+ languages. inworld/realtime-tts-2 supports 15 production languages plus experimental support for 90+ more. minimax/speech-2.8-turbo and minimax/speech-2.8-hd support 40+ and 32+ languages respectively. elevenlabs/v2-multilingual supports 29 languages with consistent voice quality across all of them.
Can I control emotions in the speech?
Yes — most modern TTS models support emotion control, but they take different approaches. inworld/realtime-tts-2 lets you write free-form natural-language directions like [say sadly with deliberate pauses in a low voice]. elevenlabs/v3 uses curated audio tags. MiniMax models support presets like happy, sad, angry, fearful, and calm. The Inworld 1.5 models support emotion markups like [happy], [sad], plus non-verbal sounds like [laugh] and [sigh].
Is there an open-source option?
afiaka87/tortoise-tts is open-source and produces high-quality speech. It's slower than commercial models but can be self-hosted on your own hardware.
Can I use TTS models commercially?
Most models support commercial use. Some may include audio watermarking — check each model's license page for specifics, especially regarding voice cloning and redistribution.